爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫架构中的HTML下载器、HTML解析器、数据存储器三大模块。
step1:首先打开我们要爬取的网站url:http://maoyan.com/board/4;
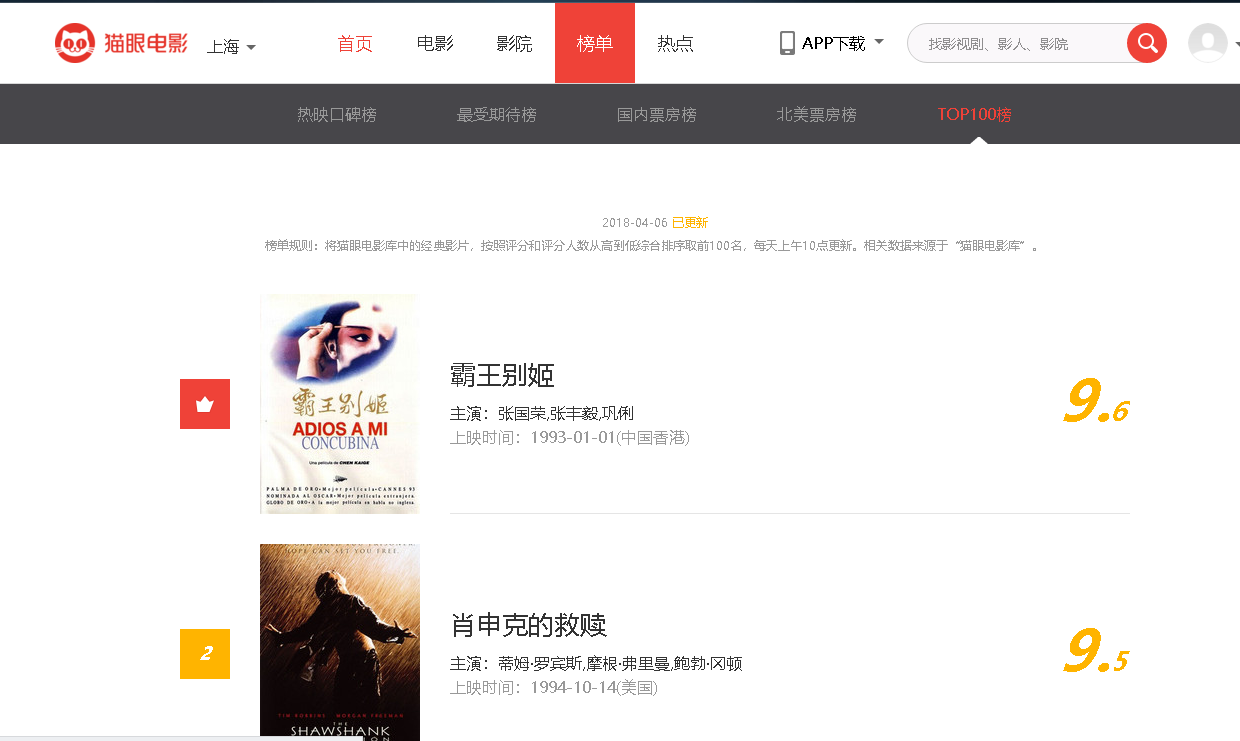
step2:简单的分析一下网页的源代码,找到我们要爬取的相关信息,以及信息在html源码中的位置,确定我们的正则表达式;
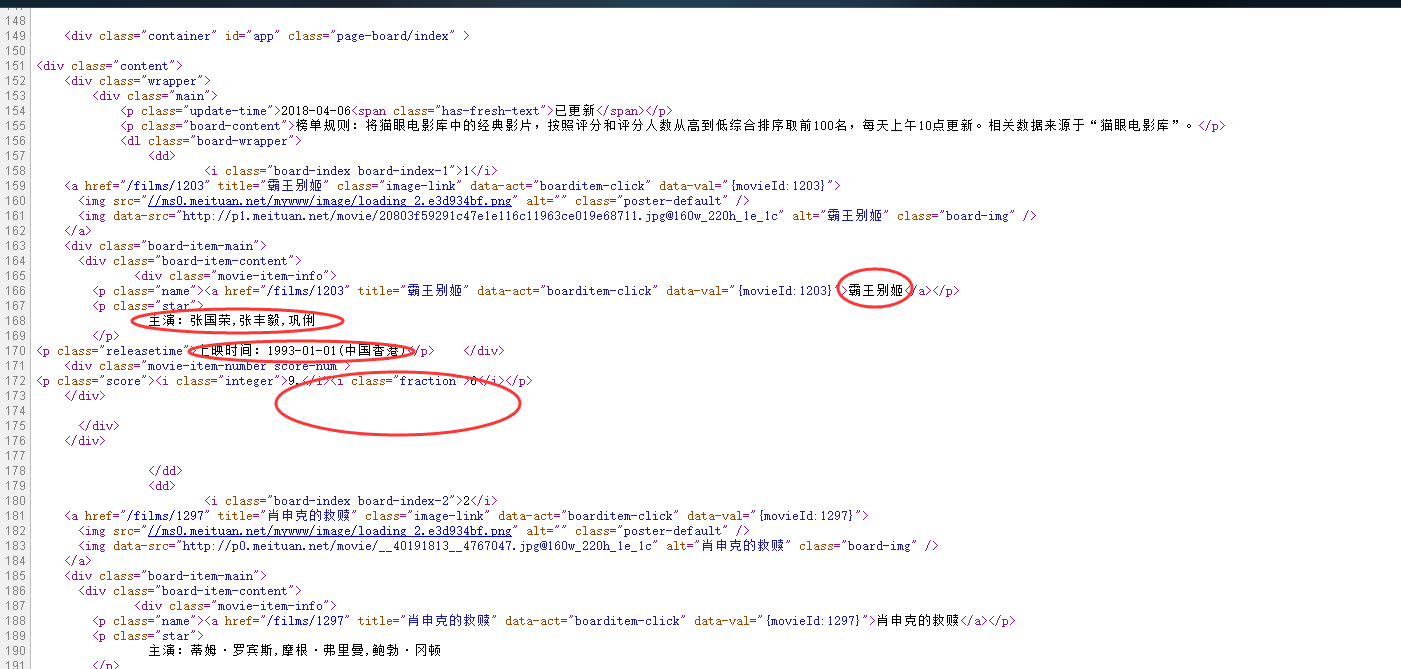
step3:然后开始构造HTML下载器
def get_one_req(url):
try:
data=urllib.request.urlopen(url).read().decode('utf-8')
return data
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
step4:然后构造HTML解析器
def parse__one_html(data):
pat='<p class="name"><a.*?data-val=.*?>(.*?)</a></p>.*?主演:(.*?)\s</p>.*?上映时间:(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i></p>'
res=re.compile(pat,re.S).findall(data)
return res
step5:数据存储
df=open('F:/top100.txt','w',encoding='utf-8')
for i in range(10):#设置要爬取的页数i
url="http://maoyan.com/board/4?offset=0"+str(i*10)
data=get_one_req(url)
res=parse__one_html(data)
for j in range(len(res)):
item={
'编号':str(i)+str(j),
'名称':res[j][0],
'主演':res[j][1].strip(),#删除空字符
'上映时间':res[j][2],
'评分':res[j][3]+res[j][4]
}
df.write(json.dumps(item,ensure_ascii=False)+'\n')#注意编码
完整的代码如下:
import urllib.request
import re
import urllib.error
import json
url="http://maoyan.com/board/4?offset=0"
#模拟浏览器
headers=("user-agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 BIDUBrowser/8.7 Safari/537.36")
opener=urllib.request.build_opener()
opener.addheaders=[headers]#添加报头
urllib.request.install_opener(opener)#设置opner全局化,这样就可以直接调用urllib.request.urlopen()
#
def get_one_req(url):
try:
data=urllib.request.urlopen(url).read().decode('utf-8')
return data
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
def parse__one_html(data):
