第五章 MyEclipse配置hadoop开发环境
1.首先要下载相应的hadoop版本的插件,我这里就给2个例子:
hadoop-1.2.1插件:http://download.csdn.net/download/hanyongan300/6238153
hadoop2.2.0插件:http://blog.csdn.net/twlkyao/article/details/17334693
上一章我也讲了怎么制作相应版本的插件,这些插件可以在网上搜到
2.把插件拷贝到myeclipse根目录下/dropins目录下。
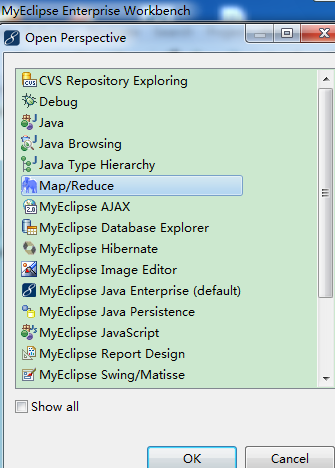
3、 启动myeclipse,打开Perspective:
【Window】->【Open Perspective】->【Other...】->【Map/Reduce】->【OK】
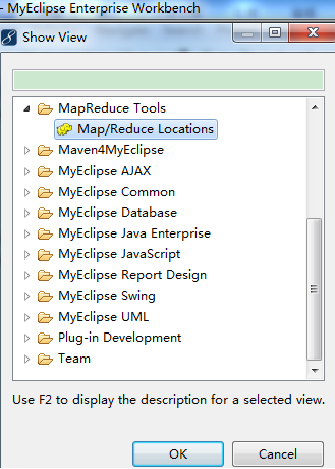
3、 打开一个View:
【Window】->【Show View】->【Other...】->【MapReduce Tools】->【Map/Reduce Locations】->【OK】
4、 添加Hadoop location:
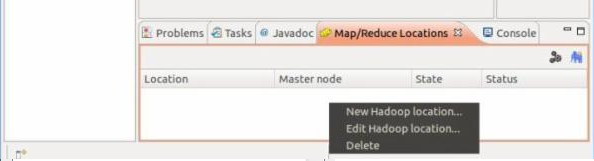

location name: 我填写的是:hadoop,这个可以任意填写
Map/Reduce Master 这个框里:
这两个参数就是mapred-site.xml里面mapred.job.tracker里面的ip和port
Host:就是jobtracker 所在的集群机器,这里写192.168.0.155,我这个myeclipse是在windows下的,所以去连接liunx下的hadoop要写地址
Hort:就是jobtracker 的port,这里写的是9001
DFS Master 这个框里
这两个参数就是core-site.xml里面fs.default.name里面的ip和port
Host:就是namenode所在的集群机器,这里写192.168.0.155
Port:就是namenode的port,这里写9000
(Use M/R master host,这个复选框如果选上,就默认和Map/Reduce Master这个框里的host一样,如果不选择,就可以自己定义输入,这里jobtracker 和namenode在一个机器上,所以是一样的,就勾选上)
user name:这个是连接hadoop的用户名,我创建的用户就是hadoop。
然后继续填写advanced parameters
在这里只需要填写 hadoop.tmp.dir这一栏,跟在core-site.xml里面配置写的一样

然后关闭myeclipse重启,就可以看到连接成功了。。。
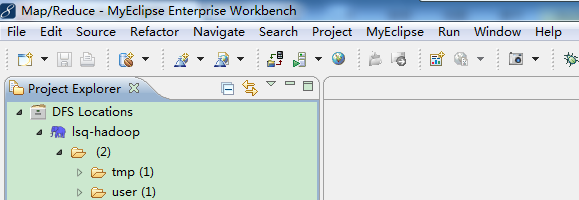
连接DFS,是为了帮助你查看hdfs目录的,在这里,你可以直接操作hdfs.点击右键:

create new directory:创建文件
Refresh:刷新
upload files to DFS:上传文本
upload directory to DFS:上传文件夹
如果要是创建hadoop项目,先配置下:Window------preferences----Hadoop Map/Reduce,指定本地的hadoop

然后在本地配置远程hadoop的IP,打开C:\Windows\System32\drivers\etc\hosts文件,添加hadoop所安装的服务器IP和主机名

