webmagic 增量爬取
webmagic 是一个很好并且很简单的爬虫框架,其教程网址:http://my.oschina.net/flashsword/blog/180623
webmagic参考了scrapy的模块划分,分为Spider(整个爬虫的调度框架)、Downloader(页面下载)、PageProcessor(链接提取和页面分析)、Scheduler(URL管理)、Pipeline(离线分析和持久化)几部分。只不过scrapy通过middleware实现扩展,而webmagic则通过定义这几个接口,并将其不同的实现注入主框架类Spider来实现扩展。
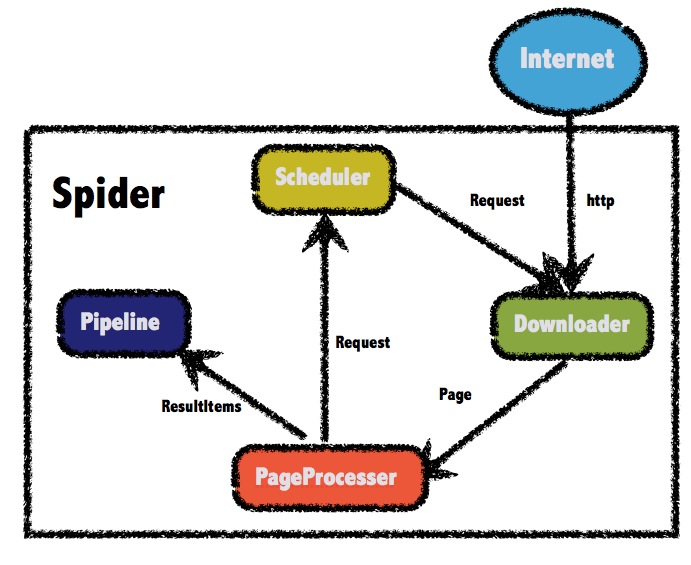
关于Scheduler(URL管理) 最基本的功能是实现对已经爬取的URL进行标示。
目前scheduler有三种实现方式:
1)内存队列
2)文件队列
3)redis队列
文件队列保存URL,能实现中断后,继续爬取时,实现增量爬取。
如果我只有一个主页的URL,比如:http://www.cndzys.com/yundong/。如果直接引用webmagic的FileCacheQueueScheduler的话,你会发现第二次启动的时候,什么也爬不到。可以说第二次启动基本不爬取数据了。因为FileCacheQueueScheduler 把http://www.cndzys.com/yundong/ 记录了,然后不再进行新的爬取。虽然是第二次增量爬取,但还是需要保留某些URL重新爬取,以保证爬取结果是我们想要的。我们可以重写FileCacheQueueScheduler里的比较方法。
package com.fortunedr.crawler.expertadvice; import java.io.BufferedReader;
import java.io.Closeable;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.concurrent.atomic.AtomicInteger; import org.apache.commons.io.IOUtils;
import org.apache.commons.lang3.math.NumberUtils; import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.scheduler.DuplicateRemovedScheduler;
import us.codecraft.webmagic.scheduler.MonitorableScheduler;
import us.codecraft.webmagic.scheduler.component.DuplicateRemover; /**
* Store urls and cursor in files so that a Spider can resume the status when shutdown.<br>
*增加去重的校验,对需要重复爬取的网址进行正则过滤
* @author code4crafter@gmail.com <br>
* @since 0.2.0
*/
public class SpikeFileCacheQueueScheduler extends DuplicateRemovedScheduler implements MonitorableScheduler,Closeable { private String filePath = System.getProperty("java.io.tmpdir"); private String fileUrlAllName = ".urls.txt"; private Task task; private String fileCursor = ".cursor.txt"; private PrintWriter fileUrlWriter; private PrintWriter fileCursorWriter; private AtomicInteger cursor = new AtomicInteger(); private AtomicBoolean inited = new AtomicBoolean(false); private BlockingQueue<Request> queue; private Set<String> urls; private ScheduledExecutorService flushThreadPool; private String regx; public SpikeFileCacheQueueScheduler(String filePath) {
if (!filePath.endsWith("/") && !filePath.endsWith("\\")) {
filePath += "/";
}
this.filePath = filePath;
initDuplicateRemover();
} private void flush() {
fileUrlWriter.flush();
fileCursorWriter.flush();
} private void init(Task task) {
this.task = task;
File file = new File(filePath);
if (!file.exists()) {
file.mkdirs();
}
readFile();
initWriter();
initFlushThread();
inited.set(true);
logger.info("init cache scheduler success");
} private void initDuplicateRemover() {
setDuplicateRemover(
new DuplicateRemover() {
@Override
public boolean isDuplicate(Request request, Task task) {
if (!inited.get()) {
init(task);
}
boolean temp=false;
String url=request.getUrl();
temp=!urls.add(url);//原来验证URL是否存在
//正则匹配
if(url.matches(regx)){//二次校验,如果符合我们需要重新爬取的,返回false。可以重新爬取
temp=false;
}
return temp;
} @Override
public void resetDuplicateCheck(Task task) {
urls.clear();
} @Override
public int getTotalRequestsCount(Task task) {
return urls.size();
}
});
} private void initFlushThread() {