pat='<p class="name"><a.*?data-val=.*?>(.*?)</a></p>.*?主演:(.*?)\s</p>.*?上映时间:(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i></p>'
res=re.compile(pat,re.S).findall(data)
return res
def main():
df=open('F:/top100.txt','w',encoding='utf-8')
for i in range(10):#设置要爬取的页数i
url="http://maoyan.com/board/4?offset=0"+str(i*10)
data=get_one_req(url)
res=parse__one_html(data)
for j in range(len(res)):
item={
'编号':str(i)+str(j),
'名称':res[j][0],
'主演':res[j][1].strip(),#删除空字符
'上映时间':res[j][2],
'评分':res[j][3]+res[j][4]
}
df.write(json.dumps(item,ensure_ascii=False)+'\n')#注意编码
#df.close()
#print('第'+str(i+1)+'页的内容是:',res)
if __name__ =='__main__':
main()
最后保存的文件内容如下,大家也可以保存为.csv格式,这样比较方便后期的数据分析和处理。
{"第1页的内容是:名称": "霸王别姬", "主演": "张国荣,张丰毅,巩俐", "上映时间": "1993-01-01(中国香港)", "评分": "9.6"}
{"第1页的内容是:名称": "肖申克的救赎", "主演": "蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿", "上映时间": "1994-10-14(美国)", "评分": "9.5"}
{"第1页的内容是:名称": "罗马假日", "主演": "格利高利·派克,奥黛丽·赫本,埃迪·艾伯特", "上映时间": "1953-09-02(美国)", "评分": "9.1"}
{"第1页的内容是:名称": "这个杀手不太冷", "主演": "让·雷诺,加里·奥德曼,娜塔莉·波特曼", "上映时间": "1994-09-14(法国)", "评分": "9.5"}
{"第1页的内容是:名称": "泰坦尼克号", "主演": "莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩", "上映时间": "1998-04-03", "评分": "9.5"}
{"第1页的内容是:名称": "教父", "主演": "马龙·白兰度,阿尔·帕西诺,詹姆斯·凯恩", "上映时间": "1972-03-24(美国)", "评分": "9.3"}
{"第1页的内容是:名称": "龙猫", "主演": "日高法子,坂本千夏,糸井重里", "上映时间": "1988-04-16(日本)", "评分": "9.2"}
{"第1页的内容是:名称": "唐伯虎点秋香", "主演": "周星驰,巩俐,郑佩佩", "上映时间": "1993-07-01(中国香港)", "评分": "9.2"}
{"第1页的内容是:名称": "千与千寻", "主演": "柊瑠美,入野自由,夏木真理", "上映时间": "2001-07-20(日本)", "评分": "9.3"}
{"第1页的内容是:名称": "魂断蓝桥", "主演": "费雯·丽,罗伯特·泰勒,露塞尔·沃特森", "上映时间": "1940-05-17(美国)", "评分": "9.2"}
