[转载] 第三篇:数据仓库系统的实现与使用(含OLAP重点讲解)
前言
上一篇重点讲解了数据仓库建模,它是数据仓库开发中最核心的部分。然而完整的数据仓库系统还会涉及其他一些组件的开发,其中最主要的是ETL工程,在线分析处理工具(OLAP)和商务智能(BI)应用等。
本文将对这些方面做一个总体性的介绍(尤其是OLAP),旨在让读者对数据仓库的认识提升到一个全局性的高度。
创建数据仓库
数据仓库的创建方法和数据库类似,也是通过编写DDL语句来实现。在过去,数据仓库系统大都建立在RDBMS上,因为维度建模其实也可以看做是关系建模的一种。但如今随着开源分布式数据仓库工具如Hadoop Hive,Spark SQL的兴起,开发人员往往将建模和实现分离。使用专门的建模软件进行ER建模、关系建模、维度建模,而具体实现则在Hive/Spark SQL下进行。没办法,谁让这些开源工具没有提供自带的可视化建模插件呢:-(。
话说现在的开源分布式工具都是"散兵作战",完成一个大的项目要组合N个工具,没有一个统一的开发平台。还有就是可视化效果比较差,界面很难看或者没有界面。个人建议在资金足够的情况下尽量使用商用大数据平台来开发,虽然这些商用产品广告打得多少有点夸张,但是它们的易用性做的是真好。这里笔者推荐阿里云的数加平台,附链接:https://data.aliyun.com/。
ETL:抽取、转换、加载
在本系列第一篇中,曾大致介绍了该环节,它很可能是数据仓库开发中最耗时的阶段。本文将详细对这个环节进行讲解。
ETL工作的实质就是从各个数据源提取数据,对数据进行转换,并最终加载填充数据到数据仓库维度建模后的表中。只有当这些维度/事实表被填充好,ETL工作才算完成。接下来分别对抽取,转换,加载这三个环节进行讲解:
1. 抽取(Extract)
数据仓库是面向分析的,而操作型数据库是面向应用的。显然,并不是所有用于支撑业务系统的数据都有拿来分析的必要。因此,该阶段主要是根据数据仓库主题、主题域确定需要从应用数据库中提取的数。
具体开发过程中,开发人员必然经常发现某些ETL步骤和数据仓库建模后的表描述不符。这时候就要重新核对、设计需求,重新进行ETL。正如数据库系列的这篇中讲到的,任何涉及到需求的变动,都需要重头开始并更新需求文档。
2. 转换(Transform)
转换步骤主要是指对提取好了的数据的结构进行转换,以满足目标数据仓库模型的过程。此外,转换过程也负责数据质量工作,这部分也被称为数据清洗(data cleaning)。数据质量涵盖的内容可具体参考这里。
3. 加载(Load)
加载过程将已经提取好了,转换后保证了数据质量的数据加载到目标数据仓库。加载可分为两种L:首次加载(first load)和刷新加载(refresh load)。其中,首次加载会涉及到大量数据,而刷新加载则属于一种微批量式的加载。
多说一句,如今随着各种分布式、云计算工具的兴起,ETL实则变成了ELT。就是业务系统自身不会做转换工作,而是在简单的清洗后将数据导入分布式平台,让平台统一进行清洗转换等工作。这样做能充分利用平台的分布式特性,同时使业务系统更专注于业务本身。
OLAP/BI工具
数据仓库建设好以后,用户就可以编写SQL语句对其进行访问并对其中数据进行分析。但每次查询都要编写SQL语句的话,未免太麻烦,而且对维度建模数据进行分析的SQL代码套路比较固定。于是,便有了OLAP工具,它专用于维度建模数据的分析。而BI工具则是能够将OLAP的结果以图表的方式展现出来,它和OLAP通常出现在一起。(注:本文所指的OLAP工具均指代这两者。)
