python高级(三)—— 字典和集合(泛映射类型)
本文主要内容
可散列类型
泛映射类型
字典
(1)字典推导式
(2)处理不存在的键
(3)字典的变种
集合
映射的再讨论
文中代码均放在github上:https://github.com/ampeeg/cnblogs/tree/master/python高级
可散列类型
''' |
''' |
泛映射类型
''' |
''' |
''' |
字典
''' |
(1)字典推导式
''' |
(2)处理不存在的键
''' |
(3)字典的变种
''' |
集合
''' |
set的操作方法很多,本文截自<流畅的python>一书,如下三个表: 表一:集合的数学方法
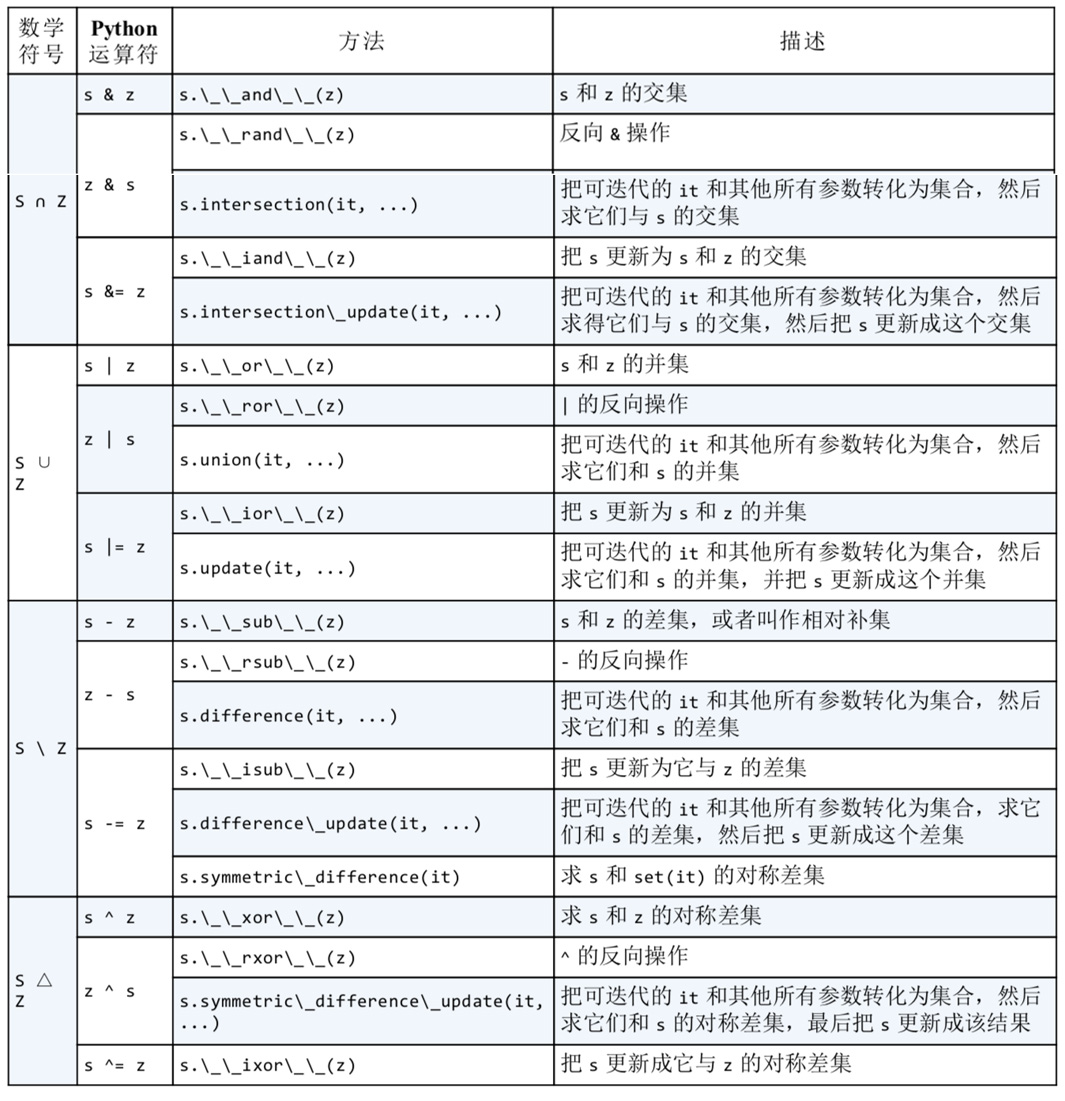 |
表2:集合的比较运算
