Storm-源码分析-Topology Submit-Nimbus-mk-assignments
什么是"mk-assignment”, 主要就是产生executor->node+port关系, 将executor分配到哪个node的哪个slot上(port代表slot, 一个slot可以run一个worker进程, 一个worker包含多个executor线程)
先搞清什么是executor, 参考Storm-源码分析- Component ,Executor ,Task之间关系
;; get existing assignment (just the executor->node+port map) -> default to {}
;; filter out ones which have a executor timeout
;; figure out available slots on cluster. add to that the used valid slots to get total slots. figure out how many executors should be in each slot (e.g., 4, 4, 4, 5)
;; only keep existing slots that satisfy one of those slots. for rest, reassign them across remaining slots
;; edge case for slots with no executor timeout but with supervisor timeout... just treat these as valid slots that can be reassigned to. worst comes to worse the executor will timeout and won't assign here next time around
(defnk mk-assignments [nimbus :scratch-topology-id nil]
(let [conf (:conf nimbus)
storm-cluster-state (:storm-cluster-state nimbus)
^INimbus inimbus (:inimbus nimbus)
;; 1. 读出所有active topology信息 (read all the topologies)
topology-ids (.active-storms storm-cluster-state) ;;读出所有topology的ids
topologies (into {} (for [tid topology-ids]
{tid (read-topology-details nimbus tid)})) ;;{tid, TopologyDetails.}
topologies (Topologies. topologies)
;; 2. 读出当前的assignemnt情况(read all the assignments)
assigned-topology-ids (.assignments storm-cluster-state nil) ;;已经被assign的tids
existing-assignments (into {} (for [tid assigned-topology-ids]
;; for the topology which wants rebalance (specified by the scratch-topology-id)
;; we exclude its assignment, meaning that all the slots occupied by its assignment
;; will be treated as free slot in the scheduler code.
(when (or (nil? scratch-topology-id) (not= tid scratch-topology-id))
{tid (.assignment-info storm-cluster-state tid nil)})))
;;3. 根据取到的Topology和Assignement情况, 对当前topology进行新的assignment (make the new assignments for topologies)
topology->executor->node+port (compute-new-topology->executor->node+port
nimbus
existing-assignments
topologies
scratch-topology-id)
now-secs (current-time-secs)
basic-supervisor-details-map (basic-supervisor-details-map storm-cluster-state)
;; construct the final Assignments by adding start-times etc into it
new-assignments (into {} (for [[topology-id executor->node+port] topology->executor->node+port
:let [existing-assignment (get existing-assignments topology-id)
all-nodes (->> executor->node+port vals (map first) set)
node->host (->> all-nodes
(mapcat (fn [node]
(if-let [host (.getHostName inimbus basic-supervisor-details-map node)]
[[node host]]
)))
(into {}))
all-node->host (merge (:node->host existing-assignment) node->host)
reassign-executors (changed-executors (:executor->node+port existing-assignment) executor->node+port)
start-times (merge (:executor->start-time-secs existing-assignment)
(into {}
(for [id reassign-executors]
[id now-secs]
)))]]
{topology-id (Assignment.
