Scrapy 分布式数据采集方案
运行环境 CentOS7. + Python2. + Scrapy1. + MongoDB3. + BeautifulSoup4.
编程工具 PyCharm + Robomongo + Xshell 请确保你的 python版本为2..5以上 版本
强烈推荐直接【翻 墙 安 装】,简单轻松
yum install gcc libffi-devel python-devel openssl-devel
pip install scrapy 如果提示以下错误
AttributeError: 'module' object has no attribute 'OP_NO_TLSv1_1'
说明你的 Twisted 版本过高,请执行
pip install Twisted==16.4. 然后再安装以下内容
pip install scrapyd
pip install scrapy-mongodb
pip install beautifulsoup4
pip install scrapy-redis
pip install pymongo
pip install scrapyd-client
pip install Pillow
pip install python-scrapyd-api # windows下安装方法也是一样的,推荐顺手安装一下windows版本,这样在 IDE(PyCharm)下能够得到Scrapy的代码提示,而且不会报 类不存在 的错误 然后执行
scrapy startproject fusnion
就可以创建一个名为 funsion 的项目 附录A:Scrapy Shell 调试
Linux 命令行下输入(以本站点为例)
scrapy shell 'http://www.cnblogs.com/funsion/'
进入交互式shell,输入以下内容
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(response.body, 'html.parser')
>>> print soup.title
如果能输出 <title>Funsion Wu - 博客园</title> 则代表成功 附录B:参考文档
Scrapy 中文文档 http://scrapy-chs.readthedocs.org/zh_CN/latest/index.html
参考文档 https://piaosanlang.gitbooks.io/spiders/01day/README1.html
Scrapyd 文档 http://scrapyd.readthedocs.io/en/stable/
BeautifulSoup 中文手册 http://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
Scrapy-Redis 文档 http://scrapy-redis.readthedocs.io/en/stable/
Scrapy-Mongodb 文档 https://github.com/sebdah/scrapy-mongodb
Pillow 文档 http://pillow.readthedocs.io/en/latest/index.html
Python-Scrapyd-Api 文档 http://python-scrapyd-api.readthedocs.io/en/latest/
参考文档 http://www.pastandnow.com/2015/11/16/Use-Scrapyd-client-Deploy-Spider/ 附录C:mongodb安装方法
下载文件 https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.4.6.tgz
tar zxf mongodb-linux-x86_64-rhel70-3.4..tgz
cd mongodb-linux-x86_64-rhel70-3.4./
mkdir -p /data/{mongodb_data,mongodb_log}
ln -s /usr/local/src/mongodb-linux-x86_64-rhel70-3.4./bin/mongo /usr/local/bin/
nohup /usr/local/src/mongodb-linux-x86_64-rhel70-3.4./bin/mongod --dbpath=/data/mongodb_data --logpath=/data/mongodb_log/mongodb.log --logappend --fork > /dev/null >& &
编辑/etc/rc.local,加入下述代码然后再保存即可。
nohup /usr/local/src/mongodb-linux-x86_64-rhel70-3.4./bin/mongod --dbpath=/data/mongodb_data --logpath=/data/mongodb_log/mongodb.log --logappend --fork > /dev/null >& & 附录D:Scrapy代理解决方案
https://github.com/TeamHG-Memex/scrapy-rotating-proxies
https://github.com/luyishisi/Anti-Anti-Spider (防采集策略)
http://www.cnblogs.com/kylinlin/p/5242266.html (Scrapy+Tor防采集) 附录E:Scrapy-Demo地址