下面就可以在myeclipse创建mapreduce项目了,file----new Prokect-----

下面就正常写代码:下面是操作hase的代码
package hbase; import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes; /**
* 对hbase进行增删改查
* @author Administrator
*
*/
public class HbaseTest {
private static Configuration conf=null;
static{
conf=HBaseConfiguration.create();
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.zookeeper.quorum", "192.168.0.26");
//configuration.set("hbase.master", "192.168.1.25:6000");
File workaround = new File(".");
System.getProperties().put("hadoop.home.dir",
workaround.getAbsolutePath());
new File("./bin").mkdirs();
try {
new File("./bin/winutils.exe").createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 创建一张表
* @param tablename
* @param cfg
* @throws IOException
*/ public static void createTable(String tablename,String[] cfg)
throws IOException{
HBaseAdmin admin=new HBaseAdmin(conf);
if(admin.tableExists(tablename)){
System.out.println("表已经存在!");
}else{
HTableDescriptor tableDesc=new HTableDescriptor(tablename);
for(int i=0;i<cfg.length;i++){
tableDesc.addFamily(new HColumnDescriptor(cfg[i]));
}
admin.createTable(tableDesc);
System.out.println("表创建成功!");
}
}
/**
* 删除表
* @param tablename
* @throws IOException */
public static void deleteTable(String tablename)
throws IOException{
HBaseAdmin admin=new HBaseAdmin(conf);
admin.disableTable(tablename);
admin.deleteTable(tablename);
System.out.println("表删除成功");
}
/**
* 插入一行记录
* @param tablename
* @param rowkey
* @param family
* @param qualifier
* @param value
*/
public static void writeRow(String tablename,String rowkey,String family,String qualifier,String value) {
try {
HTable table=new HTable(conf,tablename);
Put put =new Put(Bytes.toBytes(rowkey));
put.add(Bytes.toBytes(family),Bytes.toBytes(qualifier),Bytes.toBytes(value));
table.put(put);
System.out.println("插入数据成功");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} }
/**
* 查找开始与结束之间的数据
* @param tableName
*/
public static void getAll(String tableName) {
try{
HTable table = new HTable(conf, tableName);
Scan scan = new Scan(Bytes.toBytes("a"), Bytes.toBytes("z"));
// scan.addColumn(Bytes.toBytes("a"), Bytes.toBytes("z"));
// SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("a"),
// Bytes.toBytes("z"),
// CompareOp.NOT_EQUAL, Bytes.toBytes("0"));
// filter.setFilterIfMissing(true);
// scan.setFilter(filter); ResultScanner ss = table.getScanner(scan);
for(Result r:ss){
for(KeyValue kv : r.raw()){
System.out.print("rowid为:"+new String(kv.getRow()) + " ");
System.out.print("列族为:"+new String(kv.getFamily()) + " ");
System.out.print("列限定符为:"+new String(kv.getQualifier()) + " ");
System.out.print("时间戳"+kv.getTimestamp() + " ");
System.out.println("值为"+new String(kv.getValue()));
}
}
} catch (IOException e){
e.printStackTrace(); }
}
/**
* 查找一行记录
* @param tablename
* @param rowKey
* @throws IOException
*/
@SuppressWarnings("deprecation")
public static void getOne(String tablename,String rowKey) throws IOException{
HTable table = new HTable(conf, tablename);
Get get = new Get(rowKey.getBytes());
Result rs = table.get(get);
for(KeyValue kv : rs.raw()){
System.out.print(new String(kv.getRow()) + " " );
System.out.print(new String(kv.getFamily()) + ":" );
System.out.print(new String(kv.getQualifier()) + " " );
System.out.print(kv.getTimestamp() + " " );
System.out.println(new String(kv.getValue()));
} }
/**
* 显示所有数据
*/
public static void getAllRecord (String tableName) {
try{
HTable table = new HTable(conf, tableName);
Scan s = new Scan();
ResultScanner ss = table.getScanner(s);
for(Result r:ss){
for(KeyValue kv : r.raw()){
System.out.print("rowid为:"+new String(kv.getRow()) + " ");
System.out.print("列族为:"+new String(kv.getFamily()) + " ");
System.out.print("列限定符为:"+new String(kv.getQualifier()) + " ");
System.out.print("时间戳"+kv.getTimestamp() + " ");
System.out.println("值为"+new String(kv.getValue()));
}
}
} catch (IOException e){
e.printStackTrace(); }
}
/**
* 删除一行记录
*/
