Spring Data JPA笔记
1. Spring Data JPA是什么
Spring Data JPA是Spring Data大家族中的一员,它对对持久层做了简化,用户只需要声明方法的接口,不需要实现该接口,Spring Data JPA内部会根据不同的策略、通过不同的方法创建Query操作数据库。
使用Spring Data JPA可以在几乎不用写实现的情况下实现对数据的访问和操作,除了CRUD之外还有分页、排序等常用功能。
比如,当你看到UserDao.findUserById() 这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。Spring Data JPA 做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
2. 如何使用
使用Spring Data JPA的套路
1. 声明持久层的接口,该接口继承Repository,Repository是一个标记型的接口,它不包含任何方法,Spring Data JPA也提供了一些Repository的一些子接口,其中定义了一些常用的增删改查,以及分页相关的方法,我们一般并不会直接继承Repository,而是继承他的一个子类叫做JpaRepository。
2. 在接口中声明需要的业务方法,Spring Data将根据特定的策略来为其生成实现代码。
3. 在 Spring 配置文件中增加一行声明,让 Spring 为声明的接口创建代理对象。配置了 <jpa:repositories> 后,Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为Spring Bean,业务层便可以通过 Spring 自动封装的特性来直接使用该对象。
举个栗子
项目结构如下:
Spring Data JPA的配置文件叫做persistence.xml,网上说的必须放在META-INF下面,偶不信邪,只要开发者脑子没坑的话设计基本就是给一个默认的,然后提供setter来让用户定制,直接去源代码中看,有一个叫做DefaultPersistenceUnitManager的类,其中有一个叫做DEFAULT_PERSISTENCE_XML_LOCATION的成员变量提供了默认的配置文件位置,还有一个persistenceXmlLocations可以用来设置配置文件的位置:
- public class DefaultPersistenceUnitManager implements PersistenceUnitManager, ResourceLoaderAware, LoadTimeWeaverAware, InitializingBean {
- /** 这个保存了默认的配置文件位置 */
- public static final String DEFAULT_PERSISTENCE_XML_LOCATION = "classpath*:META-INF/persistence.xml";
- ..........
- /** 可以看到默认就已经有一个了,我们可以调用这个属性的setter来设置*/
- private String[] persistenceXmlLocations = new String[]{"classpath*:META-INF/persistence.xml"};
- ..........
- /** setter方法在这里 */
- public void setPersistenceXmlLocation(String persistenceXmlLocation) {
- this.persistenceXmlLocations = new String[]{persistenceXmlLocation};
- }
- public void setPersistenceXmlLocations(String... persistenceXmlLocations) {
- this.persistenceXmlLocations = persistenceXmlLocations;
- }
- .........
- }
- 在Spring的配置文件中指定配置文件的位置即可,Spring的配置文件applicationContext.xml:
- <?xml version="1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xmlns:context="http://www.springframework.org/schema/context"
- xmlns:jpa="http://www.springframework.org/schema/data/jpa"
- xsi:schemaLocation="http://www.springframework.org/schema/beans
- http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
- http://www.springframework.org/schema/context
- http://www.springframework.org/schema/context/spring-context-3.0.xsd
- http://www.springframework.org/schema/data/jpa
- http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
- <context:annotation-config></context:annotation-config>
- <context:component-scan base-package="org.cc11001100.spring.data.jpa"></context:component-scan>
- <!-- =============================== Spring Data JPA 相关配置 =============================== -->
- <!-- 配置实体管理器 -->
- <bean id="entityManagerFactory"
- class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
- <property name="jpaVendorAdapter">
- <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
- <property name="generateDdl" value="true" />
- <property name="database" value="MYSQL" />
