Go实现海量日志收集系统(二)
一篇文章主要是关于整体架构以及用到的软件的一些介绍,这一篇文章是对各个软件的使用介绍,当然这里主要是关于架构中我们agent的实现用到的内容
关于zookeeper+kafka
我们需要先把两者启动,先启动zookeeper,再启动kafka
启动ZooKeeper:./bin/zkServer.sh start
启动kafka:./bin/kafka-server-start.sh ./config/server.properties
操作kafka需要安装一个包:go get github.com/Shopify/sarama
写一个简单的代码,通过go调用往kafka里扔数据:
package main import (
"github.com/Shopify/sarama"
"fmt"
) func main() {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
msg := &sarama.ProducerMessage{}
msg.Topic = "nginx_log"
msg.Value = sarama.StringEncoder("this is a good test,my message is zhaofan")
client,err := sarama.NewSyncProducer([]string{"192.168.0.118:9092"},config)
if err != nil{
fmt.Println("producer close err:",err)
return
}
defer client.Close() pid,offset,err := client.SendMessage(msg)
if err != nil{
fmt.Println("send message failed,",err)
return
}
fmt.Printf("pid:%v offset:%v\n",pid,offset)
}
config.Producer.RequiredAcks = sarama.WaitForAll 这里表示是在给kafka扔数据的时候是否需要确认收到kafka的ack消息
msg.Topic = "nginx_log" 因为kafka是一个分布式系统,假如我们要读的是nginx日志,apache日志,我们可以根据topic做区分,同时也是我们也可以有不同的分区
我们将上述代码执行一下,就会往kafka中扔一条消息,可以通过kakfa中自带的消费者命令查看:
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic nginx_log --from-beginning

我们可以将最后的代码稍微更改一下,更改为循环发送:
for{
pid,offset,err := client.SendMessage(msg)
if err != nil{
fmt.Println("send message failed,",err)
return
}
fmt.Printf("pid:%v offset:%v\n",pid,offset)
time.Sleep(2*time.Second)
}
这样当我们再次执行的程序的时候,我们可以看到客户端在不停的消费到数据:
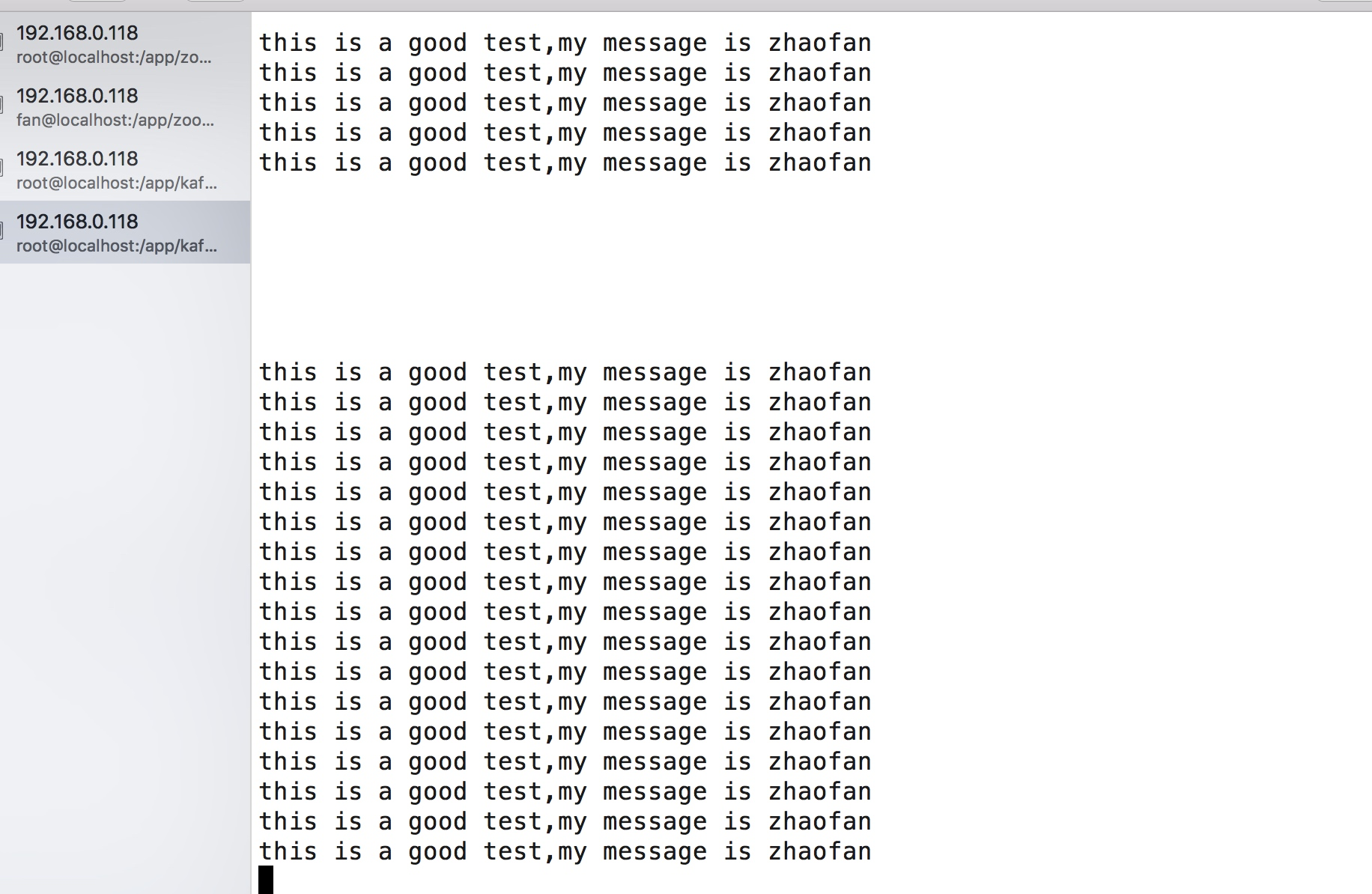
这样我们就实现一个kakfa的生产者的简单的demo
接下来我们还需要知道一个工具的使用tailf
tailf
我们的agent需要读日志目录下的日志文件,而日志文件是不停的增加并且切换文件的,所以我们就需要借助于tailf这个包来读文件,当然这里的tailf和linux里的tail -f命令虽然不同,但是效果是差不多的,都是为了获取日志文件新增加的内容。
而我们的客户端非常重要的一个地方就是要读日志文件并且将读到的日志文件推送到kafka
这里需要我们下载一个包:go get github.com/hpcloud/tail