(master-stormdist-root conf topology-id)
(select-keys all-node->host all-nodes)
executor->node+port
start-times)}))]
;; tasks figure out what tasks to talk to by looking at topology at runtime
;; only log/set when there's been a change to the assignment
(doseq [[topology-id assignment] new-assignments
:let [existing-assignment (get existing-assignments topology-id)
topology-details (.getById topologies topology-id)]]
(if (= existing-assignment assignment)
(log-debug "Assignment for " topology-id " hasn't changed")
(do
(log-message "Setting new assignment for topology id " topology-id ": " (pr-str assignment))
(.set-assignment! storm-cluster-state topology-id assignment)
)))
(->> new-assignments
(map (fn [[topology-id assignment]]
(let [existing-assignment (get existing-assignments topology-id)]
[topology-id (map to-worker-slot (newly-added-slots existing-assignment assignment))]
)))
(into {})
(.assignSlots inimbus topologies))
))
1. 读出所有active topology信息
先使用active-storms去zookeeper上读到所有active的topology的ids
然后使用read-topology-details读出topology的更多的详细信息,
并最终封装成TopologyDetails, 其中包含关于topology的所有信息, 包含id, conf, topology对象, work数, component和executor关系
(active-storms [this]
(get-children cluster-state STORMS-SUBTREE false) ;"/storms”
)
(defn read-topology-details [nimbus storm-id]
(let [conf (:conf nimbus)
storm-base (.storm-base (:storm-cluster-state nimbus) storm-id nil) ;从zookeeper读出storm-base的内容
topology-conf (read-storm-conf conf storm-id) ;从storm本地目录中读出topology的配置
topology (read-storm-topology conf storm-id) ;从storm本地目录中读出topology的对象(反序列化)
executor->component (->> (compute-executor->component nimbus storm-id) ;读出executor和component的对应关系
(map-key (fn [[start-task end-task]]
(ExecutorDetails. (int start-task) (int end-task)))))] ;将executor封装成ExecutorDetials对象
(TopologyDetails. storm-id
topology-conf
topology
(:num-workers storm-base)
executor->component
)))
最终将topologies信息, 封装成Topologies, 提供根据tid或name的对topology的检索
public class Topologies {
Map<String, TopologyDetails> topologies;
Map<String, String> nameToId;
}
2. 读出当前的assignemnt情况
从Assignment的定义可以看出, Assignment主要就是executor和host+port的对应关系
(defrecord Assignment [master-code-dir node->host executor->node+port executor->start-time-secs])
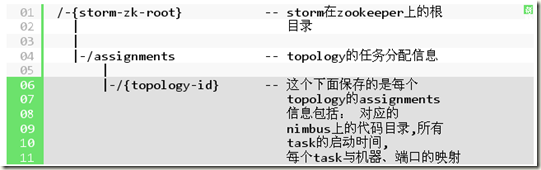
StormClusterState相关的都是去Zookeeper上面读写数据
(reify
StormClusterState
(assignments [this callback]
(when callback
(reset! assignments-callback callback))
(get-children cluster-state ASSIGNMENTS-SUBTREE (not-nil? callback))) ;/assignments
)
读出所有/assignments下面的topology信息
assigned-topology-ids (.assignments storm-cluster-state nil) ;读出所有的topology ids
existing-assignments (into {} (for [tid assigned-topology-ids] ;根据topologyid, 读出具体的信息(scratch topology概念,需要rebalance的topology,当前assignment都已经无效, 所以不需要读)
;; for the topology which wants rebalance (specified by the scratch-topology-id)
;; we exclude its assignment, meaning that all the slots occupied by its assignment
;; will be treated as free slot in the scheduler code.
(when (or (nil? scratch-topology-id) (not= tid scratch-topology-id))
{tid (.assignment-info storm-cluster-state tid nil)})))
3. 根据取到的Topology和Assignement情况, 对当前topology进行新的assignment
主要就是调用compute-new-topology->executor->node+port, 在真正调用scheduler.schedule 之前, 需要做些准备工作
3.1 ~3.6, topology assignment情况
a. 从zk获取topology中executors的assignment信息, 但是assignment是静态信息.