在规范化数据仓库中OLAP工具和数据仓库的关系大致是这样的: 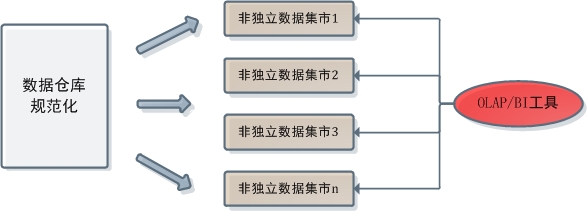
这种情况下,OLAP不允许访问中心数据库。一方面中心数据库是采取规范化建模的,而OLAP只支持对维度建模数据的分析;另一方面规范化数据仓库的中心数据库本身就不允许上层开发人员访问。而在维度建模数据仓库中,OLAP/BI工具和数据仓库的关系则是这样的:
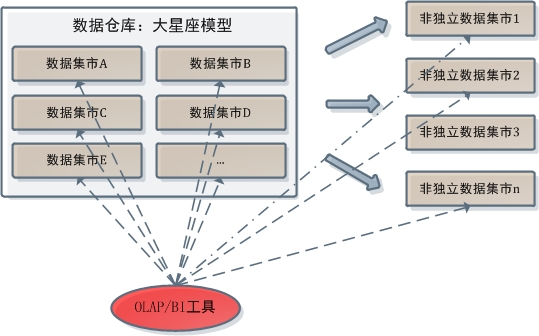
在维度建模数据仓库中,OLAP不但可以从数据仓库中直接取数进行分析,还能对架构在其上的数据集市群做同样工作。对该部分讲解感到模糊的读者请重看上篇中三种数据仓库建模体系部分。
数据立方体(Data Cube)
在介绍OLAP工具的具体使用前,先要了解这个概念:数据立方体(Data Cube)。
很多年前,当我们要手工从一堆数据中提取信息时,我们会分析一堆数据报告。通常这些数据报告采用二维表示,是行与列组成的二维表格。但在真实世界里我们分析数据的角度很可能有多个,数据立方体可以理解为就是维度扩展后的二维表格。下图展示了一个三维数据立方体:
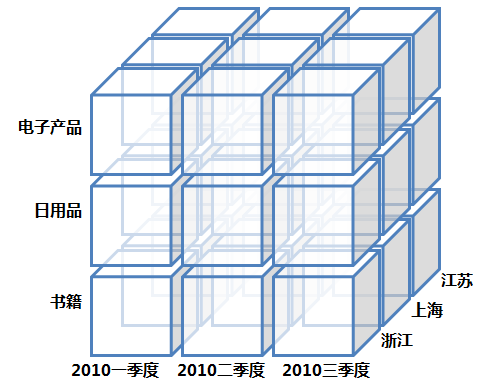
尽管这个例子是三维的,但更多时候数据立方体是N维的。它的实现有两种方式,本文后面部分会讲到。其中上一篇讲到的星形模式就是其中一种,该模式其实是一种连接关系表与数据立方体的桥梁。但对于大多数纯OLAP使用者来讲,数据分析的对象就是这个逻辑概念上的数据立方体,其具体实现不用深究。对于这些OLAP工具的使用者来讲,基本用法是首先配置好维表、事实表,然后在每次查询的时候告诉OLAP需要展示的维度和事实字段和操作类型即可。
下面介绍数据立方体中最常见的五大操作:切片,切块,旋转,上卷,下钻。
1. 切片和切块(Slice and Dice)
在数据立方体的某一维度上选定一个维成员的操作叫切片,而对两个或多个维执行选择则叫做切块。下图逻辑上展示了切片和切块操作:
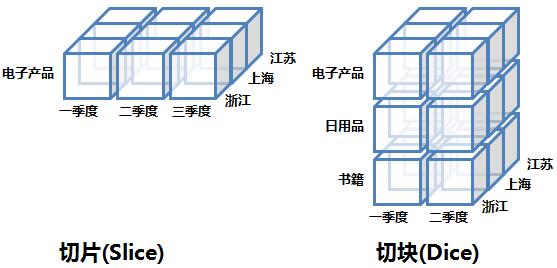
这两种操作的SQL模拟语句如下,主要是对WHERE语句做工作:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 切片SELECT Locates.地区, Products.分类, SUM(数量)FROM Sales, Dates, Products, LocatesWHERE Dates.季度 = 2 AND Sales.Date_key = Dates.Date_key AND Sales.Locate_key = Locates.Locate_key AND Sales.Product_key = Products.Product_keyGROUP BY Locates.地区, Products.分类# 切块SELECT Locates.地区, Products.分类, SUM(数量)FROM Sales, Dates, Products, LocatesWHERE (Dates.季度 = 2 OR Dates.季度 = 3) AND (Locates.地区 = '江苏' OR Locates.地区 = '上海') AND Sales.Date_key = Dates.Date_key AND Sales.Locate_key = Locates.Locate_key AND Sales.Product_key = Products.Product_keyGROUP BY Dates.季度, Locates.地区, Products.分类 |