我们通过下面一个例子对这个包进行一个基本的使用,更详细的api说明看:https://godoc.org/github.com/hpcloud/tail
package main import (
"github.com/hpcloud/tail"
"fmt"
"time"
) func main() {
filename := "/Users/zhaofan/go_project/src/go_dev/13/tailf/my.log"
tails,err := tail.TailFile(filename,tail.Config{
ReOpen:true,
Follow:true,
Location:&tail.SeekInfo{Offset:0,Whence:2},
MustExist:false,
Poll:true,
}) if err !=nil{
fmt.Println("tail file err:",err)
return
} var msg *tail.Line
var ok bool
for true{
msg,ok = <-tails.Lines
if !ok{
fmt.Printf("tail file close reopen,filenam:%s\n",tails,filename)
time.Sleep(100*time.Millisecond)
continue
}
fmt.Println("msg:",msg.Text)
}
}
最终实现的效果是当你文件里面添加内容后,就可以不断的读取文件中的内容
日志库的使用
这里是通过beego的日志库实现的,beego的日志库是可以单独拿出来用的,还是非常方便的,使用例子如下:
package main import (
"github.com/astaxie/beego/logs"
"encoding/json"
"fmt"
) func main() {
config := make(map[string]interface{})
config["filename"] = "/Users/zhaofan/go_project/src/go_dev/13/log/logcollect.log"
config["level"] = logs.LevelTrace
configStr,err := json.Marshal(config)
if err != nil{
fmt.Println("marshal failed,err:",err)
return
}
logs.SetLogger(logs.AdapterFile,string(configStr))
logs.Debug("this is a debug,my name is %s","stu01")
logs.Info("this is a info,my name is %s","stu02")
logs.Trace("this is trace my name is %s","stu03")
logs.Warn("this is a warn my name is %s","stu04")
}
简单版本logagent的实现
这里主要是先实现核心的功能,后续再做优化和改进,主要实现能够根据配置文件中配置的日志路径去读取日志并将读取的实时推送到kafka消息队列中
关于logagent的主要结构如下:
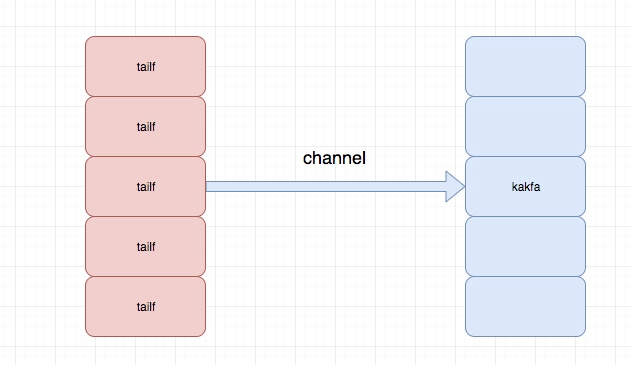
程序目录结构为:
├── conf
│ └── app.conf
├── config.go
├── kafka.go
├── logs
│ └── logcollect.log
├── main.go
└── server.go
app.conf :配置文件
config.go:用于初始化读取配置文件中的内容,这里的配置文件加载是通过之前自己实现的配置文件热加载包处理的,博客地址:http://www.cnblogs.com/zhaof/p/8593204.html
logcollect.log:日志文件
kafka.go:对kafka的操作,包括初始化kafka连接,以及给kafka发送消息