- </bean>
- </property>
- <property name="persistenceUnitName" value="SimpleJPA" />
- <property name="persistenceXmlLocation" value="persistence.xml" />
- </bean>
- <!-- 配置事务管理器 -->
- <bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
- <property name="entityManagerFactory" ref="entityManagerFactory" />
- </bean>
- <!-- 配置Spring Data JPA扫描目录 -->
- <jpa:repositories base-package="org.cc11001100.spring.data.jpa.dao"
- entity-manager-factory-ref="entityManagerFactory"
- transaction-manager-ref="transactionManager"/>
- </beans>
- JPA的配置文件persistence.xml:
- <?xml version="1.0" encoding="UTF-8"?>
- <persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0">
- <persistence-unit name="SimpleJPA" transaction-type="RESOURCE_LOCAL">
- <provider>org.hibernate.ejb.HibernatePersistence</provider>
- <class>org.cc11001100.spring.data.jpa.domain.User</class>
- <properties>
- <property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver"/>
- <property name="hibernate.connection.url" value="jdbc:mysql:///test_jpa"/>
- <property name="hibernate.connection.username" value="root"/>
- <property name="hibernate.connection.password" value="toor"/>
- <property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5Dialect"/>
- <property name="hibernate.show_sql" value="true"/>
- <property name="hibernate.format_sql" value="true"/>
- <property name="hibernate.use_sql_comments" value="false"/>
- <property name="hibernate.hbm2ddl.auto" value="update"/>
- </properties>
- </persistence-unit>
- </persistence>
相关的Java文件域模型User.java:
- package org.cc11001100.spring.data.jpa.domain;
- import javax.persistence.*;
- @Entity
- @Table(name = "t_user")
- public class User {
- @Id
- @GeneratedValue(strategy= GenerationType.AUTO)
- private Long id;
- private String username;
- private String passwd;
- public Long getId() {
- return id;
- }
- public void setId(Long id) {
- this.id = id;
- }
- public String getUsername() {
- return username;
- }
- public void setUsername(String username) {
- this.username = username;
- }
- public String getPasswd() {
- return passwd;
- }
- public void setPasswd(String passwd) {
- this.passwd = passwd;
- }
- }
Dao层UserDao.java:
- package org.cc11001100.spring.data.jpa.dao;
- import org.cc11001100.spring.data.jpa.domain.User;
- import org.springframework.data.jpa.repository.JpaRepository;
- public interface UserDao extends JpaRepository<User, Long> {
- }
- Service层接口声明UserService.java:
- package org.cc11001100.spring.data.jpa.service;
- import org.cc11001100.spring.data.jpa.domain.User;
- import org.springframework.stereotype.Service;
- import java.util.List;
- public interface UserService {
- User findById(long id);
- User save(User user);
- List<User> findAll();
- }
Service实现UserServiceImpl.java:
- package org.cc11001100.spring.data.jpa.service;
- import org.cc11001100.spring.data.jpa.dao.UserDao;
- import org.cc11001100.spring.data.jpa.domain.User;
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.stereotype.Service;
