java通过url抓取网页数据
在很多行业中,要对行业数据进行分类汇总,及时分析行业数据,对于公司未来的发展,有很好的参照和横向对比。所以,在实际工作,我们可能要遇到数据采集这个概念,数据采集的最终目的就是要获得数据,提取有用的数据进行数据提取和数据分类汇总。
很多人在第一次了解数据采集的时候,可能无从下手,尤其是作为一个新手,更是感觉很是茫然,所以,在这里分享一下自己的心得,希望和大家一起分享技术,如果有什么不足,还请大家指正。写出这篇目的,就是希望大家一起成长,我也相信技术之间没有高低,只有互补,只有分享,才能使彼此更加成长。
在网页数据采集的时候,我们往往要经过这几个大的步骤:
①通过URL地址读取目标网页②获得网页源码③通过网页源码抽取我们要提取的目的数据④对数据进行格式转换,获得我们需要的数据。
这是一个示意图,希望大家了解
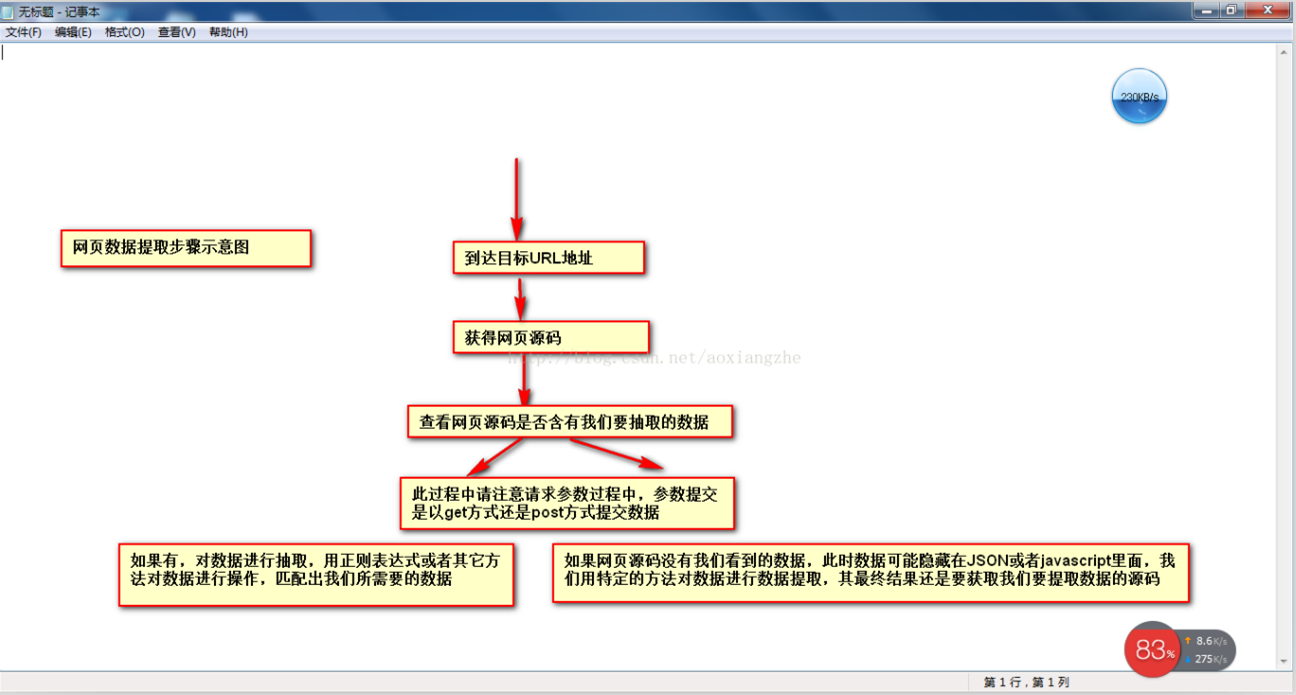
了解了基本流程,下来,我以一个案例具体实现如何提取我们需要的数据,对于数据提取可以用正则表达式进行提取,也可以用httpclient+jsoup进行提取,此处,暂且不讲解httpclient+jsou提取网页数据的做法,以后会对httpclient+jsoup进行专门的讲解,此处,先开始讲解如何用正则表达式对数据进行提取。
我在这里找到一个网站:http://www.ic.NET.cn/userSite/publicQuote/quotes_list.PHP 我们要对里面的数据进行提取操作,我们要提取的最终结果是产品的型号、数量、报价、供应商,首先,我们看到这个网站整个页面预览

其次我们看网页源码结构:
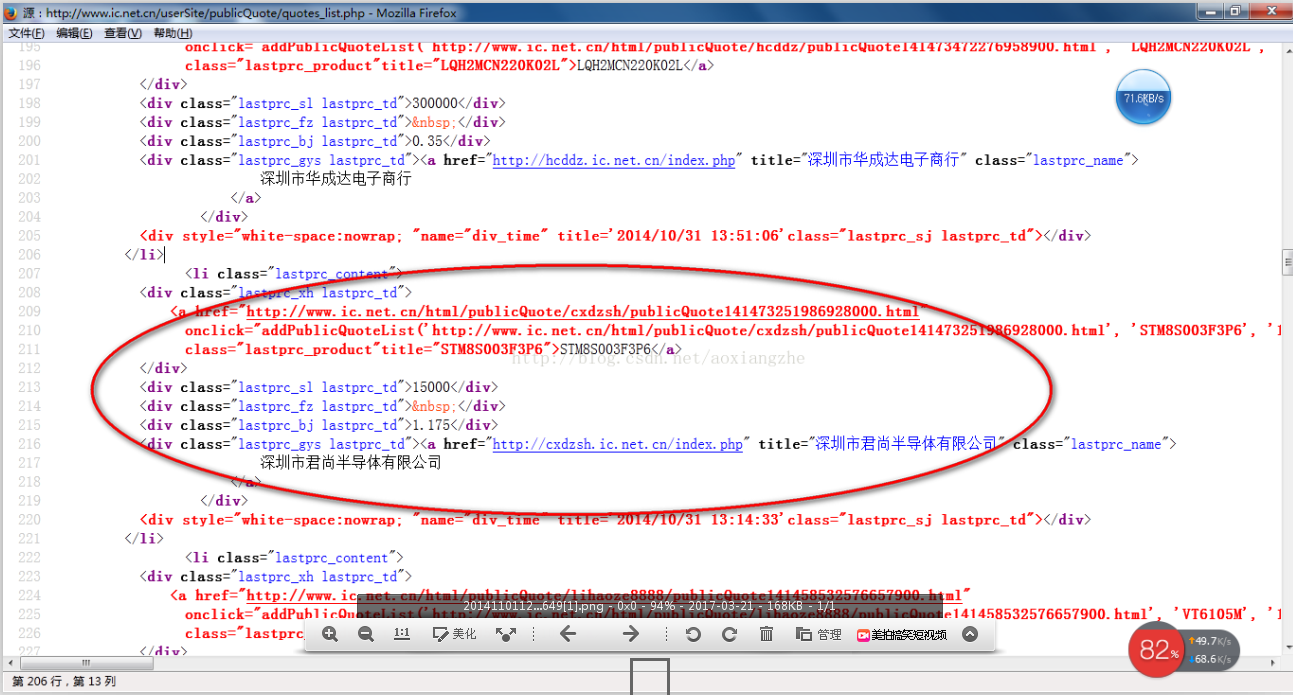
上面源码可以很清楚的可以看到整个网页源码结构,下来我们就对整个网页数据进行提取

import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/publicQuote/quotes_list.php","utf-8");
}
public static List<Product> getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("</?a[^>]*>", "");
//这里是对样式进行处理