public static void delRecord (String tableName, String rowKey) throws IOException{
HTable table = new HTable(conf, tableName);
List list = new ArrayList();
Delete del = new Delete(rowKey.getBytes());
list.add(del);
table.delete(list);
System.out.println("del recored " + rowKey + " ok.");
} public static void main(String[] agrs){
String tablename="score";
String[] familys={"grade","course"};
try {
HbaseTest.createTable(tablename, familys);
//HbaseTest.delvalue(tablename, "zkb","course" , "click", "90");
// HbaseTest.delRecord(tablename, "zkb"); } catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} // HbaseTest.writeRow(tablename, "zkb", "grade", "title", "5");
// HbaseTest.writeRow(tablename, "zkb", "course", "click", "90");
// HbaseTest.writeRow(tablename, "zkb", "course", "url", "97");
// HbaseTest.writeRow(tablename, "zkb", "course", "author", "87");
//
// HbaseTest.writeRow(tablename, "baoniu", "grade", "reply", "4");
// HbaseTest.writeRow(tablename, "baoniu", "course", "siteName", "89");
// HbaseTest.writeRow(tablename, "1", "grade", "title", "5");
// HbaseTest.writeRow(tablename, "1", "course", "click", "90");
// HbaseTest.writeRow(tablename, "2", "course", "url", "97");
// HbaseTest.writeRow(tablename, "2", "course", "author", "87");
//
// HbaseTest.writeRow(tablename, "3", "grade", "reply", "4");
// HbaseTest.writeRow(tablename, "3", "course", "siteName", "89");
// HbaseTest.getOne(tablename, "zkb");
// HbaseTest.getAllRecord(tablename); // HbaseTest.getAllRecord(tablename);
HbaseTest.getAll(tablename); } }
第五章 MyEclipse配置hadoop开发环境的更多相关文章
- myeclipse配置hadoop开发环境
1.安装Hadoop开发插件 hadoop安装包contrib/目录下有个插件hadoop-0.20.2-eclipse-plugin.jar,拷贝到myeclipse根目录下/dropins目录下. ...
- 搭建基于MyEclipse的Hadoop开发环境
不多说,直接上干货! 前面我们已经搭建了一个伪分布模式的Hadoop运行环境.请移步, hadoop-2.2.0.tar.gz的伪分布集群环境搭建(单节点) 我们绝大多数都习惯在Eclipse或MyE ...
- Hadoop_配置Hadoop开发环境(Eclipse)
通常我们可以用Eclipse作为Hadoop程序的开发平台. 1) 下载Eclipse 下载地址:http://www.eclipse.org/downloads/ 根据操作系统类型,选择合适的版本 ...
- Eclipse配置Hadoop开发环境
Step 1:选择Hadoop版本对应的Eclipse插件jar包(可自行编译),我的Hadoop版本是hadoop-0.20.2,对应的插件应该是:hadoop-0.20.2-eclipse-plu ...
- mac攻略(五) -- 使用brew配置php7开发环境(mac+php+apache+mysql+redis)
前面介绍过基本的配置,后来我又从网上查找了很多资料,经过不断的摸索,下面做了一个总结,希望能对大家提供些许帮助(Mac版本是sierra) 一.mac系统会自带git,而我们要做的是自己安装git ...
- 配置Hadoop开发环境(Eclipse)
参考博文: http://blog.csdn.net/zythy/article/details/17397153 http://www.tuicool.com/articles/AjUZrq 注意事 ...
- IDEA配置Hadoop开发环境&编译运行WordCount程序
有关hadoop及java安装配置请见:https://www.cnblogs.com/lxc1910/p/11734477.html 1.新建Java project: 选择合适的jdk,如图所示: ...
- Eclipse安装Hadoop插件配置Hadoop开发环境
一.编译Hadoop插件 首先需要编译Hadoop 插件:hadoop-eclipse-plugin-2.6.0.jar,然后才可以安装使用. 第三方的编译教程:https://github.com/ ...
- 在Fedora18上配置个人的Hadoop开发环境
在Fedora18上配置个人的Hadoop开发环境 1. 背景 文章中讲述了类似于"personalcondor"的一种"personal hadoop" ...
随机推荐
- APUE学习笔记——6 系统数据文件与信息
1.用户口令:/etc/passwd文件 该文件中包含下列结构体信息.其中,当下主修熊passwd不再这里显示,是使用了一个占位符. struct passwd { char * pw_name; / ...
- 数据仓库(Data Warehouse)建设
数据仓库初体验 数据库仓库架构以前弄的很简单:将各种源的数据统一汇聚到DW中,DW没有设计,只是将所有数据汇聚起来: ETL也很简单,只是将数据同步到DW中,只是遇到BUG时,处理一些错误数据,例如: ...
- Android 开发 Tip 17 -- 为什么getBackground().setAlpha(); 会影响别的控件?
转载请注明出处:http://blog.csdn.net/crazy1235/article/details/75670018 http://www.jb51.net/article/110035.h ...
- HTTP 1.1 协议规范
1. 内容协商 请求一个特殊编码的过程在 HTTP 1.1 规范中称为内容协商:
- Redis安全性配置
最近Redis刚爆出一个安全性漏洞,我的服务器就“光荣的”中招了.黑客攻击的基本方法是: 扫描Redis端口,直接登录没有访问控制的Redis 修改Redis存盘配置:config set dir / ...
- linux下修改了tomcat端口之后无法访问
查看防火墙,是否将修改之后的端口加入防火墙规则内,如没有,加入规则内,重启防火墙,如果还是无法访问,请看第二步 执行bin目录下shutdown.sh脚本,如果正常关闭,则执行startup.sh脚本 ...
- 转载maven安装,配置,入门
转载:http://www.cnblogs.com/dcba1112/archive/2011/05/01/2033805.html 本书代码下载 大家可以从我的网站下载本书的代码:http://ww ...
- 每天一个linux命令(磁盘):【转载】df 命令
linux中df命令的功能是用来检查linux服务器的文件系统的磁盘空间占用情况.可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息. 1.命令格式: df [选项] [文件] 2.命 ...
- JSP学习(一)JSP基础语法
JSP基础语法 1.JSP模版元素 JSP页面中的HTML内容称之为JSP模版元素. JSP模版元素定义了网页的基本骨架,即定义了页面的结构和外观. <%@ page language=&quo ...
- 《DSP using MATLAB》示例Example 8.25