- import java.util.List;
- @Service("userService")
- public class UserServiceImpl implements UserService {
- @Autowired
- private UserDao userDao;
- public User findById(long id) {
- return userDao.findOne(id);
- }
- public User save(User user) {
- return userDao.save(user);
- }
- public List<User> findAll() {
- return userDao.findAll();
- }
- }
测试类:
- package org.cc11001100.spring.data.jpa;
- import org.cc11001100.spring.data.jpa.domain.User;
- import org.cc11001100.spring.data.jpa.service.UserService;
- import org.junit.Test;
- import org.springframework.context.support.ClassPathXmlApplicationContext;
- public class Main_001 {
- @Test
- public void test_001(){
- ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
- UserService userService = ctx.getBean("userService", UserService.class);
- User user=new User();
- user.setUsername("CC11001100");
- user.setPasswd("qwerty");
- userService.save(user);
- }
- }
- MySQL表结构:
- CREATE TABLE t_user(
- id INT PRIMARY KEY AUTO_INCREMENT ,
- username VARCHAR(50) NOT NULL DEFAULT "二狗子" ,
- passwd VARCHAR(100) NOT NULL
- ) CHARSET UTF8;
执行Test:
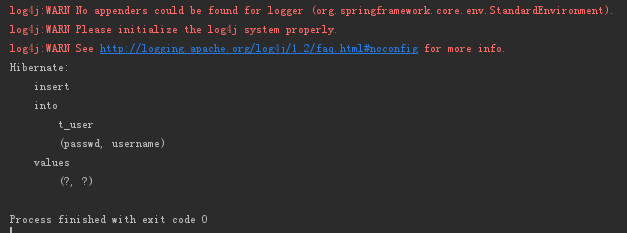
查询MySQL:
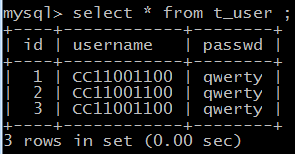
@Entity标识了这是一个JPA实体
如果没有使用@Table注解明确指定要持久化到哪一个表中的话,映射到的表就跟类名相同,比如上面的这个就标识这个类映射到的表是User。
@Table 明确指定这个类要映射到哪一个表。
@Id用来标识主键
Spring Data JPA中的仓库继承关系
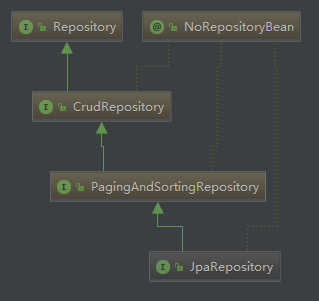
Repository: 是一个标识接口,方便Spring扫描
CrudRepository: 继承Repository,实现了一组CRUD相关的方法
PagingAndSortingRepository: 继承CrudRepository,实现了分页、排序相关的方法
JpaRepository: 继承PagingAndSortingRepository,实现了一组JPA规范相关的方法,一般都是让Dao层接口继承这个接口。
查询规则
声明接口就直接可用是建立在接口方法命名有一定规则的基础上的,Spring Data JPA通过解析方法的名字来推测它到底想干什么从而为其自动生成代码,解析方法名的时候会首先将方法多余的前缀去掉,比如find、findBy、read、readBy、get、getBy等,然后再对剩下的部分进行解析。
如果方法的最后一个参数是Sort或者Pageable,也会做相关的排序、分页处理
方法名表达式查询关键字
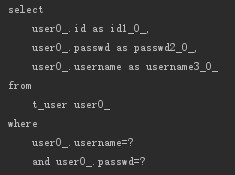
And
相当于SQL中的AND关键字,比如:
- User findUserByUsernameAndPasswd(String username, String passwd);
Or
相当于SQL中的OR关键字,比如:
- List<User> findByUsernameOrNickname(String username, String nickname);
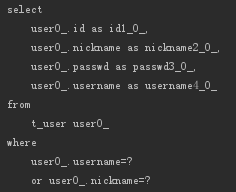
Not
相当于SQL中的!=,比如:
- List<User> findByUsernameNot(String username);
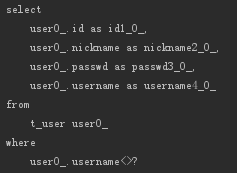
Like
相当于SQL中的LIKE,比如:
- List<User> findByUsernameLike(String usernameLike);
需要注意的是这里的?是整个传的,并不会帮我们自动添加%号,所以传入进去的参数应该自己已经拼接好%号了。
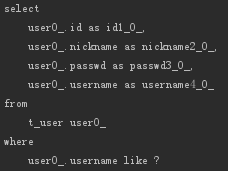
NotLike
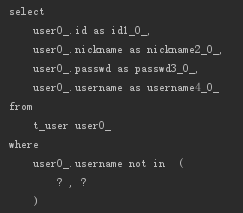
相当于SQL中的NOT LIKE,比如:
- List<User> findByUsernameNotLike(String usernameLike);
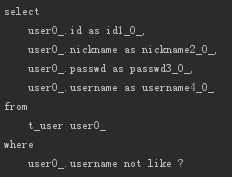
In
相当于SQL语句中的IN,比如:
- List<User> findByUsernameIn(List<String> usernameList);
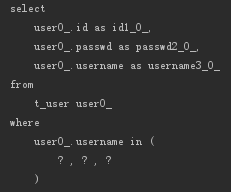
NotIn
相当于SQL语句中的NOT IN,比如:
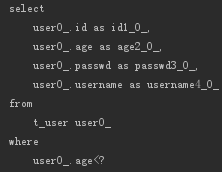
- List<User> findByUsernameNotIn(List<String> usernameList);
LessThan
相当于SQL中的小于号,比如:
- List<User> findByAgeLessThan(int age);
GreaterThan
相当于SQL中的大于号,比如:
- List<User> findByAgeGreaterThan(int age);
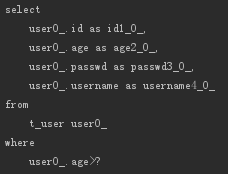