line = line.replaceAll("<(\\w+)[^>]*>", "<$1>");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("<div>(.*?)</div>\\s*<div>(.*?)</div>\\s*<div>(.*?)</div>\\s*<div>(.*?)</div>\\s*<div>(.*?)</div>", Pattern.DOTALL);
private static List<Product> getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("</li>");
List<Product> list = new ArrayList<Product>();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
} public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() { }
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
} }
好了,运行上面程序,我们得到下面的数据,就是我们要获得的最终数据

获得数据成功,这就是我们要获得最终的数据结果,最后我要说的是,此处这个网页算是比较简单的,而且,网页源码可以看到源数据,并且此方式是以get方式进行数据提交,真正采集的时候,有些网页结构比较复杂,可能会存在着源码里面没有我们所要提取的数据,关于这一点的解决方式,以后给大家进行介绍。还有,我在采集这个页面的时候,只是采集了当前页面的数据,它还有分页的数据,关于这个我此处不做讲解,只是提示一点,我们可以采用多线程对所有分页的当前数据进行采集,通过线程一个采集当前页面数据,一个进行翻页动作,就可以采集完所有数据。
我们匹配的数据可能在项目实际开发中,要求我们对所提取的数据要进行数据储存,方便我们下一次进行数据的查询操作。
java通过url抓取网页数据的更多相关文章
- java通过url抓取网页数据-----正则表达式
原文地址https://www.cnblogs.com/xiaoMzjm/p/3894805.html [本文介绍] 爬取别人网页上的内容,听上似乎很有趣的样子,只要几步,就可以获取到力所不能及的东西 ...