我们还需要知道, assign完后这些executor是否在工作, 更新executor的hb, 并找出alive-executors, 这部分assignment才是有效的assignment, 所以仅仅将alive-executors封装生成topology->scheduler-assignment
b. 在check topology assignment中, 发现的dead slot
对于那些没有hb的executor, 我们认为是slot产生了问题, 称为dead slot, 后面需要避免再往dead slot分配executor (dead slot可能有alive-executors存在)
3.7~3.8, supervisor的情况
根据supervisor的hb, 获取当前alive的supervisor的状况SupervisorDetails, 主要是hostname, 和allports(配置的ports – dead slots)
3.9, cluster, topology的运行态信息, 包含上面的两点信息
cluster (Cluster. (:inimbus nimbus) supervisors topology->scheduler-assignment)
(defn compute-new-topology->executor->node+port [nimbus existing-assignments topologies scratch-topology-id]
(let [conf (:conf nimbus)
storm-cluster-state (:storm-cluster-state nimbus)
;;3.1 取出所有已经assignment的topology的executors信息
;;所有已经assignment的Topology所包含的executor, {t1 #([1 2] [3 3]), t2 #([1 2] [3 3])}
topology->executors (compute-topology->executors nimbus (keys existing-assignments));;只包含存在assignment信息的, 所以新的或scratch Topology都不算
;;3.2 更新所有executors的heartbeats cache(更新nimbus-data的heartbeats-cache)
;; update the executors heartbeats first.
_ (update-all-heartbeats! nimbus existing-assignments topology->executors) ;;只是为了在let中提前调用update-all-heartbeats!, 所以使用'_'
;; 3.3 过滤topology->executors, 保留alive的
topology->alive-executors (compute-topology->alive-executors nimbus
existing-assignments
topologies
topology->executors
scratch-topology-id)
;;3.4 找出dead slots
supervisor->dead-ports (compute-supervisor->dead-ports nimbus
existing-assignments
topology->executors
topology->alive-executors)
;;3.5 生成alive executor的SchedulerAssignment
topology->scheduler-assignment (compute-topology->scheduler-assignment nimbus
existing-assignments
topology->alive-executors)
;;3.6 找出missing-assignment-topologies, 需要从新assign
missing-assignment-topologies (->> topologies
.getTopologies ;;返回TopologyDetials.
(map (memfn getId)) ;;get topologyid
(filter (fn [t]
(let [alle (get topology->executors t)
alivee (get topology->alive-executors t)]
(or (empty? alle)
(not= alle alivee)
(< (-> topology->scheduler-assignment
(get t)
num-used-workers )
(-> topologies (.getById t) .getNumWorkers)
))
))))
;;3.7 all-scheduling-slots, 找出所有supervisor在conf中已配置的slots
all-scheduling-slots (->> (all-scheduling-slots nimbus topologies missing-assignment-topologies)
(map (fn [[node-id port]] {node-id #{port}}))
(apply merge-with set/union))
;;3.8 生成所有supervisors的SupervisorDetails
supervisors (read-all-supervisor-details nimbus all-scheduling-slots supervisor->dead-ports)
;;3.9 生成cluster
cluster (Cluster. (:inimbus nimbus) supervisors topology->scheduler-assignment) ;;3.10 call scheduler.schedule to schedule all the topologies
;; the new assignments for all the topologies are in the cluster object.
_ (.schedule (:scheduler nimbus) topologies cluster)
new-scheduler-assignments (.getAssignments cluster)
;; add more information to convert SchedulerAssignment to Assignment
new-topology->executor->node+port (compute-topology->executor->node+port new-scheduler-assignments)]
;; print some useful information.