{"第2页的内容是:名称": "喜剧之王", "主演": "周星驰,莫文蔚,张柏芝", "上映时间": "1999-02-13(中国香港)", "评分": "9.2"}
{"第2页的内容是:名称": "乱世佳人", "主演": "费雯·丽,克拉克·盖博,奥利维娅·德哈维兰", "上映时间": "1939-12-15(美国)", "评分": "9.1"}
{"第2页的内容是:名称": "天空之城", "主演": "寺田农,鹫尾真知子,龟山助清", "上映时间": "1992", "评分": "9.1"}
{"第2页的内容是:名称": "大闹天宫", "主演": "邱岳峰,毕克,富润生", "上映时间": "1965-12-31", "评分": "9.0"}
{"第2页的内容是:名称": "辛德勒的名单", "主演": "连姆·尼森,拉尔夫·费因斯,本·金斯利", "上映时间": "1993-12-15(美国)", "评分": "9.2"}
{"第2页的内容是:名称": "音乐之声", "主演": "朱丽·安德鲁斯,克里斯托弗·普卢默,埃琳诺·帕克", "上映时间": "1965-03-02(美国)", "评分": "9.0"}
{"第2页的内容是:名称": "剪刀手爱德华", "主演": "约翰尼·德普,薇诺娜·瑞德,黛安娜·维斯特", "上映时间": "1990-12-06(美国)", "评分": "8.8"}
{"第2页的内容是:名称": "春光乍泄", "主演": "张国荣,梁朝伟,张震", "上映时间": "1997-05-30(中国香港)", "评分": "9.2"}
{"第2页的内容是:名称": "美丽人生", "主演": "罗伯托·贝尼尼,尼可莱塔·布拉斯基,乔治·坎塔里尼", "上映时间": "1997-12-20(意大利)", "评分": "9.3"}
{"第2页的内容是:名称": "黑客帝国", "主演": "基努·里维斯,凯瑞-安·莫斯,劳伦斯·菲什伯恩", "上映时间": "2000-01-14", "评分": "9.0"}
{"第3页的内容是:名称": "海上钢琴师", "主演": "蒂姆·罗斯,普路特·泰勒·文斯,比尔·努恩", "上映时间": "1998-10-28(意大利)", "评分": "9.2"}
{"第3页的内容是:名称": "指环王3:王者无敌", "主演": "伊利亚·伍德,伊恩·麦克莱恩,丽芙·泰勒", "上映时间": "2004-03-15", "评分": "9.2"}
{"第3页的内容是:名称": "加勒比海盗", "主演": "约翰尼·德普,凯拉·奈特莉,奥兰多·布鲁姆", "上映时间": "2003-11-21", "评分": "8.9"}
{"第3页的内容是:名称": "哈利·波特与魔法石", "主演": "丹尼尔·雷德克里夫,鲁伯特·格林特,艾玛·沃森", "上映时间": "2002-01-26", "评分": "9.1"}
{"第3页的内容是:名称": "射雕英雄传之东成西就", "主演": "张国荣,林青霞,梁朝伟", "上映时间": "1993-02-05(中国香港)", "评分": "8.9"}
{"第3页的内容是:名称": "无间道", "主演": "刘德华,梁朝伟,黄秋生", "上映时间": "2003-09-05", "评分": "9.1"}
爬虫的基本思路还是挺好理解的,希望大家一起交流学习。
爬虫系列(1)-----python爬取猫眼电影top100榜的更多相关文章
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- Python爬取猫眼电影100榜并保存到excel表格
