SQL查询入门(下篇)
SQL查询入门(下篇)
文章转自:http://www.cnblogs.com/CareySon/archive/2011/05/18/2049727.html
引言
在前两篇文章中,对于单表查询和多表查询的概念做出了详细的介绍,在本篇文章中会主要介绍聚合函数的使用和数据的分组.
简介
简单的说,聚合函数是按照一定的规则将多行(Row)数据汇总成一行的函数。对数据进行汇总后,可以按照特定的列(column)将所汇总的其他列进行分组(Group by),并可以在再次给定条件进行筛选(Having).
聚合函数将多行数据进行汇总的概念可以简单用下图解释:
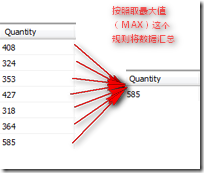
简单聚合函数
简单聚合函数是那些拥有很直观将多行(Row)汇总为一行(Row)计算规则的函数。这些函数往往从函数名本身就可以猜测出函数的作用,而这些函数的参数都是数字类型的。简单聚合函数包括:Avg,Sum,Max,Min.
简单聚合函数的参数只能是数字类型,在SQL中,数字类型具体包括:tinyint,smallint,int,bigint,decimal,money,smallmoney,float,real.
在介绍简单聚合函数之前,先来介绍一下Count()这个聚合函数.
Count()
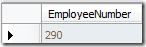
Count函数用于计算给定条件下所含有的行(Row)数.例如最简单的:

上表中,我想知道公司员工的个数,可以简单的使用:
结果如下
当Count()作用于某一特定列(Column),和以“*”作为参数时的区别是当Count(列名)碰到“Null”值时不会将其计算在内,例如:
我想知道公司中有上级的员工个数:

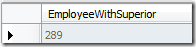
可以看到,除了没有上级的CEO之外,所有其他的员工已经被统计在内.
也可以在Count()内使用Distinct关键字来让,每一列(Column)的每个相同的值只有一个被统计在内,比如:
我想统计公司中经理层级的数量:
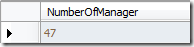
结果如上.
Avg(),Sum(),Max()和Min()
这几个聚合函数除了功能不同以外,参数和用法几乎相同。所以这里只对Avg()这个聚合函数进行解释:
Avg()表示计算在选择范围内的汇总数据的平均值.这个过程中“Null”值不会被统计在内 ,例如:
我想获得平均每位员工休假的时长:
结果如下:

因为默认用聚合函数进行数据汇总时,不包含null,但如果我想要包含null值,并在当前查询中将Null值以其他值替代并参与汇总运算时,使用IsNull(column,value)
例如:
我想获得平均每位员工的休假时长,如果员工没有休假,则按休假10个小时计算
结果如下:

也可以使用DISTINCT关键字在简单聚合函数中让每一个值唯一参与聚合汇总运算.在上面的Count函数中已经解释,这里不做重复。
而关于Sum(),Max(),Min()等这些简单聚合函数,使用方法基本相同,这里就不重复了
将聚合函数得到的值按照列(Column)进行分组
如果聚合函数所得到的结构无法按照特定的值进行分组,那聚合函数的作用就没有那么强了。在SQL中,使用Group by对聚合函数汇总的值进行分组。分组的概念可以下面这个简单的例子表示:
例如:
我想根据不同省得到销售人员所销售的总和:
select TerritoryID,SUM(SalesLastYear) as ToTalSales
from Sales.SalesPerson
Group By TerritoryID
概念如下图所示:

跟在Group by 后面的列明是分组的依据。当然在某些情况下,会有依据很多个列(Column)进行分组的情况,下面这个例子有点实际意义。
我想按照不同性别获得不同经理手下的员工的病假时间总和:
SELECT ManagerID, Gender, SUM(SickLeaveHours) AS SickLeaveHours, COUNT(*) AS EmployeeNumber
FROM HumanResources.Employee
GROUP BY Gender, ManagerID
结果如下:

Group by后面很多列,我们可以在逻辑思维上这么想,先根据第一列唯一的MangeageID和唯一的Gender进行Cross join得到唯一可以确定其他键(Key)的键,最后过滤掉聚合函数中不能返回的值的行(Row)(也就是Null)的行。在根据这实际上两列,但逻辑上是一列的值作为分组依据。
上图中可以看到,我们首先按照经理ID,进行分组,然后根据不同经理手下的员工的性别,再次进行分总,最终按照这个分组条件得到病假时间总和.
这里要注意,当使用Group By按照多列(Column)进行分组时,一定要注意出现在Group By后面的次序
上面先出现Gender是先遍历Gender的所有可能的值,再根据每个Gender可能的值去计算匹配ManagerID,最后再根据ManagerID来进行聚合函数运算,如果将上面Group By后面得列(Column)顺序改为先ManagerId,再Gender,则意味着先遍历ManagerID所有可能出现的值,再去匹配Gender,则结果如下:
从Gender(性别)变为M(男性)开始,第二次遍历ManagerId进行匹配:
从上面我们可以看出,虽然Group by后面出现列(Column)的次序不同,所得到结果的顺序也不同,但所得到的数据集(DataSet)是完全一样,所以,可以通过Order By子句将按照不同列次序进行Group By的查询语句获得相同的结果。这里就不再截图了。
对分组完成后的数据集进行再次筛选(Having)
当对使用聚合函数进行分组后,可以再次使用放在Group by子句后的Having子句对分组后的数据进行再次过滤,having子句在某些方面很想Where子句,具体hanving表达式的使用可以看我们前面的对where的讲解。
Having子句可以理解成在分组后进行二次过滤的语句。
使用Having子句非常简单,但需要注意的是,having子句后面不能跟在select语句中出现中出现的别名,而必须将select语句内的表达式再写一遍。例如还是针对上面的表:
我想按照不同性别获得不同经理手下的员工的病假时间总和,这些经理手下的员工需要大于2个人:
SELECT ManagerID, Gender, SUM(SickLeaveHours) AS SickLeaveHours, COUNT(*) AS EmployeeNumber
FROM HumanResources.Employee
GROUP BY ManagerID, Gender
HAVING (EmployeeNumber > 2)
注意,上面这句话是错误的,在Having子句后面不能引用别名或者变量名,如果需要实现上面那个效果,需要将Count(*)这个表达式再Having子句中重写一遍,正确写法如下:
SELECT ManagerID, Gender, SUM(SickLeaveHours) AS SickLeaveHours, COUNT(*) AS EmployeeNumber
FROM HumanResources.Employee
GROUP BY ManagerID, Gender
HAVING (COUNT(*) > 2)
结果如下:

我们看到,只有员工数大于2人的条件被选中。
当然,Having子句最强大的地方莫过于其可以使用聚合函数作为表达式,这是在Where子句中不允许的。下面这个例子很好的having子句的强大之处:
还是上面那个例子的数据:
我想获得不同经理手下的员工的病假时间总和,并且这个经理手下病假最多的员工的请假小时数大于病假最少员工的两倍:
SELECT ManagerID, SUM(SickLeaveHours) AS TotalSickLeaveHours, COUNT(*) AS EmployeeNumber
FROM HumanResources.Employee
GROUP BY ManagerID
HAVING (MAX(SickLeaveHours) > 2 * MIN(SickLeaveHours))
结果如下:

这里可以看出,Having子句实现如此简单就能实现的强大功能,如果用where将会非常非常的麻烦。上面那个结果中,having语句聚合函数的作用范围可以用下图很好的演示出来:

上面可以看出被筛选后的数据满足请假最多员工的小时数明显大于请假最少员工小时数的两倍。
小结
本文以聚合函数概念为开始,讲述了聚合函数使用中经常用到的查询,分组,过滤的概念和使用方式。使用好聚合函数可以将很多放到应用程序业务层的任务转到数据库里来.这会对维护和性能提升很很大的帮助.
SQL查询入门(下篇)的更多相关文章
- [转]sql语句中出现笛卡尔乘积 SQL查询入门篇
本篇文章中,主要说明SQL中的各种连接以及使用范围,以及更进一步的解释关系代数法和关系演算法对在同一条查询的不同思路. 多表连接简介 在关系数据库中,一个查询往往会涉及多个表,因为很少有数据库只有一个 ...
- sql语句中出现笛卡尔乘积 SQL查询入门篇
2014-12-29 凡尘工作室 阅 34985 转 95 本篇文章中,主要说明SQL中的各种连接以及使用范围,以及更进一步的解释关系代数法和关系演算法对在同一条查询的不同思路. 多表连接简介 ...
- sql查询入门
SQL语言是一门相对来说简单易学却又功能强大的语言,它能让你快速上手并很快就能写出比较复杂的查询语句.但是对于大多数开发者来说,使用SQL语句查询数据库的时候,如果没有一个抽象的过程和一个合理的步骤, ...
- 浅谈SQL优化入门:1、SQL查询语句的执行顺序
1.SQL查询语句的执行顺序 (7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_ ...
- 【数据库】数据库入门(四): SQL查询 - SELETE的进阶使用
集合操作常用的集合操作主要有三种:UNION(联合集).INTERSECT(交叉集).EXCEPT(求差集).以上三种集合的操作都是直接作用在两个或者多个 SQL 查询语句之间,将所有的元组按照特定的 ...
- 【T-SQL基础】01.单表查询-几道sql查询题
概述: 本系列[T-SQL基础]主要是针对T-SQL基础的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础]02.联接查询 [T-SQL基础]03.子查询 [T-SQL基础 ...
- SQL 存储过程入门(事务)(四)
SQL 存储过程入门(事务)(四) 本篇我们来讲一下事务处理技术. 为什么要使用事务呢,事务有什么用呢,举个例子. 假设我们现在有个业务,当做成功某件事情的时候要向2张表中插入数据,A表,B表,我 ...
- 【T-SQL进阶】02.理解SQL查询的底层原理
本系列[T-SQL]主要是针对T-SQL的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础]02.联接查询 [T-SQL基础]03.子查询 [T-SQL基础]04.表表达式 ...
- 浅谈SQL优化入门:3、利用索引
0.写在前面的话 关于索引的内容本来是想写的,大概收集了下资料,发现并没有想象中的简单,又不想总结了,纠结了一下,决定就大概写点浅显的,好吧,就是懒,先挖个浅坑,以后再挖深一点.最基本的使用很简单,直 ...
随机推荐
- Sparrow - Distributed, Low Latency Scheduling
http://www.cs.berkeley.edu/~matei/papers/2013/sosp_sparrow.pdf http://www.eecs.berkeley.edu/~keo/tal ...
- php中var_dump、var_export和print_r的用法区别
void var_dump ( mixed $expression [, mixed $... ] )此函数显示关于一个或多个表达式的结构信息,包括表达式的类型与值.数组将递归展开值,通过缩进显示其结 ...
- SpringBoot与消息(RabbitMQ)
1. JMS和AMQP JMS(Java Message Service): ActiveMQ是JMS实现; AMQP(Advanced Message Queuing Protocol) 兼容JMS ...
- requests+BeautifulSoup详解
简介 Python标准库中提供了:urllib.urllib2.httplib等模块以供Http请求,但是,它的 API 太渣了.它是为另一个时代.另一个互联网所创建的.它需要巨量的工作,甚至包括各种 ...
- 为你的CSDN博客添加CNZZ流量统计功能
一.流量统计介绍 流量统计是指通过各种科学的方式,准确的纪录来访某一页面的访问者的流量信息,目前而言,必须具备可以统计. 1.简介 统计独立的访问者数量(独立用户.独立访客): 可以统计独立的IP地址 ...
- docker部署oracle
oracle部署 创建oracle用户 [root@stpass-15 ~]# useradd oracle[root@stpass-15 oracle]# cd oracle [root@stpas ...
- (4.2)动态管理视图DMV
以下是一些您应该熟悉的更有用的DMV: 1.sys.dm_exec_cached_plans - 可用于SQL Server的缓存查询计划 2.sys.dm_exec_sessions - SQL S ...
- srs(srs-librtmp推送h264原始数据)
1.下载最新srs源码 https://github.com/ossrs/srs/releases 2.编译(进入~/srs-2.0-r4/trunk目录) ./configure --with-li ...
- 手把手教你发布自己的 Composer 包
一.前言 Composer 是 PHP 用来管理依赖(dependency)关系的工具.我们不仅要学会使用别人提供的包,更要学会制作和分享自己的软件包,下面演示如何创建一个自己的 Composer 包 ...
- 关于safenetde 的明文 密文 数据 。这个数组使用 safenet的助手 产生的。
关于safenetde 的明文 密文 数据 .这个数组使用 safenet的助手 产生的. 下图是生成的数组 例如: { 0x9B, 0xFD, 0xF5, 0xA6, 0xF5, 0x57, 0 ...