Between
相当于SQL中的BETWEEN关键字,比如:
- List<User> findByAgeBetween(int min, int max);
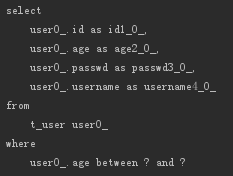
IsNull
相当于SQL中的IS NULL,比如:
- List<User> findByUsernameIsNull();
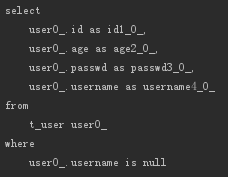
IsNotNull
相当于SQL中的IS NOT NULL,比如:
- List<User> findByUsernameIsNotNull();
NotNull
相当于IsNotNull。
OrderBy
相当于SQL语句中的ORDER BY。
使用IDEA编辑的时候会有自动提示的,复杂的查询都是一个一个的小表达式使用AND或者OR连起来的,基本元素无非就是这些。
创建查询(Query)
上面的查询规则太复杂了,搞得人晕乎乎的,更适合阅读记忆的方式还是使用@Query注解,可以在Dao层接口方法上添加@Query注解,在其中可以书写SQL语句,调用方法的时候会执行此SQL语句。
@Query有一个参数nativeQuery为true的时候表示前面的SQL语句是原生的SQL语句。
在SQL语句中可以引用接口方法传入的参数,可以使用索引位置来引用,比如使用?1来引用接口方法第一个形参的值,使用?2来引用接口方法第二个形参的值,依次类推:
- @Transactional
- @Modifying
- @Query(value="INSERT INTO t_user (username, passwd) VALUES (?1, ?2)", nativeQuery = true)
- int save(String username, String passwd);
还可以使用命名参数来引用,在接口方法的形参加注解@Param传入参数的命名,在SQL语句中可以使用:paramName来引用:
- @Query(value = "SELECT * FROM t_user WHERE id=:id", nativeQuery = true)
- User findById(@Param("id")long id);
需要注意的坑:
1. 使用@Modifying标识的方法返回值只能是void、int/Integer。
2. 进行修改操作的时候需要开启事务,在方法上使用@Transactional来开启事务。
一个使用Query查询的例子:
- package org.cc11001100.spring.data.jpa.dao;
- import org.cc11001100.spring.data.jpa.domain.User;
- import org.springframework.data.jpa.repository.JpaRepository;
- import org.springframework.data.jpa.repository.Modifying;
- import org.springframework.data.jpa.repository.Query;
- import org.springframework.data.repository.query.Param;
- import org.springframework.transaction.annotation.Transactional;
- import java.util.List;
- public interface UserDao extends JpaRepository<User, Long> {
- @Transactional
- @Modifying
- @Query(value="INSERT INTO t_user (username, passwd) VALUES (?1, ?2)", nativeQuery = true)
- int save(String username, String passwd);
- @Transactional
- @Modifying
- @Query(value = "DELETE FROM t_user WHERE id=?1", nativeQuery = true)
- int deleteById(long id);
- @Transactional
- @Modifying
- @Query(value = "UPDATE t_user SET passwd=:passwd WHERE id=:id", nativeQuery = true)
- int updatePasswd(@Param("id") long id, @Param("passwd") String passwd);
- @Query(value = "SELECT * FROM t_user WHERE id=:id", nativeQuery = true)
- User findById(@Param("id")long id);
- @Query(value = "SELECT * FROM t_user", nativeQuery = true)
- List<User> findAll();
- }
命名查询(JPA NameQuery)
使用命名查询就是事先声明好SQL语句,给它一个名字,在使用的时候可以直接用过这个名字来使用它,故称之为命名查询。
使用自定义方法
当默认提供的方法不能满足要求的时候可能就需要自定义方法了,不过一般都是用不到的,Dao只需要简单的执行数据就可以了,与业务相关的放在Service层中。
事务
Spring Data JPA规定在进行写操作的时候必须要开启事务,在方法上使用@Transactional开启事务。
参考资料:
1. Spring Data JPA官方Quick Start http://projects.spring.io/spring-data-jpa/#quick-start
2. 官方文档(英文) http://docs.spring.io/spring-data/jpa/docs/current/reference/html/
3. IBM开发者文档 使用 Spring Data JPA 简化 JPA 开发 https://www.ibm.com/developerworks/cn/opensource/os-cn-spring-jpa/index.html
.
Spring Data JPA笔记的更多相关文章
- SpringBoot学习笔记:Spring Data Jpa的使用
更多请关注公众号 Spring Data Jpa 简介 JPA JPA(Java Persistence API)意即Java持久化API,是Sun官方在JDK5.0后提出的Java持久化规范(JSR ...