2. 旋转(Pivot)
旋转就是指改变报表或页面的展示方向。对于使用者来说,就是个视图操作,而从SQL模拟语句的角度来说,就是改变SELECT后面字段的顺序而已。下图逻辑上展示了旋转操作:
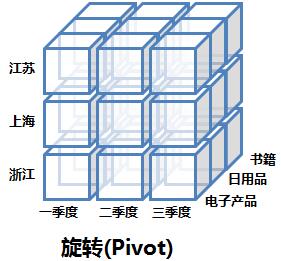
3. 上卷和下钻(Rol-up and Drill-down)
上卷可以理解为"无视"某些维度;下钻则是指将某些维度进行细分。下图逻辑上展示了上卷和下钻操作:
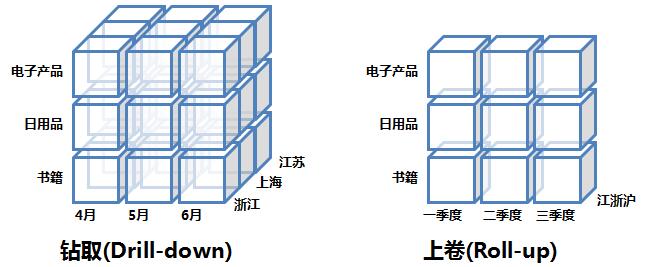
这两种操作的SQL模拟语句如下,主要是对GROUP BY语句做工作:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 上卷SELECT Locates.地区, Products.分类, SUM(数量)FROM Sales, Products, LocatesWHERE Sales.Locate_key = Locates.Locate_key AND Sales.Product_key = Products.Product_keyGROUP BY Locates.地区, Products.分类# 下钻SELECT Locates.地区, Dates.季度, Products.分类, SUM(数量)FROM Sales, Dates, Products, LocatesWHERE Sales.Date_key = Dates.Date_key AND Sales.Locate_key = Locates.Locate_key AND Sales.Product_key = Products.Product_keyGROUP BY Dates.季度.月份, Locates.地区, Products.分类 |
4. 其他OLAP操作
除了上述的几个基本操作,不同的OLAP工具也会提供自有的OLAP查询功能,如钻过,钻透等,本文不一一进行讲解。通常一个复杂的OLAP查询是多个这类OLAP操作叠加的结果。
OLAP的架构模式
1. MOLAP(Multidimensional Online Analytical Processing)
MOLAP架构会生成一个新的多维数据集,也可以说是构建了一个实际数据立方体。其架构如下图所示:
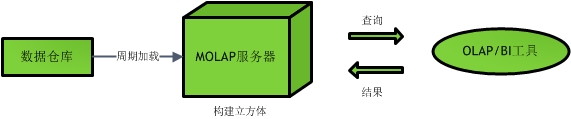
在该立方体中,每一格对应一个直接地址,且常用的查询已被预先计算好。因此每次的查询都是非常快速的,但是由于立方体的更新比较慢,所以是否使用这种架构得具体问题具体分析。
2. ROLAP(Relational Online Analytical Processing)
ROLAP架构并不会生成实际的多维数据集,而是使用星形模式以及多个关系表对数据立方体进行模拟。其架构如下图所示:

显然,这种架构下的查询没有MOLAP快速。因为ROLAP中,所有的查询都是被转换为SQL语句执行的。而这些SQL语句的执行会涉及到多个表之间的JOIN操作,没有MOLAP速度快。
3. HOLAP(Hybrid Online Analytical Processing)
这种架构综合参考MOLAP和ROLAP而采用一种混合解决方案,将某些需要特别提速的查询放到MOLAP引擎,其他查询则调用ROLAP引擎。
笔者发现一个有趣的现象,很多工具的发展都满足这个规律:工具A被创造,投入使用后发现缺点;然后工具B为了弥补这个缺点而被创造,但是带来了新的缺点;然后就会用工具C被创造,根据不同情况调用A和B。比较无语......