flushThreadPool = Executors.newScheduledThreadPool(1);
flushThreadPool.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
flush();
}
}, 10, 10, TimeUnit.SECONDS);
} private void initWriter() {
try {
fileUrlWriter = new PrintWriter(new FileWriter(getFileName(fileUrlAllName), true));
fileCursorWriter = new PrintWriter(new FileWriter(getFileName(fileCursor), false));
} catch (IOException e) {
throw new RuntimeException("init cache scheduler error", e);
}
} private void readFile() {
try {
queue = new LinkedBlockingQueue<Request>();
urls = new LinkedHashSet<String>();
readCursorFile();
readUrlFile();
// initDuplicateRemover();
} catch (FileNotFoundException e) {
//init
logger.info("init cache file " + getFileName(fileUrlAllName));
} catch (IOException e) {
logger.error("init file error", e);
}
} private void readUrlFile() throws IOException {
String line;
BufferedReader fileUrlReader = null;
try {
fileUrlReader = new BufferedReader(new FileReader(getFileName(fileUrlAllName)));
int lineReaded = 0;
while ((line = fileUrlReader.readLine()) != null) {
urls.add(line.trim());
lineReaded++;
if (lineReaded > cursor.get()) {
queue.add(new Request(line));
}
}
} finally {
if (fileUrlReader != null) {
IOUtils.closeQuietly(fileUrlReader);
}
}
} private void readCursorFile() throws IOException {
BufferedReader fileCursorReader = null;
try {
fileCursorReader = new BufferedReader(new FileReader(getFileName(fileCursor)));
String line;
//read the last number
while ((line = fileCursorReader.readLine()) != null) {
cursor = new AtomicInteger(NumberUtils.toInt(line));
}
} finally {
if (fileCursorReader != null) {
IOUtils.closeQuietly(fileCursorReader);
}
}
} public void close() throws IOException {
flushThreadPool.shutdown();
fileUrlWriter.close();
fileCursorWriter.close();
} private String getFileName(String filename) {
return filePath + task.getUUID() + filename;
} @Override
protected void pushWhenNoDuplicate(Request request, Task task) {
queue.add(request);
fileUrlWriter.println(request.getUrl());
} @Override
public synchronized Request poll(Task task) {
if (!inited.get()) {
init(task);
}
fileCursorWriter.println(cursor.incrementAndGet());
return queue.poll();
} @Override
public int getLeftRequestsCount(Task task) {
return queue.size();
} @Override
public int getTotalRequestsCount(Task task) {
return getDuplicateRemover().getTotalRequestsCount(task);
} public String getRegx() {
return regx;
}
/**
* 设置保留需要重复爬取url的正则表达式
* @param regx
*/
public void setRegx(String regx) {
this.regx = regx;
} }
那么在爬虫时就引用自己特定的FileCacheQueueScheduler就可以
spider.addRequest(requests);
SpikeFileCacheQueueScheduler file=new SpikeFileCacheQueueScheduler(filePath);
file.setRegx(regx);//http://www.cndzys.com/yundong/(index)?[0-9]*(.html)?
spider.setScheduler(file );
这样就实现了增量爬取。
优化的想法:一般某个网站的内容列表都是首页是最新内容。上面的方式是可以实现增量爬取,但是还是需要爬取很多“无用的”列表页面。
能不能实现,当爬取到上次"最新"URL之后就不再爬取。就是不用爬取其他多余的leib
webmagic 增量爬取的更多相关文章
- scrapy增量爬取
开始接触爬虫的时候还是初学Python的那会,用的还是request.bs4.pandas,再后面接触scrapy做个一两个爬虫,觉得还是框架好,可惜都没有记录都忘记了,现在做推荐系统需要爬取一定的 ...