server.go:主要是tail 的相关操作,用于去读日志文件并将内容放到channel中
所以这里我们主要的代码逻辑或者重要的代码逻辑就是kafka.go 以及server.go
kafka.go代码内容为:
// 这里主要是kafak的相关操作,包括了kafka的初始化,以及发送消息的操作
package main import (
"github.com/Shopify/sarama"
"github.com/astaxie/beego/logs"
) var (
client sarama.SyncProducer
kafkaSender *KafkaSender
) type KafkaSender struct {
client sarama.SyncProducer
lineChan chan string
} // 初始化kafka
func NewKafkaSender(kafkaAddr string)(kafka *KafkaSender,err error){
kafka = &KafkaSender{
lineChan:make(chan string,100000),
}
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true client,err := sarama.NewSyncProducer([]string{kafkaAddr},config)
if err != nil{
logs.Error("init kafka client failed,err:%v\n",err)
return
}
kafka.client = client
for i:=0;i<appConfig.KafkaThreadNum;i++{
// 根据配置文件循环开启线程去发消息到kafka
go kafka.sendToKafka()
}
return
} func initKafka()(err error){
kafkaSender,err = NewKafkaSender(appConfig.kafkaAddr)
return
} func (k *KafkaSender) sendToKafka(){
//从channel中读取日志内容放到kafka消息队列中
for v := range k.lineChan{
msg := &sarama.ProducerMessage{}
msg.Topic = "nginx_log"
msg.Value = sarama.StringEncoder(v)
_,_,err := k.client.SendMessage(msg)
if err != nil{
logs.Error("send message to kafka failed,err:%v",err)
}
}
} func (k *KafkaSender) addMessage(line string)(err error){
//我们通过tailf读取的日志文件内容先放到channel里面
k.lineChan <- line
return
}
server.go的代码为:
package main import (
"github.com/hpcloud/tail"
"fmt"
"sync"
"github.com/astaxie/beego/logs"
"strings"
) type TailMgr struct {
//因为我们的agent可能是读取多个日志文件,这里通过存储为一个map
tailObjMap map[string]*TailObj
lock sync.Mutex
} type TailObj struct {
//这里是每个读取日志文件的对象
tail *tail.Tail
offset int64 //记录当前位置
filename string
} var tailMgr *TailMgr
var waitGroup sync.WaitGroup func NewTailMgr()(*TailMgr){
tailMgr = &TailMgr{