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
- 使用JAVA抓取网页数据
一.使用 HttpClient 抓取网页数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ...
- 01 UIPath抓取网页数据并导出Excel(非Table表单)
上次转载了一篇<UIPath抓取网页数据并导出Excel>的文章,因为那个导出的是table标签中的数据,所以相对比较简单.现实的网页中,有许多不是通过table标签展示的,那又该如何处理 ...
- 使用HtmlAgilityPack批量抓取网页数据
原文:使用HtmlAgilityPack批量抓取网页数据 相关软件点击下载登录的处理.因为有些网页数据需要登陆后才能提取.这里要使用ieHTTPHeaders来提取登录时的提交信息.抓取网页 Htm ...
- c#抓取网页数据
写了一个简单的抓取网页数据的小例子,代码如下: //根据Url地址得到网页的html源码 private string GetWebContent(string Url) { string strRe ...
- 【iOS】正則表達式抓取网页数据制作小词典
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/xn4545945/article/details/37684127 应用程序不一定要自己去提供数据. ...
- Asp.net 使用正则和网络编程抓取网页数据(有用)
Asp.net 使用正则和网络编程抓取网页数据(有用) Asp.net 使用正则和网络编程抓取网页数据(有用) /// <summary> /// 抓取网页对应内容 /// </su ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
随机推荐
- windows2003 iis6.0站点打不开,找不到服务器或 DNS 错误【转】
最近服务器经常出现打不开网站的现象,有时出现在上午,有时出现在中午,几乎天天都会出现一次,出现问题时,无论是回收程序池还是重启IIS或者关闭其它一些可能有影响的服务,都不能解决问题.网站打不开时,有如 ...
- Android 开发之环境搭建-0
Android 开发环境安装与配置 一.开发工具介绍 要进行Android应用程序开发,最起码要有两个工具,一个是Android SDK,它不仅为开发人员提供了丰富的编程接口,而且提供了相关的调试工具 ...
- 【BZOJ】1642: [Usaco2007 Nov]Milking Time 挤奶时间(dp)
http://www.lydsy.com/JudgeOnline/problem.php?id=1642 果然没能仔细思考是不行的.. 以后要静下心来好好想,不要认为不可做..... 看了题解... ...
- 小结:STL
概要: c++的stl是个神奇的东西,需要好好学习. 技巧及注意: lower_bound是第一个大于等于要查找值 upper_bound是第一个大于要查找的值 stl中的容器中的比较几乎全都用< ...
- Swift AVFoundation 二维码扫描和生成
项目最终不须要支持iOS6了(泪崩),在二维码扫描这一块,可以全然的放弃ZXing库,改用系统的AVFoundation了,拿swift写了个Demo,效果例如以下: github地址:点这里 有关A ...
- jquery widgets grid 重置列配置
$("#jqxGridByAttendanceDetail").on("bindingcomplete", function (event) { // your ...
- MySQL之explain 的type列 & Extra列
explain 可以分析 select 语句的执行,即 MySQL 的“执行计划. 一.type 列 MySQL 在表里找到所需行的方式.包括(由左至右,由最差到最好): | All | inde ...
- ActiveMQ搭建
下载 到ActiveMQ官网,找到下载点. 目前, 官网为http://activemq.apache.org/ Linux版本下载点之一为:http://apache.fayea.com/activ ...
- mac os x 记录 转载
转载:远景网友(手机锋友t5sd3sf):http://bbs.feng.com/read-htm-tid-10434256.html 一个命令制作 OS X 原版安装U盘 1.要保证下载的原版安装包 ...
- MyEclipse------如何添加jspsmartupload.jar,用于文件上传
方法: 右键“Web”工程->properties->Libraries->Add External JARs...->找到“jspsmartupload.jar”,添加进去 ...