首先我们前期要导入的第三方类库有; 通过猫眼电影100榜的源码可以看到很有规律 如: 亦或者是: 根据规律我们可以得到非贪婪的正则表达式 """<div class ...
- 爬虫练习之正则表达式爬取猫眼电影Top100
#猫眼电影Top100import requests,re,timedef get_one_page(url): headers={ 'User-Agent':'Mozilla/5.0 (Window ...
- Requests+正则表达式爬取猫眼电影(TOP100榜)
猫眼电影网址:www.maoyan.com 前言:网上一些大神已经对猫眼电影进行过爬取,所用的方法也是各有其优,最终目的是把影片排名.图片.名称.主要演员.上映时间与评分提取出来并保存到文件或者数据库 ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
随机推荐
- 百度统计&友盟统计
一.百度统计 登录百度站长统计账号-->管理 --->代码获取-->复制代码,如 <script> var _hmt = _hmt || []; (function() ...
- 利用Cglib实现AOP
前文讲了, 可以利用Spring, Guice等框架提供的容器实现AOP, 如果想绕过容器, 直接注入Class, 可以利用Cglib为对象加上动态代理,实现代码切入, 但是每次调用比较繁琐, 因此我 ...
- Scala编程快速入门系列(一)
目 录 一.Scala概述 二.Scala数据类型 三.Scala函数 四.Scala集合 五.Scala伴生对象 六.Scala trait 七.Actor 八.隐式转换与隐式参数 九.Sca ...
- 用JavaScript写一个区块链
几乎每个人都听说过像比特币和以太币这样的加密货币,但是只有极少数人懂得隐藏在它们背后的技术.在这篇博客中,我将会用JavaScript来创建一个简单的区块链来演示它们的内部究竟是如何工作的.我将会称之 ...
- .net core 2使用ef core 2.0以db first方法创建实体类
先安装以下三个包: Install-Package Microsoft.EntityFrameworkCore.SqlServer Install-Package Microsoft.EntityFr ...
- Hadoop 2.6.0-cdh5.4.0集群环境搭建和Apache-Hive、Sqoop的安装
搭建此环境主要用来hadoop的学习,因此我们的操作直接在root用户下,不涉及HA. Software: Hadoop 2.6.0-cdh5.4.0 Apache-hive-2.1.0-bin Sq ...
- 发个2012年用java写的一个控制台小游戏
时间是把杀狗刀 突然发现了12年用java写的控制台玩的一个文字游戏,有兴趣的可以下载试试哈汪~ 里面难点当时确实遇到过,在计算倒计时的时候用了多线程,当时还写了好久才搞定.很怀念那个时间虽然不会做游 ...
- Effective Java 第三版——37. 使用EnumMap替代序数索引
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
- cesium 显示北京时间
cesium用的JulianDate:代表天文朱利安时间,用的是世界协调时,比北京时间晚8个小时,所以在源代码中给默认的时间格式加上8小时. 应该会有更好的办法,希望有大神可以告诉我!!!!!!!!! ...
- 微软Skype Linux客户端全新发布
前两天,微软说要给“Linux 用户带来一个令人兴奋的新闻”,今天,这个新闻来了.它刚刚为 Linux 发布了一个新的 Skype 客户端. 此次发布,微软为 Linux 带来的 Skype 客户端与 ...