tailObjMap:make(map[string]*TailObj,16),
}
return tailMgr
} func (t *TailMgr) AddLogFile(filename string)(err error){
t.lock.Lock()
defer t.lock.Unlock()
_,ok := t.tailObjMap[filename]
if ok{
err = fmt.Errorf("duplicate filename:%s\n",filename)
return
}
tail,err := tail.TailFile(filename,tail.Config{
ReOpen:true,
Follow:true,
Location:&tail.SeekInfo{Offset:0,Whence:2},
MustExist:false,
Poll:true,
}) tailobj := &TailObj{
filename:filename,
offset:0,
tail:tail,
}
t.tailObjMap[filename] = tailobj
return
} func (t *TailMgr) Process(){
//开启线程去读日志文件
for _, tailObj := range t.tailObjMap{
waitGroup.Add(1)
go tailObj.readLog()
}
} func (t *TailObj) readLog(){
//读取每行日志内容
for line := range t.tail.Lines{
if line.Err != nil {
logs.Error("read line failed,err:%v",line.Err)
continue
}
str := strings.TrimSpace(line.Text)
if len(str)==0 || str[0] == '\n'{
continue
} kafkaSender.addMessage(line.Text)
}
waitGroup.Done()
} func RunServer(){
tailMgr = NewTailMgr()
// 这一部分是要调用tailf读日志文件推送到kafka中
for _, filename := range appConfig.LogFiles{
err := tailMgr.AddLogFile(filename)
if err != nil{
logs.Error("add log file failed,err:%v",err)
continue
} }
tailMgr.Process()
waitGroup.Wait()
}
可以整体演示一下代码实现的效果,当我们运行程序之后我配置文件配置的目录为:
log_files=/app/log/a.log,/Users/zhaofan/a.log
我通过一个简单的代码对对a.log循环追加内容,你可以从kafka的客户端消费力看到内容了:
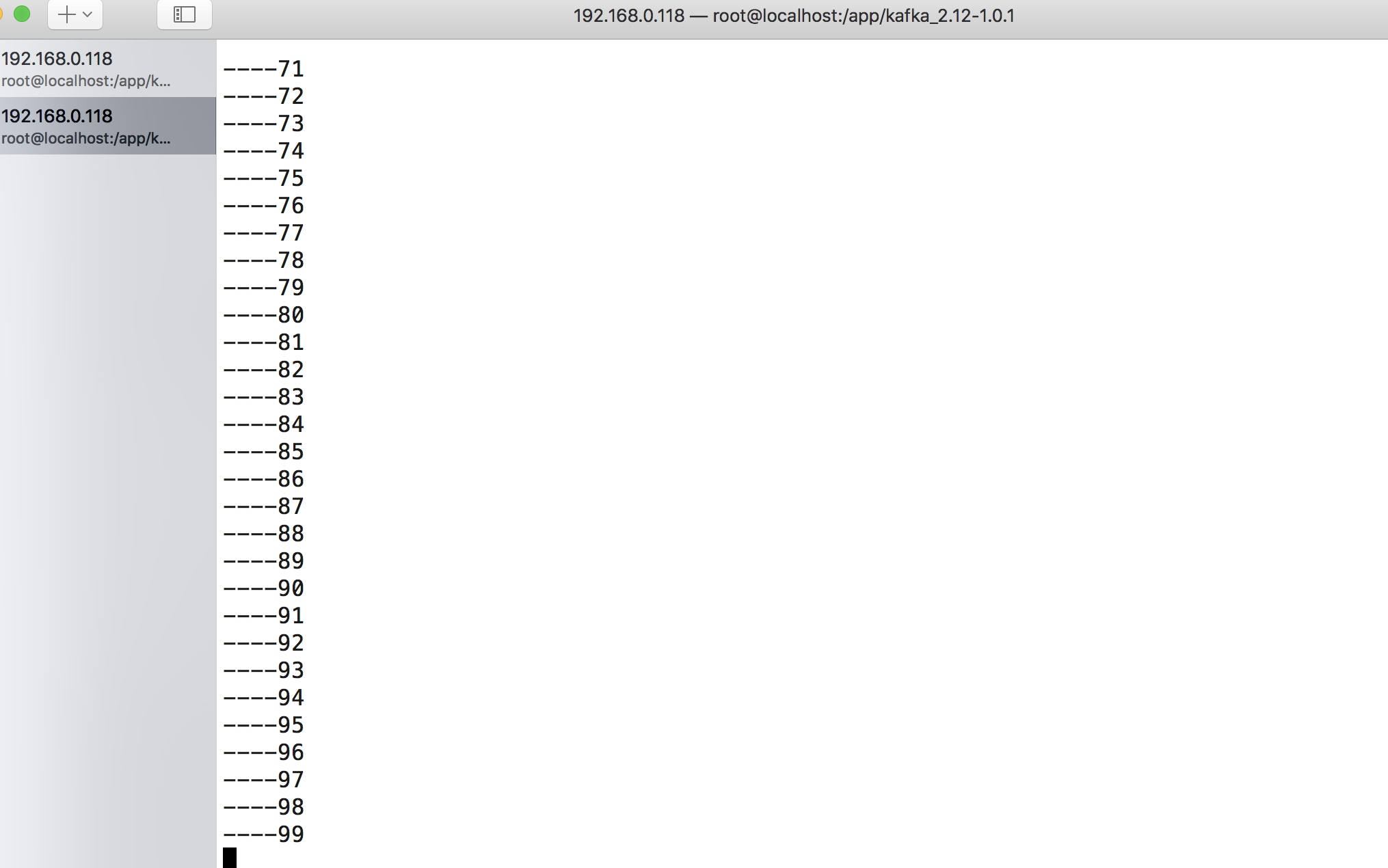
完成的代码地址:https://github.com/pythonsite/logagent
小结
这次只是实现logagent的核心功能,实现了从日志文件中通过多个线程获取要读的日志内容,这里借助了tailf,并将获取的内容放到channel中,kafka.go会从channel中取出日志内容并放到kafka的消息队列中
这里并没有做很多细致的处理,下一篇文章会在这个代码的基础上进行改进。同时现在的配置文件的方式也不是最佳的,每次改动配置文件都需要重新启动程序,后面将通过etcd的方式。
Go实现海量日志收集系统(二)的更多相关文章
- 基于Flume的美团日志收集系统(二)改进和优化
在<基于Flume的美团日志收集系统(一)架构和设计>中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计.在本节中,我们将会讲述在实际部署和使用过程中遇到的问 ...