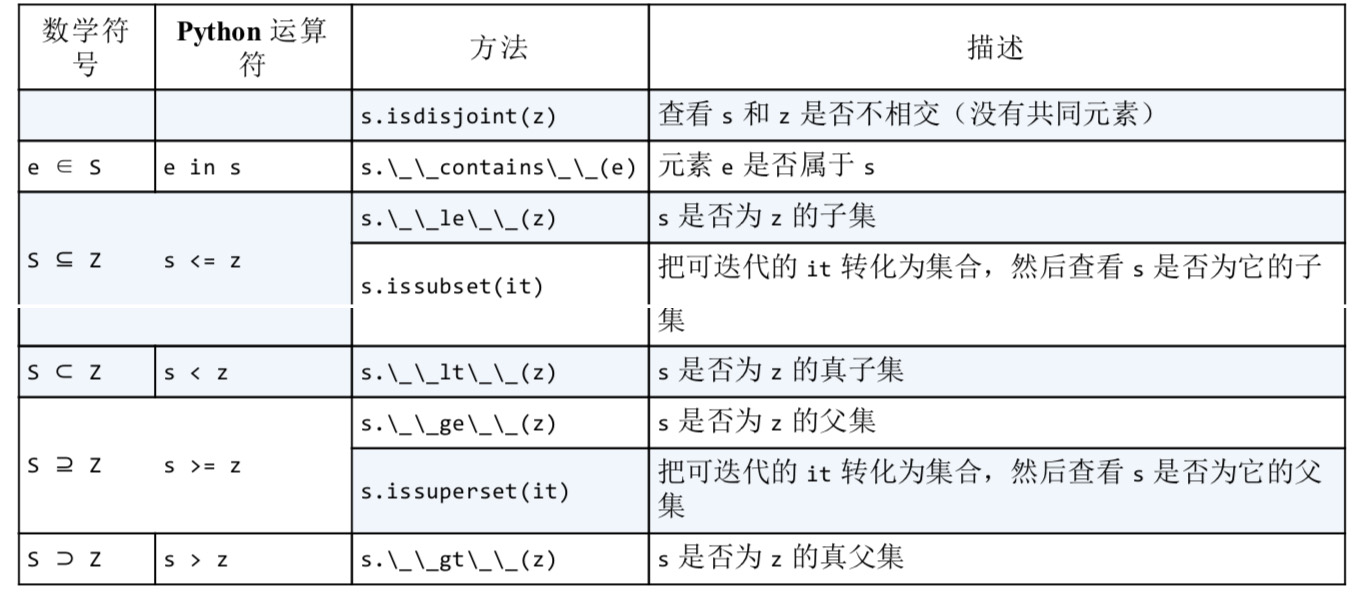 |
表3:集合的其他运算
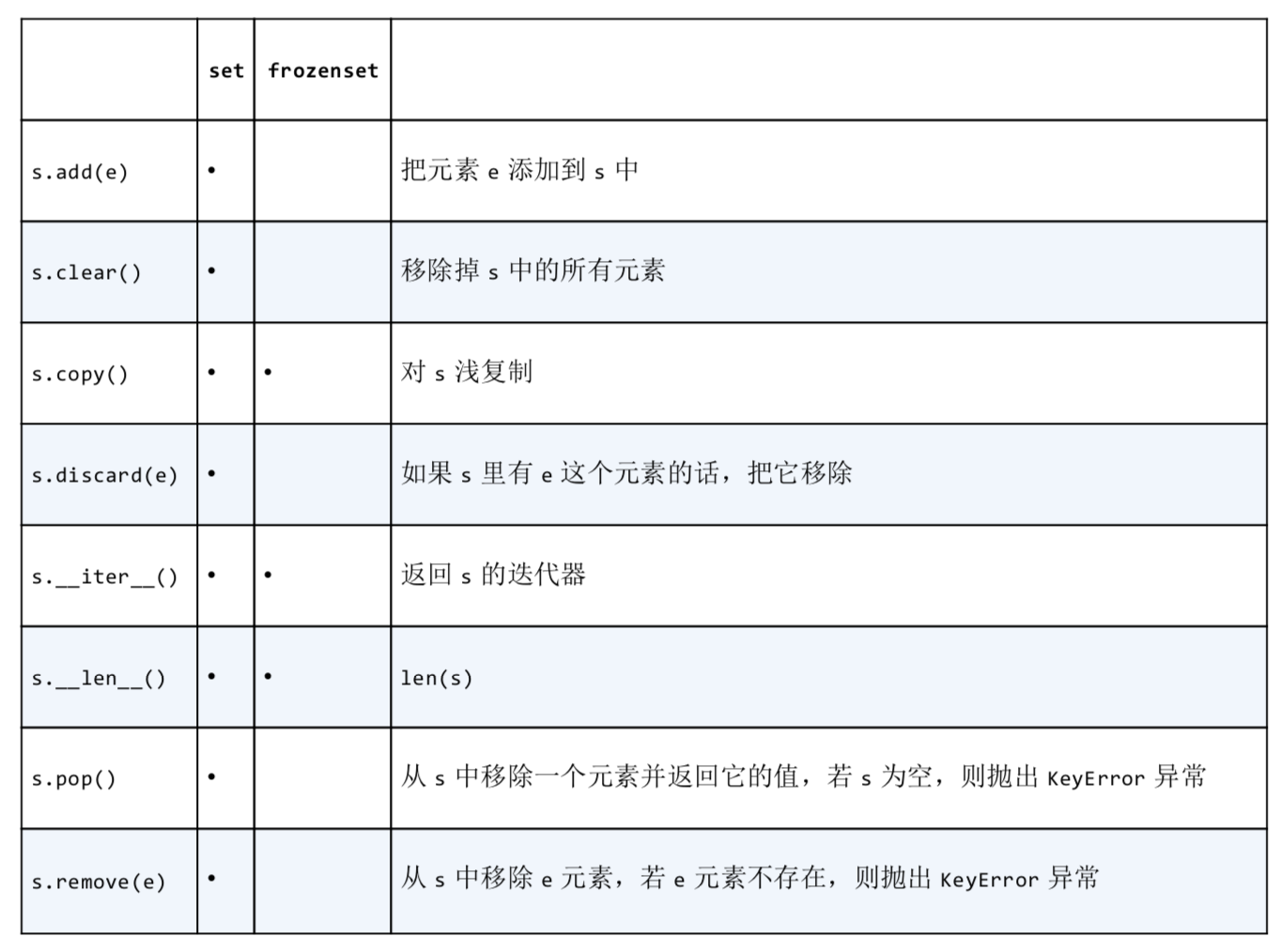 |
映射的再讨论
''' |
另外,《流畅的python》77页到80页对散列表算法以及字典、集合的效率、平时需要注意的问题进行了比较详细的探讨,建议严谨并有兴趣的同仁阅读,该部分内容对理解字典类型无比有益,场景中捉摸不透的莫名其妙的bug可能会迎刃而解。
重要的结论摘录如下:
(1)键必须是可散列的
(2)字典在内存上的开销巨大
(3)键查询很快
(4)键的次序取决于添加顺序
(5)往字典里添加新键可能会改变已有键的顺序
python高级系列文章目录
python高级(三)—— 字典和集合(泛映射类型)的更多相关文章
- Python中的字典与集合
今天我们来讲一讲python中的字典与集合 Dictionary:字典 Set:集合 字典的语法: Dictionary字典(键值对) 语法: dictionary = {key:value,key: ...
- Python基础__字典、集合、运算符
之前讨论的字符串.列表.元组都是有序对象,本节则重点讨论无序对象:字典与集合.一.字典 列表是Python中的有序集合,列表中的序指的是列表中的元素与自然数集形成了一个一一对应的关系.例如L=['I' ...
- python大法好——字典、集合
字典 前面我们说过列表,它适合于将值组织到一个结构中并且通过编号对其进行引用.字典则是通过名字来引用值的数据结构,并且把这种数据结构称为映射,字典中的值没有特殊的顺序,都存储在一个特定的键(key)下 ...