(doseq [[topology-id executor->node+port] new-topology->executor->node+port
:let [old-executor->node+port (-> topology-id
existing-assignments
:executor->node+port)
reassignment (filter (fn [[executor node+port]]
(and (contains? old-executor->node+port executor)
(not (= node+port (old-executor->node+port executor)))))
executor->node+port)]]
(when-not (empty? reassignment)
(let [new-slots-cnt (count (set (vals executor->node+port)))
reassign-executors (keys reassignment)]
(log-message "Reassigning " topology-id " to " new-slots-cnt " slots")
(log-message "Reassign executors: " (vec reassign-executors))))) new-topology->executor->node+port))
3.1 取出所有已经assignment的topology的executors信息
这里的实现有些问题, compute-topology->executors会调用compute-executors重新计算一般, 其实从topologies里面直接就可以取到
3.2 更新所有executors的heartbeats cache(更新nimbus-data的heartbeats-cache)
具体过程是, 从Zookeeper通过get-worker-heartbeat读出所有executors最新的heartbeats信息(通过executor->node+port可以对应到worker), 并使用swap!将最新的heartbeats信息更新到nimbus的全局变量heartbeats-cache中
3.3 过滤topology->executors, 保留alive的
调用compute-topology->alive-executors
(defn- compute-topology->alive-executors [nimbus existing-assignments topologies topology->executors scratch-topology-id]
"compute a topology-id -> alive executors map"
(into {} (for [[tid assignment] existing-assignments
:let [topology-details (.getById topologies tid)
all-executors (topology->executors tid)
alive-executors (if (and scratch-topology-id (= scratch-topology-id tid));;这里其实不会出现scratch-topology, 前面都已经过滤过
all-executors
(set (alive-executors nimbus topology-details all-executors assignment)))]]
{tid alive-executors})))
调用alive-executors, 来通过刚刚更新的heartbeats cache来判断executor是否alive
(->> all-executors
(filter (fn [executor]
(let [start-time (get executor-start-times executor)
nimbus-time (-> heartbeats-cache (get executor) :nimbus-time)]
(if (and start-time
(or
(< (time-delta start-time)
(conf NIMBUS-TASK-LAUNCH-SECS))
(not nimbus-time)
(< (time-delta nimbus-time)
(conf NIMBUS-TASK-TIMEOUT-SECS))
))
true
(do
(log-message "Executor " storm-id ":" executor " not alive")
false))
)))
doall))) ;doall很重要, 确保真正filter每个executor, 否则只会产生lazy-seq
3.4 找出dead slots
首先slot就是对node+port的抽象封装, 一个slot可以运行一个worker, 所以在supervisor分配多少slot就可以运行多少worker
而对于executor是线程, 所以往往dead executor意味着, 这个workerslot dead.
;; TODO: need to consider all executors associated with a dead executor (in same slot) dead as well,
;; don't just rely on heartbeat being the same
调用compute-supervisor->dead-ports, 逻辑
找到dead-executors, dead-executors (set/difference all-executors alive-executors)
把dead-executors 对应的node+port都当成dead slots
public class WorkerSlot {
String nodeId;
int port;
}
判断dead-slots的逻辑, 很简单
dead-slots (->> (:executor->node+port assignment) ; [executor [node port]]
(filter #(contains? dead-executors (first %)))
vals)]] ;返回所有values组成的seq
最终返回所有dead slots, {nodeid #{port1, port2},…}
3.5 生成alive executor的SchedulerAssignment
“convert assignment information in zk to SchedulerAssignment, so it can be used by scheduler api”
把alive executor的assignment(executor->node+port), 转化并封装为SchedulerAssignmentImpl, 便于后面scheduler使用
public SchedulerAssignmentImpl(String topologyId, Map<ExecutorDetails, WorkerSlot> executorToSlots) {