- scrapy过滤重复数据和增量爬取
原文链接 前言 这篇笔记基于上上篇笔记的---<scrapy电影天堂实战(二)创建爬虫项目>,而这篇又涉及redis,所以又先熟悉了下redis,记录了下<redis基础笔记> ...
- 使用scrapy实现去重,使用Redis实现增量爬取
面试场景: 要求对正在爬取的内容与mysql数据库中的数据进行比较去重 解决方式: 通过Redis来作为中间件,通过url来确保爬过的数据不会再爬,做到增量爬取. Redis数据库其实就是一个中间件, ...
- nutch的定时增量爬取
译文来着: http://wiki.apache.org/nutch/Crawl 介绍(Introduction) 注意:脚本中没有直接使用Nutch的爬去命令(bin/nutch crawl或者是& ...
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 爬虫——爬取Ajax动态加载网页
常见的反爬机制及处理方式 1.Headers反爬虫 :Cookie.Referer.User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法 2.IP限制 ...
- python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息 没办法,用账号登录进去,登录后的网页如下: 输入职位名称点击搜索,显示如下网页: 把这个URL:https://s ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- webmagic爬取渲染网站
最近突然得知之后的工作有很多数据采集的任务,有朋友推荐webmagic这个项目,就上手玩了下.发现这个爬虫项目还是挺好用,爬取静态网站几乎不用自己写什么代码(当然是小型爬虫了~~|). 好了,废话少说 ...
随机推荐
- 智力火柴游戏Android源码项目
该游戏源码是一个智力火柴游戏源码,游戏分为难.中.易三种模式,通过对火柴的移动来实现等式分成立,具有极好的市场价值和参考意义. 源码下载: http://code.662p.com/view/9741 ...
- Hibernate核心技术简介
Hibernate核心技术简介 1.Hibernate映射文件开发 Hibernate映射文件就是项目中*.hbm.xml文件,其主要是完成各元素的配置,包括根元素.类元素.定义主键.设置主键 ...
- monkey之monkey简介
1.Monkey 是什么 Monkey是Android中的一个命令行工具,可以运行在模拟器里或实际设备中.它向系统发送伪随机的用户事件流(如按键输入.触摸屏输入.手势输入等),实现对正在开发的应用程序 ...
- nginx简易入门(转)
相信很多人都听过nginx,这个小巧的东西慢慢地在吞食apache和IIS的份额.那究竟它有什么作用呢?可能很多人未必了解. 说到反向代理,可能很多人都听说,但具体什么是反向代理,很多人估计就不清楚了 ...
- Java 线程同步
线程同步 1.线程同步的目的是为了保护多个线程访问一个资源时对资源的破坏. 2.线程同步方法是通过锁来实现,每个对象都有切仅有一个锁,这个锁与一个特定的对象关联,线程一旦获取了对象锁,其他访问该对象的 ...
- quartz-1.8.5 Demo
最近在研究Spring中的定时任务功能,最好的办法当然是使用Quartz来实现.对于一个新手来说,花了我不少时间,这里我写个笔记,给大家参考. 我使用的是Maven来管理项目,需要的Jar包我给大家贴 ...
- Revolving Digits[EXKMP]
Revolving Digits Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- 微信小程序购物商城系统开发系列-工具篇
微信小程序开放公测以来,一夜之间在各种技术社区中就火起来啦.对于它 估计大家都不陌生了,对于它未来的价值就不再赘述,简单一句话:可以把小程序简单理解为一个新的操作系统.新的生态,未来大部分应用场景都将 ...
- 【转载】WEB前端开发规范文档
本文转载自谈笑涧<WEB前端开发规范文档> 为 新项目写的一份规范文档, 分享给大家. 我想前端开发过程中, 无论是团队开发, 还是单兵做站, 有一份开发文档做规范, 对开发工作都是很有益 ...
- Maven项目中的pom.xml详解【转】
什么是pom? pom作为项目对象模型.通过xml表示maven项目,使用pom.xml来实现.主要描述了项目:包括配置文件:开发者需要遵循的规则,缺陷管理系统,组织和licenses,项目的url, ...