SQL优化 MySQL版 - 单表优化及细节详讲
单表优化及细节详讲
作者 : Stanley 罗昊
【转载请注明出处和署名,谢谢!】
注:本文章需要MySQL数据库优化基础或观看前几篇文章,传送门:
B树索引详讲(初识SQL优化,认识索引):https://www.cnblogs.com/StanleyBlogs/p/10413349.html
B树索引进阶(索引分类、创建方式、删除索引、查看索引、SQL性能问题):https://www.cnblogs.com/StanleyBlogs/p/10416865.html
SQL执行计划于笛卡尔积(了解什么是SQL执行计划,优化原理):https://www.cnblogs.com/StanleyBlogs/p/10422202.html
Type详讲(理解优化级别):https://www.cnblogs.com/StanleyBlogs/p/10426385.html
Extra(理解最终优化概念):https://www.cnblogs.com/StanleyBlogs/p/10429969.html
优化准备
首先我们需要有一个数据库,bookdb,还要有一张数据表book,有以下字段,我们接下来将用以下这张表来做优化实例;
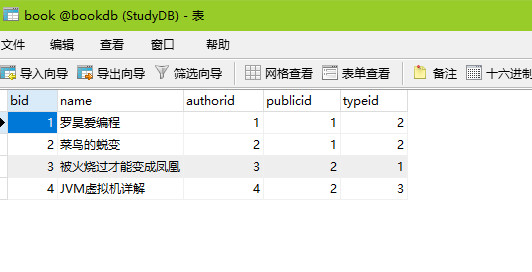
单表优化
此次教程不再使用可视化工具,因为效率太慢,我还是比较喜欢命令行操作;
下面我们需要编写以下条件的SQL语句:
查询authorid = 1并且 typeid为2或3的bid再根据typeid排序
SQL语句:select bid from book where typeid in (2,3) And authorid = 1 order by typeid desc;
我们执行这条SQL语句,然后在前面加上explatin查看sql执行计划:

我们可以清楚的看到,查询级别是ALL,并且Useing where回表查询了并且后面还有一个Using filesort表示创建临时表了,可见此条SQL语句是多么的恐怖,效率极低;
这个时候我们就来给它加个索引吧,毕竟都知道,加索引可以提高效率,那我们就来分析一下以上这个sql语句;
首先该语句里面有 bid typeid authorid这三个字段,那么接下来我将给它们创建一个复合索引:

索引名我起名为idx_bta代表它的顺序 b 代表 bid t 代表 typeid a 就代表authorid;
加上索引后,我们再执行一下,看看我们这条sql语句有没有被优化:

首先,我们可以看见,type级别被优化了一些,到了index了,也就是ALL的上一个级别,我在之前的文章也说过,最好优化到ref级别,可见我们现在这条SQL还是不够优化,并且 我们后面还有Using filesirt,但是出现了Using index,说明还是优化了一些,但是远远不够!
那么为什么呢?我明明加了索引,它居然还性能这么差?
原来,我们忽略了一点,就是SQL解析过程!
我在前几篇文章重点说过,编写过程,解析过程是不一样的:
编写过程:
select from join on where 条件 group by 分组 having过滤组 order by排序 limit限制查询个数
解析过程:
from on join where group by having select order by limit
以上就是mysql的解析过程,我们发现,跟我们编写的过程完全不一致!
也就是说,我们尽管bid在前面,typeid跟authorid在后面,但是它实际执行的时候却是先执行where(type、authorid),而不是select(bid);
但是我们索引顺序是怎么建的?
是 b t a 的顺序(bid typeid authorid),既然where我现在非要先让bid先执行,很显然不满足最佳左前缀,就是从左向右依次执行,我现在的索引并没有满足,因为我现在却让最右边的先执行了(bid);
所以,我们需要改变一下索引的顺序,既然先解析where,我就让where后面的俩字段放在前面(typeid authorid),把select放在后面(bid);
根据SQL实际解析的顺序,调整索引的顺序;
在建立这个索引之前,我们务必删掉没用的索引!