this.topologyId = topologyId;
this.executorToSlot = new HashMap<ExecutorDetails, WorkerSlot>(0);
}
SchedulerAssignmentImpl, 记录了topology中所有executor, 以及每个executor对应的workerslot, 可见executor作为assignment的单位
3.6 找出missing-assignment-topologies, 需要从新assign (当前逻辑没有用到, 在sechduler里面会自己判断(判断逻辑相同))
什么叫missing-assignment, 满足下面任一条件
topology->executors, 其中没有该topolgy, 说明该topology没有assignment信息, 新的或scratch
topology->executors != topology->alive-executors, 说明有executor dead
topology->scheduler-assignment中的实际worker数小于topology配置的worker数 (可能上次assign的时候可用slot不够, 也可能由于dead slot造成)
3.7 all-scheduling-slots, 找出所有supervisor在conf中已配置的slots
(defn- all-scheduling-slots
[nimbus topologies missing-assignment-topologies]
(let [storm-cluster-state (:storm-cluster-state nimbus)
^INimbus inimbus (:inimbus nimbus)
supervisor-infos (all-supervisor-info storm-cluster-state nil)
supervisor-details (dofor [[id info] supervisor-infos]
(SupervisorDetails. id (:meta info))) ret (.allSlotsAvailableForScheduling inimbus
supervisor-details
topologies
(set missing-assignment-topologies)
)
]
(dofor [^WorkerSlot slot ret]
[(.getNodeId slot) (.getPort slot)]
)))
3.7.1 all-supervisor-info
从zk上读到每个supervisor的info, supervisor的hb, 返回{supervisorid, info}
SupervisorInfo的定义,
(defrecord SupervisorInfo [time-secs hostname assignment-id used-ports meta scheduler-meta uptime-secs])
参考下面设置SupervisorInfo的代码(mk-supervisor), 可以知道每个字段的意思
(SupervisorInfo. (current-time-secs) ;;hb时间
(:my-hostname supervisor) ;;机器名
(:assignment-id supervisor) ;;assignment-id = supervisor-id, 每个supervisor生成的uuid
(keys @(:curr-assignment supervisor)) ;;supervisor上当前使用的ports (curr-assignment, port->executors)
(.getMetadata isupervisor) ;;在conf里面配置的supervisor的ports
(conf SUPERVISOR-SCHEDULER-META) ;;用户在conf里面配置的supervior相关的metadata,比如name,可以任意kv
((:uptime supervisor)))))] ;;closeover了supervisor启动时间的fn, 调用可以算出uptime, 正常运行时间
(defn- all-supervisor-info
([storm-cluster-state] (all-supervisor-info storm-cluster-state nil))
([storm-cluster-state callback]
(let [supervisor-ids (.supervisors storm-cluster-state callback)] ;;从zk的superviors目录下读出所有superviors-id
(into {}
(mapcat
(fn [id]
(if-let [info (.supervisor-info storm-cluster-state id)] ;;从zk读取某supervisor的info
[[id info]]
))
supervisor-ids))
)))
3.7.2 SupervisorDetails
将supervisor-info封装成SupervisorDetails, (SupervisorDetails. id (:meta info)))
public class SupervisorDetails {
String id; //supervisor-id
/**
* hostname of this supervisor
*/
String host;
Object meta;
/**
* meta data configured for this supervisor
*/
Object schedulerMeta;
/**
* all the ports of the supervisor
*/
Set<Integer> allPorts;
}
3.7.3 allSlotsAvailableForScheduling
此处inimbus的实现是standalone-nimbus, 参考nimbus launch-server!的参数
(defn standalone-nimbus []
(reify INimbus
(prepare [this conf local-dir]
)
(allSlotsAvailableForScheduling [this supervisors topologies topologies-missing-assignments]
(->> supervisors
(mapcat (fn [^SupervisorDetails s]
(for [p (.getMeta s)] ;;meta里面放的是conf里面配置的ports list, 对每一个封装成WorkerSlot
(WorkerSlot. (.getId s) p)))) ;;可见nodeid就是supervisorid, nnid, 而不是ip
set ))
(assignSlots [this topology slots]
)
(getForcedScheduler [this]
nil )
(getHostName [this supervisors node-id]
(if-let [^SupervisorDetails supervisor (get supervisors node-id)]