小结
本文是数据仓库系列的最后一篇。一路下来,读者有木有发现数据仓库系统的开发是一个非常浩大的工程呢?
确实,整个数据仓库系统的开发会涉及到各种团队:数据建模团队,业务分析团队,系统架构团队,平台维护团队,前端开发团队等等。对于志在从事这方面工作的人来说,需要学习的还有很多。但对于和笔者一样志在成为一名优秀"数据科学家"的人来说,这些数据基础知识已经够用了。笔者看来,数据科学家的核心竞争优势在三个方面:数据基础,数据可视化,算法模型。这三个方面需要投入的时间成本递增,而知识的重要性递减。因此,数据库系列和数据仓库系列是性价比最高的两个系列哦。
接下来,我将把目光聚焦到数据可视化系列,以及酝酿了很久的数据挖掘系列上来。数据管理好了,需要酷炫的show出来吧!需要进一步挖掘其价值吧!欢迎继续关注!!
转载:https://www.cnblogs.com/muchen/p/5318808.html
[转载] 第三篇:数据仓库系统的实现与使用(含OLAP重点讲解)的更多相关文章
- 第三篇:数据仓库系统的实现与使用(含OLAP重点讲解)
前言 上一篇重点讲解了数据仓库建模,它是数据仓库开发中最核心的部分.然而完整的数据仓库系统还会涉及其他一些组件的开发,其中最主要的是ETL工程,在线分析处理工具(OLAP)和商务智能(BI)应用等. ...
- Python笔记_第三篇_面向对象_2.构造函数和析构函数(含self说明)
1. 构造函数: 为什么要有构造函数? 打一个比方:类的创建就是好比你创建了好了一种格式的房间,你租给上一个住户的后,里面会对方很多“垃圾”和不规则的物品摆放.构造函数就是下一个住户再使用的时候进行物 ...
- SQLSERVER是怎麽通过索引和统计信息来找到目标数据的(第三篇)
SQLSERVER是怎麽通过索引和统计信息来找到目标数据的(第三篇) 最近真的没有什么精力写文章,天天加班,为了完成这个系列,硬着头皮上了 再看这篇文章之前请大家先看我之前写的第一篇和第二篇 第一篇: ...
- 从0开始搭建SQL Server 2012 AlwaysOn 第三篇(安装数据,配置AlwaysOn)
这一篇是从0开始搭建SQL Server 2012 AlwaysOn 的第三篇,这一篇才真正开始搭建AlwaysOn,前两篇是为搭建AlwaysOn 做准备的 操作步骤: 1.安装SQL server ...
- (转载) 从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn)
这一篇是从0开始搭建SQL Server AlwaysOn 的第三篇,这一篇才真正开始搭建AlwaysOn,前两篇是为搭建AlwaysOn 做准备的 步骤 这一篇依然使用step by step的方式 ...
