Machine Learning系列--归一化方法总结
一、数据的标准化(normalization)和归一化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
1.1 归一化的目标:统一量纲
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。 比如,复数阻抗可以归一化书写:$Z=R+j\omega L=R(1+j\omega L/R)$,复数部分变成了纯数量了,没有量纲。
另外,微波之中也就是电路分析、信号系统、电磁波传输等,有很多运算都可以如此处理,既保证了运算的便捷,又能凸现出物理量的本质含义。
1.2 归一化后有两个好处
1. 提升模型的收敛速度
如下图,$x_1$的取值为0-2000,而$x_2$的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快(理解:也就是步长走多走少方向总是对的,不会走偏)。
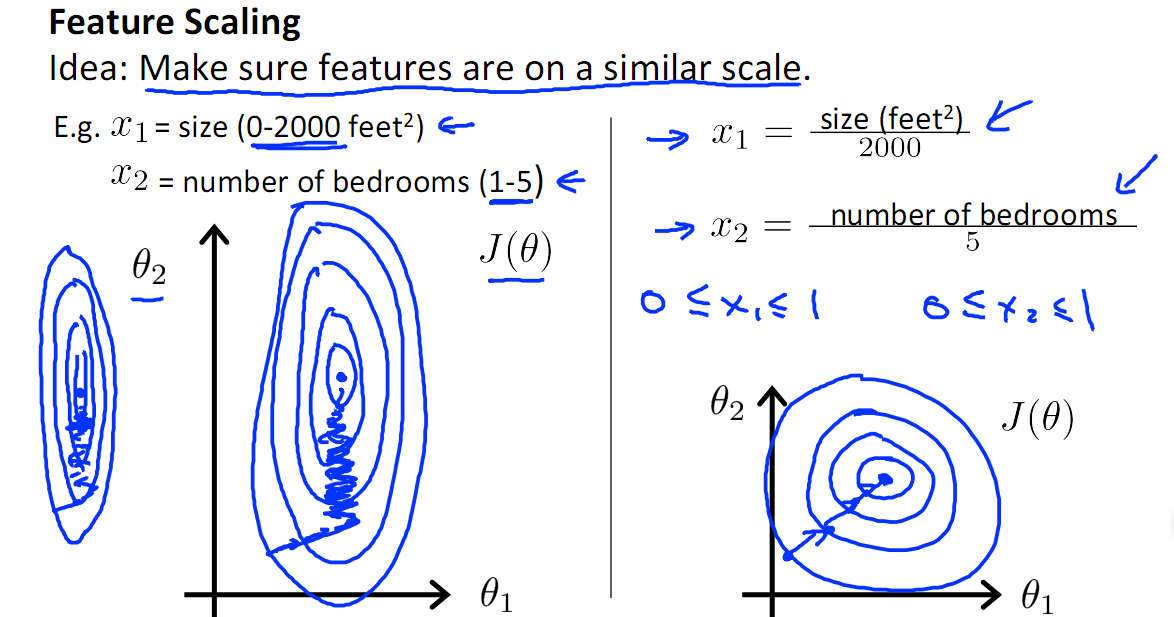
2.提升模型的精度
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中$x_2$的取值范围比较小,涉及到距离计算时其对结果的影响远比$x_1$带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
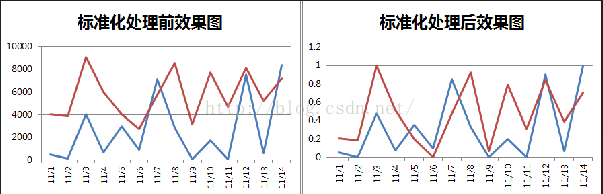
3. 深度学习中数据归一化可以防止模型梯度爆炸。
二、数据需要归一化的机器学习算法
1. 需要归一化的模型:
有些模型在各个维度进行不均匀伸缩后,最优解与原来不等价,例如SVM(距离分界面远的也拉近了,支持向量变多?)。对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据dominate。2. 有些模型在各个维度进行不均匀伸缩后,最优解与原来等价,例如logistic regression(因为θ的大小本来就自学习出不同的feature的重要性吧?)。对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛。所以对于具有伸缩不变性的模型,最好也进行数据标准化。
2. 不需要归一化的模型:
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、rf。而像adaboost、gbdt、xgboost、svm、lr、KNN、KMeans之类的最优化问题就需要归一化。
三、常见的数据归一化方法
3.1 min-max标准化(Min-max normalization)/0-1标准化(0-1 normalization)/线性函数归一化/离差标准化
对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
$${x^ * } = \frac{{x - {x_{min}}}}{{{x_{max}} - {x_{min}}}}.$$
其中$x_{max}$为样本数据的最大值,$x_{min}$为样本数据的最小值。
这种方法有一个缺陷就是当有新数据加入时,可能导致$x_{max}$和$x_{min}$的变化,需要重新定义。
3.2 z-score 标准化(zero-mean normalization)
最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。
也叫标准差标准化,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
$$ {x^* } = \frac{{x - \mu }}{\sigma }. $$
这两种最常用方法使用场景:
1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
原因是使用第一种方法(线性变换后),其协方差产生了倍数值的缩放,因此这种方式无法消除量纲对方差、协方差的影响,对PCA分析影响巨大;同时,由于量纲的存在,使用不同的量纲、距离的计算结果会不同。