- Python数据类型(字典和集合)
1.5 Dictionary(字典) 在Python中,字典用放在花括号{}中一系列键-值对表示.键和值之间用冒号分隔,键-值对之间用逗号分隔. 在字典中,你想存储多少个键-值对都可以.每个键都与一个 ...
- [19/09/19-星期四] Python中的字典和集合
一.字典 # 字典 # 使用 {} 来创建字典 d = {} # 创建了一个空字典 # 创建一个保护有数据的字典 # 语法: # {key:value,key:value,key:value} # 字 ...
- python 数据类型三 (字典)
一.字典的介绍 字典(dict)是python中唯一的一个映射类型,它是以{}括起来的键值对组成,在dict中key是唯一的,在保存的时候,根据key来计算出一个内存地址,然后将key-value保存 ...
- python第三周:集合、函数、编码、文件
1.集合: 集合的创建: list_1 = set([1,2,3,4,5]) list_2 = set([2,3,44,7,8]) 集合的特性:集合是无序的,集合可以去掉重复的元素 集合的操作:求交集 ...
- Python中的字典和集合
一.字典(dict) 1. 概述 字典是Python唯一的映射类型. 只能使用不可变的对象(比如字符串)来作为字典的键,但是可以把不可变或可变的对象作为字典的值. 键值对在 ...
- python基础之字典、集合
一.字典(dictionary) 作用:存多个值,key-value存取,取值速度快 定义:key必须是不可变类型,value可以是任意类型 字典是一个无序的,可以修改的,元素呈键值对的形式,以逗号分 ...
- python初识数据类型(字典、集合、元组、布尔)与运算符
目录 python数据类型(dict.tuple.set.bool) 字典 集合 元组 布尔值 用户交互与输出 获取用户输入 输出信息 格式化输出 基本运算符 算术运算符 比较运算符 逻辑运算符 赋值 ...
随机推荐
- 面向对象的JavaScript-002
1. <script type="text/javascript"> // Define the Person constructor var Person = fun ...
- OpenGL坐标变换专题
OpenGL坐标变换专题(转) OpenGL通过相机模拟.可以实现计算机图形学中最基本的三维变换,即几何变换.投影变换.裁剪变换.视口变换等,同时,OpenGL还实现了矩阵堆栈等.理解掌握了有关坐 ...
- 使用python把图片存入数据库-乾颐堂
一般情况下我们是把图片存储在文件系统中,而只在数据库中存储文件路径的,但是有时候也会有特殊的需求:把图片二进制存入数据库. 今天我们采用的是python+mysql的方式 MYSQL 是支持把图片存入 ...
- linux sed命令详解-乾颐堂CCIE
简介 sed 是一种在线编辑器,它一次处理一行内容.处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的 ...
- SliceBox
SliceBox相当于一个轮播图插件,只不过是3D的. 先来查看它能实现的效果: 官网:http://tympanus.net/codrops/2011/09/05/slicebox-3d-image ...
- 回顾2017系列篇(三):UX设计大会,都预示了哪些设计趋势
2017已接近尾声,在这一年中,无数的UX大会和设计大会在世界各地召开.每一场会议的召开,都是界内精英人士经验的交流和智慧的碰撞.虽然2017年的会议都已过去,但每场会议上的话题探讨,尤其是界内精英们 ...
- Spring Data JPA初使用 *****重要********
Spring Data JPA初使用 我们都知道Spring是一个非常优秀的JavaEE整合框架,它尽可能的减少我们开发的工作量和难度. 在持久层的业务逻辑方面,Spring开源组织又给我们带来了同样 ...
- myeclipse快捷键记忆
提示 Alt+?自动排版 Ctrl+shift+f自动添加引入包 Ctrl+shift+O切换窗口 Ctrl+F6自动添加set get方法 Alt+shift+s r 查看都是哪里调用了该方法 Ct ...
- 通过cat方式生成yum源
cat >> /etc/yum.repos.d/centos7.repo << EOF[test-iso7]name=CentOS- - Mediabaseurl=http:/ ...
- 【转载】Zookeeper 安装和配置
[转载原文链接 ] Zookeeper的安装和配置十分简单, 既可以配置成单机模式, 也可以配置成集群模式. 下面将分别进行介绍. 单机模式 点击这里下载zookeeper的安装包之后, 解压到合适目 ...