OCR技术浅探 : 文字定位和文本切割(2)
文字定位
经过前面的特征提取,我们已经较好地提取了图像的文本特征,下面进行文字定位。 主要过程分两步:
1、邻近搜索,目的是圈出单行文字;
2、文本切割,目的是将单行文本切割为单字。
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字。 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元” 这些字,由于不具有连通性,所以就被分拆开了,如图13。 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域。

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开。
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来.。如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了。因此,我们只允许区域向单一的一个方向膨胀。我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形。 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向。
既然涉及到了邻近,那么就需要有距离的概念。下面给出一个比较合理的距离的定义。
距离

图14 两个示例区域
如上图,通过左上角坐标(x,y)和右下角坐标(z,w)就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的。 这个区域的中心是( (x+z) / 2, (y+w) / 2 )。对于图中的两个区域S和S′,可以计算它们的中心向量差

如果直接使用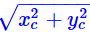 作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点。因此,需要减去区域的长度:
作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点。因此,需要减去区域的长度:

距离定义为

至于方向,由 的幅角进行判断即可。
的幅角进行判断即可。
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形。 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作。
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域。 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合。
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15。

图15 通过邻近搜索后,圈出的文字区域
文本切割
经过前面文字定位得到单行的文本区域之后,我们就可以想办法将单行的文本切割为单个的字符了。因为第三步的模型师针对单个的字符建立的,因此这一步也是必须的。
均匀切割
基于方块汉字的假设,事实上最简单的切割方法是均匀切割,也就是说不加任何判断,直接按照高度来将单行文本切割为一个个的正方形图片。这种思路可以应对大部分的单行文本,如下图。

当然,均匀切割的弊端也是很明显的。 大多数汉字都是方块汉字,但多数英语和数字都不是,因此如果出现中英文混排的时候,均匀切割就失效了,如上图。
统计切割
从图15中可以看出,经过前面的操作,字与字都被很好地分离开了。 因此,另外一种比较简单的思路是对单行的文字图片进行垂直方向的求和,和为0的所在的列就是被切割的的列。
用这种统计的思路可以很好地解决中英文混排的单行文字图片分割的问题,但是它也存在一定的弊端。 最明显的就是诸如“小”、“的”等字就被切割开为两部分了。
前后比较
一个更好的思路是结合前面两部分结果,通过比较前后两部分区域是否组成方形来确定是否切割。 具体步骤是:
1。 通过统计求和的思路,得出候选的切割线;
2。 如果该候选切割线到左右两条候选切割线的距离之和超过宽长度的1。2倍,那么该候选切割线确定为切割线;
3。 如果得到的区域是一个明显的长条矩形,并且没办法按照上面两个步骤切割,那个就均匀切割。
这三个步骤比较简单,基于两个假设:
1、数字、英文字符的底与高之比大于60%;
2、汉字的底与高之比低于1.2。经过测试,该算法可以很好地用于前面步骤所提取的图片文本特征的分割。
OCR技术浅探 : 文字定位和文本切割(2)的更多相关文章
- OCR技术浅探:基于深度学习和语言模型的印刷文字OCR系统
作者: 苏剑林 系列博文: 科学空间 OCR技术浅探:1. 全文简述 OCR技术浅探:2. 背景与假设 OCR技术浅探:3. 特征提取(1) OCR技术浅探:3. 特征提取(2) OCR技术浅探:4. ...
- OCR技术浅探(转)
网址:https://spaces.ac.cn/archives/3785 OCR技术浅探 作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行 ...
- OCR技术浅探: 光学识别(3)
经过前面的文字定位和文本切割,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别. 模型选择 在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了 ...
- OCR技术浅探:特征提取(1)
研究背景 关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不 ...
- OCR技术浅探: 语言模型和综合评估(4)
语言模型 由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方 ...
- OCR技术浅探: 语言模型(4)
由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一. ...
- OCR技术浅探:Python示例(5)
文件说明: 1. image.py——图像处理函数,主要是特征提取: 2. model_training.py——训练CNN单字识别模型(需要较高性能的服务器,最好有GPU加速,否则真是慢得要死): ...
- 【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
文字识别分为两个具体步骤:文字的检测和文字的识别,两者缺一不可,尤其是文字检测,是识别的前提条件,若文字都找不到,那何谈文字识别.今天我们首先来谈一下当今流行的文字检测技术有哪些. 文本检测不是一件简 ...
- 【转】腾讯OCR—自动识别技术,探寻文字真实的容颜
文字,一种信息记录的图像符号,千年来承载了太多的人类文明印记.OCR,一种自动解读这种图像符号的技术,一直以来都备受关注.尤其在信息时代的今天,数字图像纷繁复杂,如何便捷高效的获取其中的文字信息,更有 ...
随机推荐
- 10 部署应用程序和applet
跳过 09 Swing用户界面组件 JAR文件 在将应用程序进行打包时, 使用者一定希望仅提供给其一个单独的文件, 而不是一个含有大量类文件的目录, Java归档(JAR)文件就是为此目的而设计的. ...
- Java-----多线程sleep(),join(),interrupt(),wait(),notify()的作用
关于Java多线程知识可以看看<Thinking in Java >中的多线程部分和<Java网络编程>中第5章多线程的部分 以下是参考<<Java多线程模式> ...
- 【mysql】一次有意思的数据库查询分析。
本文是在做一家汽车配件的电商网站时,大体情景是一个List.php页面,该页面分页列出部分配件并统计总数量用于分页. 当然该页面中也可以指定一下查询条件,如适配的车辆品牌.车系.排量.年份等,一件商品 ...
- php中判断一个字符是否在字符串中
strpos() - 查找字符串在另一字符串中第一次出现的位置(区分大小写) stripos() - 查找字符串在另一字符串中第一次出现的位置(不区分大小写) strrpos() - 查找字符串在另一 ...
- hdu 2105:The Center of Gravity(计算几何,求三角形重心)
The Center of Gravity Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- hdu 1756:Cupid's Arrow(计算几何,判断点在多边形内)
Cupid's Arrow Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tot ...
- Spring security UserDetailsService autowired注入失败错误
最近使用spring mvc + spring security 实现登录权限控制的时候,一直不能成功登录,检查过后是dao一直无法注入为null CustomUserDetailConfig.jav ...
- Tanks案例笔记(一、场景搭建)
一.场景搭建 1.首先我们导入案例的资源,然后新建一个空场景: 2.资源中为我们准备的场景的预制,我们直接把LevelArt预制拖到Hierarchy面板: 3.移除场景中默认的光源: 4.确保物体的 ...
- nyoj1237 最大岛屿(河南省第八届acm程序设计大赛)
题目1237 pid=1237" style="color:rgb(55,119,188)">题目信息 执行结果 本题排行 讨论区 最大岛屿 时间限制:1000 m ...
- Deep Learning的基本思想
假设我们有一个系统S,它有n层(S1,…Sn),它的输入是I,输出是O,形象地表 示为: I =>S1=>S2=>…..=>Sn => O,如果输出O等于输入I,即输入I ...