(.getHost supervisor)))
))
这只用到supervisors参数, 把每个supervisor中配置的workerslot取出, 合并为set返回
最终得到的是supervisor中配置的所有slots的nodeid+port的集合, {node1 #{port1 port2 port3}, node2 #{port1 port2}}
当然这只是给出了allSlotsAvailableForScheduling最简单的实现, 可以通过更改这里的逻辑来change slots的选择策略, 比如在某些情况下, 某些slots非available
3.8 生成SupervisorDetails
关键是填上all-ports, all-scheduling-slots – dead-ports
(defn- read-all-supervisor-details [nimbus all-scheduling-slots supervisor->dead-ports]
(let [storm-cluster-state (:storm-cluster-state nimbus)
supervisor-infos (all-supervisor-info storm-cluster-state)
;;在all-scheduling-slots中有, 但是在supervisor-infos(zk的hb)没有的supervisor
;;什么情况下会有这种case, 当前实现all-scheduling-slots本身就来自supervisor-infos, 应该不存在这种case
nonexistent-supervisor-slots (apply dissoc all-scheduling-slots (keys supervisor-infos))
;;生成supervisor-details, 参考前面supervisor-info和supervisor-details的定义
all-supervisor-details (into {} (for [[sid supervisor-info] supervisor-infos
:let [hostname (:hostname supervisor-info)
scheduler-meta (:scheduler-meta supervisor-info)
dead-ports (supervisor->dead-ports sid)
;; hide the dead-ports from the all-ports
;; these dead-ports can be reused in next round of assignments
all-ports (-> (get all-scheduling-slots sid)
(set/difference dead-ports) ;;去除dead-ports,
((fn [ports] (map int ports))))
supervisor-details (SupervisorDetails. sid hostname scheduler-meta all-ports)]]
{sid supervisor-details}))]
(merge all-supervisor-details
(into {}
(for [[sid ports] nonexistent-supervisor-slots]
[sid (SupervisorDetails. sid nil ports)]))
)))
3.9 生成cluster
package backtype.storm.scheduler;
public class Cluster {
/**
* key: supervisor id, value: supervisor details
*/
private Map<String, SupervisorDetails> supervisors;
/**
* key: topologyId, value: topology's current assignments.
*/
private Map<String, SchedulerAssignmentImpl> assignments; /**
* a map from hostname to supervisor id.
*/
private Map<String, List<String>> hostToId; private Set<String> blackListedHosts = new HashSet<String>();
private INimbus inimbus;
}
3.10 调用scheduler.schedule
3.11 转化new assignment的格式, 打印相应的提示信息
调用compute-topology->executor->node+port, "convert {topology-id -> SchedulerAssignment} to {topology-id -> {executor [node port]}}"
和existing-assignments进行比较, 打印出reassignment的结果
4. 将新的assignment结果存储到Zookeeper
根据Assignment的定义, 除了executor->node+port以外, 还有些辅助信息, 比如start-time
(defrecord Assignment [master-code-dir node->host executor->node+port executor->start-time-secs])
所以首先补充这些辅助信息, 主要就是更新reassign-executors的start time, 并封装成Assignment record
如果新的assignment有变化, 更新到Zookeeper上
(.set-assignment! storm-cluster-state topology-id assignment)
最终调用INimbus.assignSlots, 用于在zookeeper上assignment change之后, 做后续处理
而standalone-nimbus中assignSlots没有做实际的操作
Storm-源码分析-Topology Submit-Nimbus-mk-assignments的更多相关文章
- Storm源码分析--Nimbus-data
nimbus-datastorm-core/backtype/storm/nimbus.clj (defn nimbus-data [conf inimbus] (let [forced-schedu ...
- JStorm与Storm源码分析(一)--nimbus-data
Nimbus里定义了一些共享数据结构,比如nimbus-data. nimbus-data结构里定义了很多公用的数据,请看下面代码: (defn nimbus-data [conf inimbus] ...
- JStorm与Storm源码分析(三)--Scheduler,调度器
Scheduler作为Storm的调度器,负责为Topology分配可用资源. Storm提供了IScheduler接口,用户可以通过实现该接口来自定义Scheduler. 其定义如下: public ...