删掉后,我们把索引的顺序改变一下,之前是 b t a 现在我改成 t a b(typeid authorid bid);

添加索引后,我并且查询索引,发现创建成功了,我们再运行一下试试,这次我改变了索引顺序,顺序按照解析顺序排列,看看这次的效果如何:

我们发现,type等级仍然是index,因为没有创建临时表了也就是额外的查询,性能明显提升了,但是我们的type等级仍是index,确实还没有达到我们想要的ref标准,接下来我们继续优化;
我们现在开始重点优化索引级别,很显然,我们的索引级别是index,距离ref还有点距离;
再次优化
system>const>eq_ref>ref>range>index>ALL
很明显啊,我们现在的这条sql才到index级别,我之前说过,最好达到ref或range级别;
我们来把之前的SQL拿过来:
select bid from book where typeid in (2,3) And authorid = 1 order by typeid desc;
我现在将where条件后面这两个字段换一个顺序,为啥换顺序呢,看这个in
我之前讲过范围查询,in是有可能导致索引失效的,从而转为无索引;
我现在思路是,如果in失效了或typeid失效了,那你authorid也就跟着一起失效了,为什么呢?
我们来看一下索引顺序,我们是先typeid 后 authorid,如果你typeid都没了,那么authorid也可能也受干扰了,所以我把它顺序换换;
alter table book add index idx_atb(authorid,typeid,bid);
我现在让它先authorid后typeid,那如果先a 后 t 那即是你 t 失效了,无所谓啊,我先a,a你也用了,这是个思路;
既然typeid会失效,那我们改变一下where后面的顺序吧,既然你可能会失效,就把它往后放,别影响别人:
explain select bid from book where authorid = 1 And typeid in (2,3) order by typeid desc;
务必也把索引顺序也更改一下!
alter table book add index idx_atb(authorid,typeid,bid);
我们改变索引顺序跟SQL语句where后面的顺序后再执行:

我们再查看type级别会发现已经达到了fef级别,并且也有Using index,但是还有Using where
因为我typeid虽然也有索引,但是我使用了in,就索引失效了,就跟typeid没有索引一样,这样就造成了又需要回原表查了,所以尽量避免使用in;
小结:之所以这条SQL语句能达到了ref,是因为我满足了最佳左前缀,跟处理了索引失效的问题,既然你要失效,我就不要让你影响后面的字段,我就把你往后排,尽管你失效了,你不影响前面的,所以我把SQL语句where后面的两个字段换了位置;
索引需要逐步优化,要实时查询sql执行计划,采取逐步优化措施;
补充
刚刚在上方我把SQL语句字段where后面的字段调换了位置,并且索引也跟着调换了,其实经过测试,其实SQL语句无需调换,仅需调换索引位置即可:

今日感悟:
在你看不见的地方,总有你想不到的辛酸;
SQL优化 MySQL版 - 单表优化及细节详讲的更多相关文章
- SQL优化 MySQL版 - 多表优化及细节详讲
多表优化及细节详讲 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 注:本文章需要MySQL数据库优化基础或观看前几篇文章,传送门: B树索引详讲(初识SQL优化,认识索引):htt ...
- MySQL索引优化(索引单表优化案例)
1.单表查询优化 建表SQL CREATE TABLE IF NOT EXISTS `article` ( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUT ...
- 50个SQL语句(MySQL版) 建表 插入数据
本学期正在学习数据库,前段时间老师让我们做一下50个经典SQL语句,当时做的比较快,有一些也是百度的,自我感觉理解的不是很透彻. 所以从本篇随笔开始,我将进行50个经典SQL语句的复盘,加深理解. 答 ...
- SQL优化 MySQL版 - 索引分类、创建方式、删除索引、查看索引、SQL性能问题
SQL优化 MySQL版 - 索引分类.创建方式.删除索引.查看索引.SQL性能问题 作者 Stanley 罗昊 [转载请注明出处和署名,谢谢!] 索引分类 单值索引 单的意思就是单列的值,比如说有 ...
- SQL优化 MySQL版 - B树索引详讲
SQL优化 MySQL版 - -B树索引详讲 作者:Stanley 罗昊 [转载请注明出处和署名,谢谢!] 为什么要进行SQL优化呢?很显然,当我们去写sql语句时: 1会发现性能低 2.执行时间太 ...
- SQL优化 MySQL版 -分析explain SQL执行计划与笛卡尔积
SQL优化 MySQL版 -分析explain SQL执行计划 作者 Stanley 罗昊 [转载请注明出处和署名,谢谢!] 首先我们先创建一个数据库,数据库中分别写三张表来存储数据; course: ...
- MySQL 性能优化系列之一 单表预处理
MySQL 性能优化系列之一 单表预处理 背景介绍 我们经常在写多表关联的SQL时,会想到 left jion(左关联),right jion(右关联),inner jion(内关联)等. 但是,当表 ...
- Mysql大数据表优化处理
原文链接: https://segmentfault.com/a/1190000006158186 当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表 ...
- Mariadb/MySQL数据库单表查询基本操作及DML语句
Mariadb/MySQL数据库单表查询基本操作及DML语句 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一数据库及表相关概述 1>.数据库操作 创建数据库: CREATE ...
随机推荐
- in_flight_pqueue.go
// right child } if (*pq)[j].pri >= (*pq)[i].pri { break } ...
- 将函数声明为Static的作用
表示静态函数,它为所有类共有的.调用该函数直接使用类名加上修饰符,如:Windows win;Windows::W_SIZE();而不是:win.W_SIZE();静态函数只能处理静态数据成员,不能处 ...
- i春秋------Misc更新
今天早上起来很开森!因为今天要打比赛了(2018年3月安恒杯线上赛),等到比赛开始得时候,发现自己登陆不上去 想了很久发现自己只是预约了比赛,并没有报名(QAQ ),心疼一下傻傻的自己.现在开始工作: ...
- JDK10安装配置详解
JDK10安装配置详解 1. 下载jdk10 1.1 官网下载jdk7的软件包: 地址:http://www.oracle.com/technetwork/java/javase/dow ...
- 我的Python之旅第四天
一 名称空间.作用域.取值顺序 1 名称空间 当程序运行时,代码从上至下依次执行,它会将变量与值得关系存储在一个空间中,这个空间就叫做名称空间,也叫命名空间.全局名称空间. 当程序遇到函数时,他会将函 ...
- 分布式团队中沟通引发的问题, itest 解决之道
导读: 从问题场景和 itest 优雅解决办法及示例2部分来阐述 1.问题场景: 研发团队是分散在几地的分布式团队,经常会因沟通引来一些问题.如下三图是开发觉得测试进度太慢,一番对话之后, 接下来他们 ...
- 安卓开发笔记(二十六):Splash实现首页快速开屏功能
我们在进行安卓开发的时候,首页开有两种方式,一种是利用handler将一个活动进行延时,时间到达之后软件则会跳转到第二个活动当中.而另一种方法则是更加常用的方法,利用splash实现首页的快速开屏,这 ...
- MIUI目前为止最简单安装谷歌服务框架教程
安装谷歌服务框架方法有很多,比如用第三方 rec卡刷gapps包.用第三方工具安装......然而这些对于新手来说还是比较难的! 我今天说的方法可以说是最简单的:1.不需要修改文件:2.不需要借助第三 ...
- Vue 进阶之路(四)
之前的文章我们已经对 vue 有了初步认识,这篇文章我们通过一个例子说一下 vue 的样式绑定. 现在我们想要是想这样一个需求,页面上有个单词,当我们点击它的时候颜色变为红色,再点击一次变为原来的颜色 ...
- 【重学计算机】操作系统D3章:存储管理
1. 存储管理的基本概念 逻辑地址:用户地址,从零开始编号 一维逻辑地址:(地址) 二维逻辑地址:(段号: 段内地址) 主存储器的复用方式 按分区:主存划分为多个固定/可变分区,一个程序占一个分区 按 ...