- Go实现海量日志收集系统(一)
项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机器规模不大,一个系统通常 ...
- Go实现海量日志收集系统(三)
再次整理了一下这个日志收集系统的框,如下图 这次要实现的代码的整体逻辑为: 完整代码地址为: https://github.com/pythonsite/logagent etcd介绍 高可用的分布式 ...
- Go实现海量日志收集系统(四)
到这一步,我的收集系统就已经完成很大一部分工作,我们重新看一下我们之前画的图: 我们已经完成前面的部分,剩下是要完成后半部分,将kafka中的数据扔到ElasticSearch,并且最终通过kiban ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
- 基于Flume的美团日志收集系统 架构和设计 改进和优化
3种解决办法 https://tech.meituan.com/mt-log-system-arch.html 基于Flume的美团日志收集系统(一)架构和设计 - https://tech.meit ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- openfec的学习笔记
openfec实现了多种纠删码的算法实现,就包括Reed-Solomon算法.其基本使用流程为:输入n个原始包的分组后,计算生成k个额外的冗余包,后续将这n+k包送到接收端,若发生原始包丢包,但只要总 ...
- 洛谷P4003 无限之环(infinityloop)(网络流,费用流)
洛谷题目传送门 题目 题目描述 曾经有一款流行的游戏,叫做 Infinity Loop,先来简单的介绍一下这个游戏: 游戏在一个 n ∗ m 的网格状棋盘上进行,其中有些小方格中会有水管,水管可能在格 ...
- 【BZOJ2342】双倍回文(回文树)
[BZOJ2342]双倍回文(回文树) 题面 BZOJ 题解 构建出回文树之后 在\(fail\)树上进行\(dp\) 如果一个点代表的回文串长度为\(4\)的倍数 并且存在长度为它的一半的回文后缀 ...
- HDU 3416 Marriage Match IV(最短路,网络流)
题面 Do not sincere non-interference. Like that show, now starvae also take part in a show, but it tak ...
- ajax 状态码
状态码定义 ... 10 信息1xx ... 10.1 100继续 ... 10.1.1 101交换协议 ... 10.1.2 成功的2xx ... 10.2 200 OK ... 10.2.1 20 ...
- 【xsy2140】计数
Time Limit: 1000 ms Memory Limit: 256 MB description 吐槽 所以说..组合数的题是不是都是知道大致思路但是就是不会写qwq菜醒qwq 正题 这题其实 ...
- 【learning】凸包
吐槽 计算几何这种东西qwq一开始真的觉得恶心qwq(主要是总觉得为啥画图那么直观的东西非要写一大堆式子来求qwq真的难受qwq) 但其实静下心来学习的话感觉还是很妙的ovo题目思考起来也十分好玩ov ...
- Lintcode208 Assignment Operator Overloading (C++ Only) solution 题解
[题目描述] Implement an assignment operator overloading method. Make sure that: The new data can be copi ...
- 2018-3 WebStorm最新版本破解方法
今天重新打开WebStorm发现之前输入的License Server没法用了,不能通过WebStorm的检测,搜索良久,终于找到了最新版本WebStorm的破解方法. 在激活页面选择License ...
- IM-iOS退出后台接受消息,app退出后台能接收到推送
App被失活状态的时候可以走苹果的APNS:但是在活跃的时候却接受不到推送! 那就用到本地推送:UILocalNotification 消息神器. 处理不好可能会有很多本地推送到来,那么问题来了要在什 ...