而在第二种归一化方式中,新的数据由于对方差进行了归一化,这时候每个维度的量纲其实已经等价了,每个维度都服从均值为0、方差1的正态分布,在计算距离的时候,每个维度都是去量纲化的,避免了不同量纲的选取对距离计算产生的巨大影响。
线性变换后协方差产生倍数值缩放推导如下:
假设数据为2个维度$(X, Y)$,为方便分析,取线性系数$c$,线性变换后的$x'$和$y'$分别为:
$$x' = {c_x} \cdot x.$$
$$y' = {c_y} \cdot y.$$
计算协方差:
$${{\sigma '}_{xy}} = \frac{1}{n}\sum\limits_{i = 1}^n {\left( {{c_x}{x_i} - {c_x}\bar x} \right)} \left( {{c_y}{y_i} - {c_y}\bar y} \right) = {c_x}{c_y}{\sigma _{xy}} \ne {\sigma _{xy}}.$$
可以看到,使用第一种方法(线性变换后),其协方差产生了${c_x}{c_y}$倍的缩放。
3.3 log函数转换
通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下:
$${x^ * } = \frac{{{{log }_{10}}\left( x \right)}}{{{{log }_{10}}\left( {{x_{max }}} \right)}}.$$
看了下网上很多介绍都是${x^ * } = {log _{10}}\left( x \right)$,其实是有问题的,这个结果并非一定落到[0,1]区间上,应该还要除以${log _{10}}\left( {{x_{max }}} \right)$,$x_{max }$为样本数据最大值,并且所有的数据都要大于等于1。
3.4 atan函数转换
用反正切函数也可以实现数据的归一化:
$$ {x^ * } = \frac{{atan \left( x \right) * 2}}{\pi }. $$
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上,而并非所有数据标准化的结果都映射到[0,1]区间上。
3.5 Decimal scaling小数定标标准化
这种方法通过移动数据的小数点位置来进行标准化。小数点移动多少位取决于属性$A$的取值中的最大绝对值。
将属性$A$的原始值$x$使用decimal scaling标准化到$x^ * $的计算方法是:
$$x^ * =\frac{x}{10^j}.$$
其中,$j$是满足条件的最小整数。
例如,假定$A$的值由-986到917,$A$的最大绝对值为986,为使用小数定标标准化,我们用每个值除以1000(即,$j=3$),这样,-986被规范化为-0.986。
注意,标准化会对原始数据做出改变,因此需要保存所使用的标准化方法的参数,以便对后续的数据进行统一的标准化。
3.6 模糊量化模式
$$ {x^ * } = \frac{1}{2} + \frac{1}{2} \cdot sin \left( {\frac{{x - \frac{{{x_{max }} - {x_{min }}}}{2}}}{{{x_{max }} - {x_{min }}}} \cdot \pi } \right). $$
参考博客:
1. 数据标准化/归一化normalization:https://blog.csdn.net/pipisorry/article/details/52247379.
Machine Learning系列--归一化方法总结的更多相关文章
- Machine Learning系列--CRF条件随机场总结
根据<统计学习方法>一书中的描述,条件随机场(conditional random field, CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出 ...
- Machine Learning系列--隐马尔可夫模型的三大问题及求解方法
本文主要介绍隐马尔可夫模型以及该模型中的三大问题的解决方法. 隐马尔可夫模型的是处理序列问题的统计学模型,描述的过程为:由隐马尔科夫链随机生成不可观测的状态随机序列,然后各个状态分别生成一个观测,从而 ...