- JStorm与Storm源码分析(二)--任务分配,assignment
mk-assignments主要功能就是产生Executor与节点+端口的对应关系,将Executor分配到某个节点的某个端口上,以及进行相应的调度处理.代码注释如下: ;;参数nimbus为nimb ...
- storm源码分析之任务分配--task assignment
在"storm源码分析之topology提交过程"一文最后,submitTopologyWithOpts函数调用了mk-assignments函数.该函数的主要功能就是进行topo ...
- JStorm与Storm源码分析(四)--均衡调度器,EvenScheduler
EvenScheduler同DefaultScheduler一样,同样实现了IScheduler接口, 由下面代码可以看出: (ns backtype.storm.scheduler.EvenSche ...
- Nimbus<三>Storm源码分析--Nimbus启动过程
Nimbus server, 首先从启动命令开始, 同样是使用storm命令"storm nimbus”来启动看下源码, 此处和上面client不同, jvmtype="-serv ...
- storm源码分析之topology提交过程
storm集群上运行的是一个个topology,一个topology是spouts和bolts组成的图.当我们开发完topology程序后将其打成jar包,然后在shell中执行storm jar x ...
- JStorm与Storm源码分析(五)--SpoutOutputCollector与代理模式
本文主要是解析SpoutOutputCollector源码,顺便分析该类中所涉及的设计模式–代理模式. 首先介绍一下Spout输出收集器接口–ISpoutOutputCollector,该接口主要声明 ...
- twitter storm源码走读之1 -- nimbus启动场景分析
欢迎转载,转载时请注明作者徽沪一郎及出处,谢谢. 本文详细介绍了twitter storm中的nimbus节点的启动场景,分析nimbus是如何一步步实现定义于storm.thrift中的servic ...
随机推荐
- jquery flexslider 轮播插件
去官网下载最新的 https://www.woothemes.com/flexslider/ 引入 css 和 js api $(window).load(function() { $('.flexs ...
- Roslyn介绍
介绍 一般来说,编译器是一个黑箱,源代码从一端进入,然后箱子中发生一些奇妙的变化,最后从另一端出来目标文件或程序集.编译器施展它们的魔法,它们必须对所处理的代码进行深入的理解,不过相关知识不是每个人都 ...
- python学习笔记(10)--爬虫下载煎蛋图片
说明: 1. 有很多细节需要注意! 2. str是保留字,不要作为变量名 3. 保存为txt报错,encoding=utf-8 4. 403错误,添加headers的方法 5. 正则match只能从开 ...
- 继承log4.net的类
using System; using System.Diagnostics; [assembly: log4net.Config.XmlConfigurator(Watch = true)] nam ...
- java线程池的应用浅析
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileReader; import java ...
- AtomicReference与volatile的区别
首先volatile是java中关键字用于修饰变量,AtomicReference是并发包java.util.concurrent.atomic下的类.首先volatile作用,当一个变量被定义为vo ...
- PHP多进程编程(3):多进程抓取网页的演示
我们知道,从父进程到子经常的数据传递相对比较容易一些,但是从子进程传递到父进程就比较的困难. 有很多办法实现进程交互,在php中比较方便的是 管道通信.当然,还可以通过 socket_pair 进行通 ...
- 判断gridView是否有数据
我这里的gridView是采用空模板数据来显示的 当gridView的数据源为空的时候它们就会显示标题 有数据的显示它们就会显示下面的这种 你仔细观察会发现,当有数据的时候空标题的table没有了,解 ...
- Android 性能测试之TraceView的使用
Traceview是android平台配备一个很好的性能分析的工具.它可以通过图形化的方式让我们了解我们要跟踪的程序的性能,并且能具体到method. 在SDK路径\tools目录下. 1.在开始使用 ...
- 关于Unity的C#基础学习(五)
一.get/set访问器 class Person{ int my_age; //默认私有权限 int sex; //属性,类似于函数,但是又不是函数的东西 public int age{ get{ ...