https://gitee.com/funsion_wu/demo/tree/master/scrapy
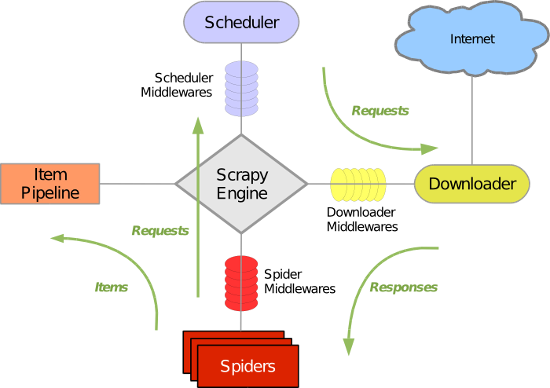
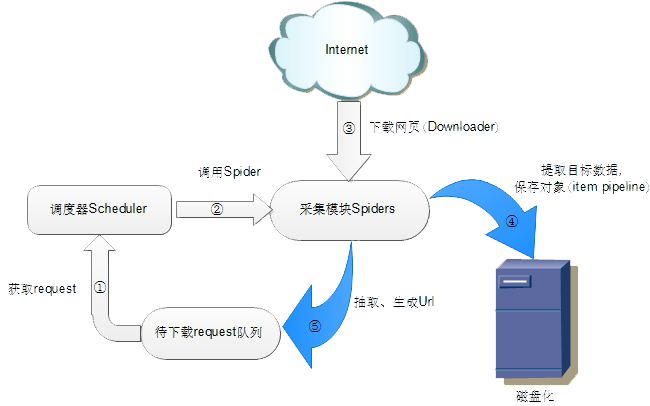
Scrapy架构图
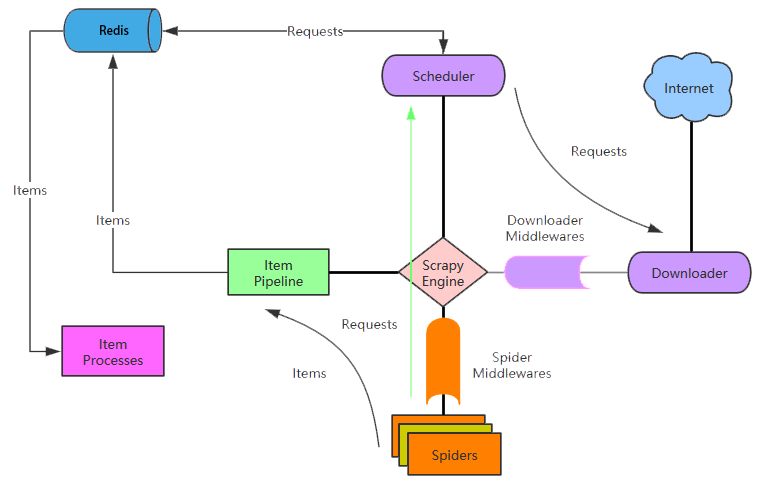
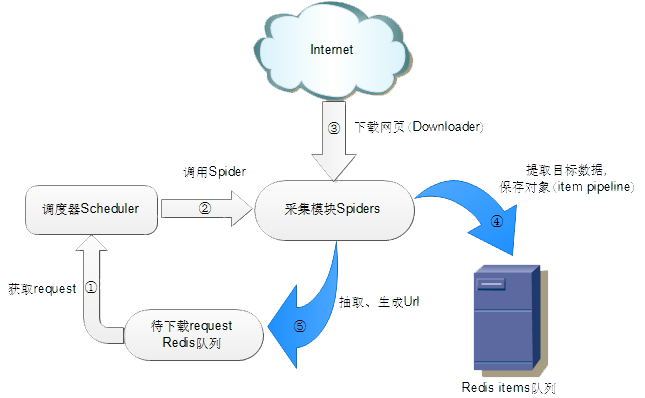
Scrapy-Redis架构图
Scrapy 分布式数据采集方案的更多相关文章
- Memcached常规应用与分布式部署方案
1.Memcached常规应用 $mc = new Memcache(); $mc->conncet('127.0.0.1', 11211); $sql = sprintf("SELE ...
- Window Redis分布式部署方案 java
Redis分布式部署方案 Window 1. 基本介绍 首先redis官方是没有提供window下的版本, 是window配合发布的.因现阶段项目需求,所以研究部署的是window版本的,其实都 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- scrapy分布式的几个重点问题
我们之前的爬虫都是在同一台机器运行的,叫做单机爬虫.scrapy的经典架构图也是描述的单机架构.那么分布式爬虫架构实际上就是:由一台主机维护所有的爬取队列,每台从机的sheduler共享该队列,协同存 ...
- Python爬虫【五】Scrapy分布式原理笔记
Scrapy单机架构 在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求 但是这些 ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 基于Solr和Zookeeper的分布式搜索方案的配置
1.1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候 ...
- ebay分布式事务方案中文版
http://cailin.iteye.com/blog/2268428 不使用分布式事务实现目的 -- ibm https://www.ibm.com/developerworks/cn/clou ...
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
随机推荐
- 报错分析---->jsp自定义标签:类cannot be resolved to a type
这个困扰我一个晚上,仔细上网查阅发现,主要是因为jsp自定义标签要用到的这个jsp-api.jar的问题 这是我eclipes中的jar: 然而jsp-api.jar这个jar在tomcat中也有(报 ...
- Unpacking and repacking stock rom .img files
http://forum.xda-developers.com/galaxy-s2/general/ref-unpacking-repacking-stock-rom-img-t1081239 OP ...
- php 验证上传图片尺寸
getimagesize 函数 取得图像大小 (PHP 4, PHP 5) array getimagesize ( string filename [, array &imageinfo] ...
- 3.2 - FTP文件上传下载
题目:开发一个支持多用户同时在线的FTP程序要求:1.用户加密认证2.允许同时多用户登录3.每个用户有自己的家目录,且只能访问自己的家目录4.对用户进行磁盘配额,每个用户的可用空间不同5.允许用户在f ...
- django将数据库中数据直接传到html
1.当然,前提是建立和配置好django数据库啦~ 2.在python后台函数中引入需要的表 #要读取home这个APP下的models.py文件,引入其中的Student_message_unedi ...
- 小技巧-如何加快github下载代码的速度(转)
作为开发人员,github是大家的标配了,常常会苦恼于gitclone某个项目的时候速度太慢,看着控制台那几K十几K的龟速,吐血!! 原因很简单:github的CDN被伟大的墙屏蔽所致. 所以解决方案 ...
- 从CPU/OS到虚拟机和云计算
从CPU/OS到虚拟机和云计算 作者:张冬 关于软硬件谁为主导这个话题,套用一句谚语就是三十年河东三十年河西.风水轮流转.软件和硬件一定是相互促进.相互拆台又相互搭台的. ...
- 如何停止requestAnimationFrame方法启动的动画
HTML5/CSS3时代,我们要在web里做动画选择其实已经很多了:(1) 你可以用CSS3的animattion+keyframes;(2) 你也可以用css3的transition; (3) 你还 ...
- 在github上新建一个仓库并上传本地工程
扫盲:在github上新建一个仓库并上传本地工程 http://1ke.co/course/194 我自己新建了个项目,一步一步流程如下. zhoudd@desay:~/桌面/mini_embed_d ...
- Python误区之strip,lstrip,rstrip
最近在处理数据的时候,想把一个字符串开头的“)”符号去掉,所以使用targetStr.lstrip(")"),发现在 将处理完的数据插入到数据库时会出现编码报错,于是在网上搜到了这 ...