Scrapy-redis<数据库篇>
scrapy-redis爬虫数据库连接部分——windows准备做salve,Linux准备做master开展工作
首先处理简单的windows熟悉的环境——安装Redis服务和Redis可视化~可视化也可以省略,但作为新手推荐使用:
1、安装redis服务:链接: https://pan.baidu.com/s/1EA0I-gx9NEU78vjZeZVqJA 提取码: 4s4i ——直接next下去
2、安装redis可视化:链接: https://pan.baidu.com/s/1KQh_g2o0tQijHQRFpKjcng 提取码: ny9c
安装redis可视化~:
1、确保redis安装完成,确保redis服务正常开启
2、正常打开界面:
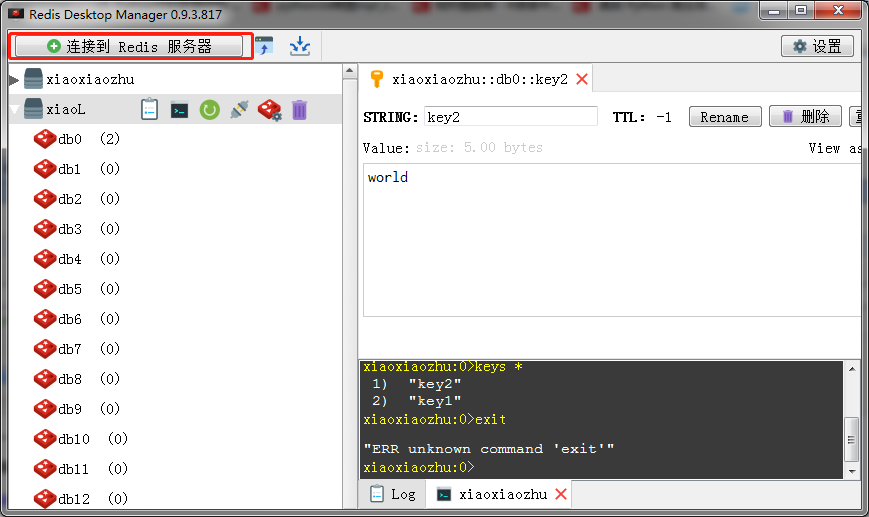

名字自定义~
验证为redis的密码~安装之后默认是空的就是这个——requirepass,直接连接,即可连接上windows本地的redis数据库
然后进行测试即可,测试详细内容百度。
不安装可视化的~就直接redis操作即可。
接下来是Linux服务里面安装redis:https://redis.io/download

安装完之后~直接进入redis-5.0.4文件夹:cd redis-5.0.4——>修改redis.conf文件:gedit redis.conf
修改三个属性:1.注释bind 127.0.0.1,以便其它ip访问,2.修改protected-mode yes,该改为no,3.设置密码 requirepass,默认是注释掉的,打开后设置密码。Over!
然后开始服务:sec/redis-server redis.conf
如果访问不了:
1、在linux下的防火墙中开放6379端口(与centos7以下版本开放端口的方式有区别):firewall-cmd --zone=public --add-port=6379/tcp --permanent
2、重启防火墙:systemctl restart firewalld
3、启动redis:src/redis-server redis.conf
此时开始测试:打开另一个黑窗口,进入redis文件夹,输入:src/redis-cli,回车,先输入keys *,出现: ,则输入你的密码即可:auth "密码";
,则输入你的密码即可:auth "密码";
这时候无错误情况下Linux下的Redis安装完成。
直接进入RedisDesktop里面连接服务,需要输入Linux的ip地址,Linux的ip地址查询:ifconfig -a ,windows的ip地址查询:ipconfig;
名字自取——ip地址输入——端口输入正确,无改变的情况下是6379——输入redis设置的密码;
结束windows下连接Linux下redis服务
Scrapy-redis<数据库篇>的更多相关文章
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- scrapy+redis去重实现增量抓取
class ProjectnameDownloaderMiddleware(object): # Not all methods need to be defined. If a method is ...
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
- Redis与Scrapy
Redis与Scrapy Redis与Scrapy Redis is an open source, BSD licensed, advanced key-value cache and store. ...
- python - scrapy 爬虫框架 ( redis去重 )
1. 使用内置,并加以修改 ( 自定义 redis 存储的 keys ) settings 配置 # ############### scrapy redis连接 ################# ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- scrapy简单分布式爬虫
经过一段时间的折腾,终于整明白scrapy分布式是怎么个搞法了,特记录一点心得. 虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘.有能人改变了scrapy的队列调度,将起始的网 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
随机推荐
- LeetCode Javascript实现 283. Move Zeroes 349. Intersection of Two Arrays 237. Delete Node in a Linked List
283. Move Zeroes var moveZeroes = function(nums) { var num1=0,num2=1; while(num1!=num2){ nums.forEac ...
- toString()方法详解
在类型转换中,经常用到方法valueOf()和toString(),上一篇讲了valueOf()方法,这一篇来说说toString()方法.toSting()方法返回返回对象的字符串表现. [1]基本 ...
- HTML5 CSS3专题 诱人的实例 CSS3打造百度贴吧的3D翻牌效果
首先感谢w3cfuns的老师~ 今天给大家带来一个CSS3制作的翻牌效果,就是鼠标移到元素上,感觉可以看到元素背后的信息.大家如果制作考验记忆力的连连看.扑克类的游戏神马的,甚至给女朋友写一些话语,放 ...
- 理解、学习与使用 Java 中的 Optional
从 Java 8 引入的一个很有趣的特性是 Optional 类.Optional 类主要解决的问题是臭名昭著的空指针异常(NullPointerException) -- 每个 Java 程序员都 ...
- 对象和XML文件的转换
很多时候,我们开发程序都需要使用到对象的XML序列化和反序列化,对象的XML序列化和反序列化,既可以使用XML对象(XmlDocument)进行操作,也可以使用XmlSerializer进行操作,两个 ...
- 从group by 展开去
一.概念 "Group By"从字面意义上理解就是根据"By"指定的规则对数据进行分组,所谓的分组就是将一个"数据集"划分成若干个" ...
- Javascript保证精度的小数乘法
众所周知,js的小数乘法很容易丢失精度,这是一件很恶心的事情.所以我写了这个方法,保证计算精度./** * js小数乘法 *@parameter arg1:被乘数(接受小数和整数) *@paramet ...
- 【Android】自己动手做个扫雷游戏
1. 游戏规则 扫雷是玩法极其简单的小游戏,点击玩家认为不存在雷的区域,标记出全部地雷所在的区域,即可获得胜利.当点击不包含雷的块的时候,可能它底下存在一个数,也可能是一个空白块.当点击中有数字的块时 ...
- mpvue 小程序开发爬坑汇总
<!-- 小程序的爬坑记录 --> 1 微信小程序之动态获取元素宽高 var obj=wx.createSelectorQuery(); 2 微信小程序图片自适应 <image cl ...
- Python全国二级等级考试(2019)
一.前言 2018年9月随着全国计算机等级考试科目中加入“二级Python”,也确立了Python在国内的地位,猪哥相信Python语言势必会像PS那般普及.不久的将来,谁会Python谁就能获得女神 ...