- Machine Learning系列--L0、L1、L2范数
今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大,为了不吓到大家,我将这个五个 ...
- Machine Learning系列--EM算法理解与推导
EM算法,全称Expectation Maximization Algorithm,译作最大期望化算法或期望最大算法,是机器学习十大算法之一,吴军博士在<数学之美>书中称其为“上帝视角”算 ...
- Machine Learning系列--维特比算法
维特比算法(Viterbi algorithm)是在一个用途非常广的算法,本科学通信的时候已经听过这个算法,最近在看 HMM(Hidden Markov model) 的时候也看到了这个算法.于是决定 ...
- Machine Learning系列--TF-IDF模型的概率解释
信息检索概述 信息检索是当前应用十分广泛的一种技术,论文检索.搜索引擎都属于信息检索的范畴.通常,人们把信息检索问题抽象为:在文档集合D上,对于由关键词w[1] ... w[k]组成的查询串q,返回一 ...
- Machine Learning系列--判别式模型与生成式模型
监督学习的任务就是学习一个模型,应用这一模型,对给定的输入预测相应的输出.这个模型的一般形式为决策函数:$$ Y=f(X) $$或者条件概率分布:$$ P(Y|X) $$监督学习方法又可以分为生成方法 ...
- Machine Learning系列--深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
在求取有约束条件的优化问题时,拉格朗日乘子法(Lagrange Multiplier) 和KKT条件是非常重要的两个求取方法,对于等式约束的优化问题,可以应用拉格朗日乘子法去求取最优值:如果含有不等式 ...
- 【机器学习|数学基础】Mathematics for Machine Learning系列之线性代数(1):二阶与三阶行列式、全排列及其逆序数
@ 目录 前言 二阶与三阶行列式 二阶行列式 三阶行列式 全排列及其逆序数 全排列 逆序数 结语 前言 Hello!小伙伴! 非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出- 自我介绍 ...
随机推荐
- Java Machine Learning Tools & Libraries--转载
原文地址:http://www.demnag.com/b/java-machine-learning-tools-libraries-cm570/?ref=dzone This is a list o ...
- CF708C-Centroids
题目 一棵树的重心定义为一个点满足删除这个点后最大的连通块大小小于等于原来这颗树大小的一半. 给出一棵树,一次操作为删除一条边再添加一条边,操作结束后必须仍为一棵树.问这颗树的每个点是否可以通过一次操 ...
- Eclipse中使用git提交代码,报错Testng 运行Cannot find class in classpath的解决方案
一.查找原因方式 1.点击Project——>Clear...——>Build Automatically 2.查看问题 二.报错因素 1.提交.xlsx文件 2.提交时,.xlsx文件被 ...
- [CTSC2012]熟悉的文章 后缀自动机
题面:洛谷 题解: 观察到L是可二分的,因此我们二分L,然后就只需要想办法判断这个L是否可行即可. 因为要尽量使L可行,因此我们需要求出对于给定L,这个串最多能匹配上多少字符. 如果我们可以对每个位置 ...
- 【POJ2891】Strange Way to Express Integers(拓展CRT)
[POJ2891]Strange Way to Express Integers(拓展CRT) 题面 Vjudge 板子题. 题解 拓展\(CRT\)模板题. #include<iostream ...
- 小Q与内存
Portal --> broken qwq Description (这个描述好像怎么都精简不起来啊qwq) 大概是说你的计算机有1GB的物理内存,按照Byte寻址,其物理地址空间为\(0\si ...
- 【题解】Inspection UVa 1440 LA 4597 NEERC 2009
题目传送门:https://vjudge.net/problem/UVA-1440 看上去很像DAG的最小路径覆盖QwQ? 反正我是写了一个上下界网络流,建模方法清晰易懂. 建立源$s$,向每个原图中 ...
- 微信小程序语音识别
语音识别现在已经发展的很成熟了,经过比对发现百度对开发者比较友好,提供很多种语言的SDK,对python来说直接安装 pip install baidu-aip 文档写的也不错 具体参考:http: ...
- Java基础之equals() 和 hashCode()
equals()是Object中的一个方法: public boolean equals(Object obj) { return (this == obj); } 在Object中equals()方 ...
- OpenCV---人脸检测
一:相关依赖文件下载 https://github.com/opencv/opencv 二:实现步骤(图片检测) (一)读取图片 image= cv.imread("./d.png&qu ...