- 数据仓库原理<2>:数据仓库系统的体系结构
1. 引言 本篇主要讲述数据仓库系统的体系结构与组成要素.数据集市与数据仓库之间的关系.元数据的定义与作用. 在上一篇,笔者介绍了数据仓库的定义: "数据仓库是一个面向主题的.集成的.不可更 ...
- 转载部长一篇大作:常用排序算法之JavaScript实现
转载部长一篇大作:常用排序算法之JavaScript实现 注:本文是转载实验室同门王部长的大作,找实习找工作在即,本文颇有用处!原文出处:http://www.cnblogs.com/ywang172 ...
- 转载——有感于三个50岁的美国程序员的生活状态与IT职业杂想
明天就是国庆节了,今天也不想干活干的太累了!写一篇以前去美国出差的杂想,对比于美国50多岁的程序员和大多数50多岁国内父母的生活状态有感而发. 前几年正好有一个项目的机会出差去了一次美国,地点是美国中 ...
- JDFS:一款分布式文件管理系统,第三篇(流式云存储)
一 前言 看了一下,距离上一篇博客的发表已经过去了4个月,时间过得好快啊.本篇博客是JDFS系列的第三篇博客,JDFS的目的是为了实现一个分布式的文件管理系统,前两篇实现了基本的上传.下载功能,但是那 ...
随机推荐
- pcl知识
1.pcl/io/pcd_io.h pcl/io/ply_io.h pcl::PLYReader reader; pcl::PCDWriter pcdwriter; 读取ply pcd 2.voidl ...
- Greeplum 系列(二) 安装部署
Greeplum 系列(二) 安装部署 本章将介绍如何快速安装部署 Greenplum,以及 Greenplum 的一些常用命令及工具.本章不会涉及硬件选型.操作系统参数讲解.机器性能测试等高级内容, ...
- js运算浮点数
在js中做小数:9.3+0.3会发现,得到的结果并不是9.6,而是9.600000000000001.这是为什么? Javascript采用了IEEE-745浮点数表示法,这是一种二进制表示法,可以精 ...
- 1056 IMMEDIATE DECODABILITY
题目链接: http://poj.org/problem?id=1056 题意: 给定编码集, 判断它是否为可解码(没有任何一个编码是其他编码的前缀). 分析: 简单题目, 遍历一遍即可, 只需判断两 ...
- SIP简介
说明:以下内容来着之前下载的一份文档,现将概念部分摘录在BLog,如需要完整文档将放在文件中或留言. SIP简介,第1部分:SIP初探 时间:2006-04-07作者:Emmanuel Proulx浏 ...
- 编写高质量代码改善C#程序的157个建议——建议130:以复数命名枚举类型,以单数命名枚举元素
建议130:以复数命名枚举类型,以单数命名枚举元素 枚举类型应该具有负数形式,它表达的是将一组相关元素组合起来的语义.比如: enum Week { Monday, Tuesday, Wednesda ...
- Alpha冲刺(五)
Information: 队名:彳艮彳亍团队 组长博客:戳我进入 作业博客:班级博客本次作业的链接 Details: 组员1 柯奇豪 过去两天完成了哪些任务 基于ssm框架的前后端交互测试,结合微信小 ...
- 洛谷P4172 [WC2006]水管局长(lct求动态最小生成树)
SC省MY市有着庞大的地下水管网络,嘟嘟是MY市的水管局长(就是管水管的啦),嘟嘟作为水管局长的工作就是:每天供水公司可能要将一定量的水从x处送往y处,嘟嘟需要为供水公司找到一条从A至B的水管的路径, ...
- java学习(三)数组
一维数组的定义格式: int[] a; //定义一个int类型的数组a变量 int a[]; //定义一个int类型的a数组变量 初始化一个int类型的数组 int[] arr = new i ...
- 20145233《网络对抗》Exp6 信息收集和漏洞扫描
20145233<网络对抗>Exp6 信息收集和漏洞扫描 实验问题思考 哪些组织负责DNS,IP的管理 全球根服务器均由美国政府授权的ICANN统一管理,负责DNS和IP地址管理.全球一共 ...