- 干货|一文读懂 Spring Data Jpa!
有很多读者留言希望松哥能好好聊聊 Spring Data Jpa!其实这个话题松哥以前零零散散的介绍过,在我的书里也有介绍过,但是在公众号中还没和大伙聊过,因此本文就和大家来仔细聊聊 Spring D ...
- 如何在Spring Data JPA中引入Querydsl
一.环境说明 基础框架采用Spring Boot.Spring Data JPA.Hibernate.在动态查询中,有一种方式是采用Querydsl的方式. 二.具体配置 1.在pom.xml中,引入 ...
- SpringBoot系列之Spring Data Jpa集成教程
SpringBoot系列之Spring Data Jpa集成教程 Spring Data Jpa是属于Spring Data的一个子项目,Spring data项目是一款集成了很多数据操作的项目,其下 ...
- 正确使用Spring Data JPA规范
在优锐课的学习分享中探讨了关于,Spring Data JPA的创建主要是为了通过按方法名称生成查询来轻松创建查询. 但是,有时我们需要创建复杂的查询,而无法利用查询生成器.码了很多知识笔记分享给大家 ...
- 快速搭建springmvc+spring data jpa工程
一.前言 这里简单讲述一下如何快速使用springmvc和spring data jpa搭建后台开发工程,并提供了一个简单的demo作为参考. 二.创建maven工程 http://www.cnblo ...
- spring boot(五):spring data jpa的使用
在上篇文章springboot(二):web综合开发中简单介绍了一下spring data jpa的基础性使用,这篇文章将更加全面的介绍spring data jpa 常见用法以及注意事项 使用spr ...
- 转:使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- 深入浅出学Spring Data JPA
第一章:Spring Data JPA入门 Spring Data是什么 Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map ...
随机推荐
- 【BioCode】删除未算出PSSM与SS的蛋白质序列
代码说明: 由于一些原因(氨基酸序列过长),没有算出PSSM与SS,按照整理出来的未算出特征的文件,删除原来的蛋白质序列: 需删除的氨基酸文件732.txt(共732条氨基酸): 删除前 氨基酸共25 ...
- json_decode遇到的编码问题
初入csdn,就最近遇到的简单问题做一个功能解释; json_encode和json_decode只针对utf8字符有效,如果遇到其他编码比如gbk,需要进行转码然后解析: header(" ...
- 使用vue-cli3新建一个项目,并写好基本配置
1. 使用vue-cli3新建项目: https://cli.vuejs.org/zh/guide/creating-a-project.html 注意,我这里用gitbash不好选择选项,我就用了基 ...
- web_config配置
<configuration> <system.web> <compilation debug="true" targetFramew ...
- Spring boot整合shiro框架(2)
form提交 <form th:action="@{/login}" method="POST"> <div class="form ...
- bzoj2820-GCD
题意 \(T\le 10^4\) 次询问 \(n,m\) ,求 \[ \sum _{i=1}^n\sum _{j=1}^m[gcd(i,j)\text { is prime}] \] 分析 这题还是很 ...
- 洛谷 P2421 A-B数对(增强版)
题目描述 给出N 个从小到大排好序的整数,一个差值C,要求在这N个整数中找两个数A 和B,使得A-B=C,问这样的方案有多少种? 例如:N=5,C=2,5 个整数是:2 2 4 8 10.答案是3.具 ...
- Frequent values UVA - 11235(巧妙地RMQ)
题意: 给出一个非降序排列的整数数组a1.a2,······,an,你的任务是对于一系列询问(i,j),回答ai,ai+1,······,aj中出现次数最多的值所出现的次数 解析: 白书p198 其实 ...
- a++ 和 ++a 的区别
a++ 和 ++a 的区别 1)首先说左值和右值的定义: 变量和文字常量都有存储区,并且有相关的类型.区别在于变量是可寻址的(addressable)对于每一个变量都有两个值与其相联: ...
- 菜鸟在线教你用Unity3D开发VR版的Hello World
大家好,我是菜鸟在线的小编.这篇短文将告诉大家如何用Unity3D开发VR版的Hello World. 1开启SteamVR并连接Vive设备 (a)登录Steam客户端,并点击右上角的VR按钮,这时 ...