Keras 回归 拟合 收集
案例1
from keras.models import Sequential
from keras.layers import Dense, LSTM, Activation
from keras.optimizers import adam, rmsprop, adadelta
import numpy as np
import matplotlib.pyplot as plt
#construct model
models = Sequential()
models.add(Dense(100, init='uniform',activation='relu' ,input_dim=1))
models.add(Dense(50, activation='relu'))
models.add(Dense(1,activation='tanh'))
adamoptimizer = adam(lr=0.001, beta_1=0.9, beta_2=0.999, decay=0.00001)
models.compile(optimizer='rmsprop', loss='mse',metrics=["accuracy"] ) #train data
dataX = np.linspace(-2 * np.pi,2 * np.pi, 1000)
dataX = np.reshape(dataX, [dataX.__len__(), 1])
noise = np.random.rand(dataX.__len__(), 1) * 0.1
dataY = np.sin(dataX) + noise models.fit(dataX, dataY, epochs=100, batch_size=10, shuffle=True, verbose = 1)
predictY = models.predict(dataX, batch_size=1)
score = models.evaluate(dataX, dataY, batch_size=10) print(score)
#plot
fig, ax = plt.subplots()
ax.plot(dataX, dataY, 'b-')
ax.plot(dataX, predictY, 'r.',) ax.set(xlabel="x", ylabel="y=f(x)", title="y = sin(x),red:predict data,bule:true data")
ax.grid(True) plt.show()

案例2:
import numpy as np import random
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense,Activation
from keras.optimizers import Adam,SGD X = np.linspace(1,20,1000)
X = X[:,np.newaxis]
y = np.sin(X) + np.random.normal(0,0.08,(1000,1))
min_max_scaler = MinMaxScaler((0,1))
y_train = min_max_scaler.fit_transform(y)
x_train = min_max_scaler.fit_transform(X) model1=Sequential()
model1.add(Dense(1000,input_dim = 1))
model1.add(Activation('relu'))
model1.add(Dense(1))
model1.add(Activation('sigmoid'))
adam = Adam(lr = 0.001)
sgd = SGD(lr = 0.1,decay=12-5,momentum=0.9)
model1.compile(optimizer = adam,loss = 'mse')
print('-------------training--------------')
model1.fit(x_train,y_train,batch_size= 12,nb_epoch = 500,shuffle=True)
Y_train_pred=model1.predict(x_train)
plt.scatter(x_train,y_train)
plt.plot(x_train,Y_train_pred,'r-')
plt.show()
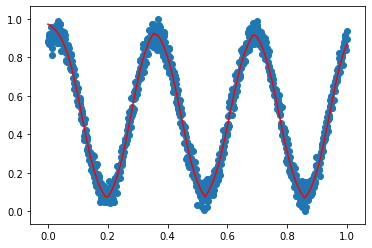
案例3
#加激活函数的方法2:model.add(Dense(units=10,input_dim=1,activation=' '))
from keras.optimizers import SGD
from keras.layers import Dense,Activation
#构建一个顺序模型
model=Sequential() #在模型中添加一个全连接层
#units是输出维度,input_dim是输入维度(shift+两次tab查看函数参数)
#输入1个神经元,隐藏层10个神经元,输出层1个神经元
model.add(Dense(units=10,input_dim=1,activation='relu')) #增加非线性激活函数
model.add(Dense(units=1,activation='relu')) #默认连接上一层input_dim=10 #定义优化算法(修改学习率)
defsgd=SGD(lr=0.3) #编译模型
model.compile(optimizer=defsgd,loss='mse') #optimizer参数设置优化器,loss设置目标函数 #训练模型
for step in range(3001):
#每次训练一个批次
cost=model.train_on_batch(x_data,y_data)
#每500个batch打印一个cost值
if step%500==0:
print('cost:',cost) #打印权值和偏置值
W,b=model.layers[0].get_weights() #layers[0]只有一个网络层
print('W:',W,'b:',b) #x_data输入网络中,得到预测值y_pred
y_pred=model.predict(x_data) plt.scatter(x_data,y_data) plt.plot(x_data,y_pred,'r-',lw=3)
plt.show()
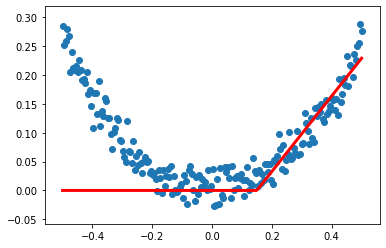
案例4:
#加激活函数的方法1:mode.add(Activation(''))
from keras.optimizers import SGD
from keras.layers import Dense,Activation
import numpy as np
np.random.seed(0)
x_data=np.linspace(-0.5,0.5,200)
noise=np.random.normal(0,0.02,x_data.shape)
y_data=np.square(x_data)+noise
#构建一个顺序模型
model=Sequential()
#在模型中添加一个全连接层
#units是输出维度,input_dim是输入维度(shift+两次tab查看函数参数)
#输入1个神经元,隐藏层10个神经元,输出层1个神经元
model.add(Dense(units=10,input_dim=1))
model.add(Activation('tanh')) #增加非线性激活函数
model.add(Dense(units=1)) #默认连接上一层input_dim=10
model.add(Activation('tanh'))
#定义优化算法(修改学习率)
defsgd=SGD(lr=0.3)
#编译模型
model.compile(optimizer=defsgd,loss='mse') #optimizer参数设置优化器,loss设置目标函数
#训练模型
for step in range(3001):
#每次训练一个批次
cost=model.train_on_batch(x_data,y_data)
#每500个batch打印一个cost值
if step%500==0:
print('cost:',cost)
#打印权值和偏置值
W,b=model.layers[0].get_weights() #layers[0]只有一个网络层
print('W:',W,'b:',b)
#x_data输入网络中,得到预测值y_pred
y_pred=model.predict(x_data)
plt.scatter(x_data,y_data)
plt.plot(x_data,y_pred,'r-',lw=3)
plt.show()
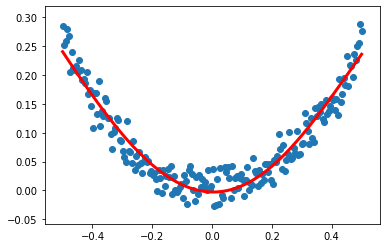
案列5
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam np.random.seed(0)
points = 500
X = np.linspace(-3, 3, points)
y = np.sin(X) + np.random.uniform(-0.5, 0.5, points) model = Sequential()
model.add(Dense(50, activation='sigmoid', input_dim=1))
model.add(Dense(30, activation='sigmoid'))
model.add(Dense(1))
adam = Adam(lr=0.01)
model.compile(loss='mse', optimizer=adam)
model.fit(X, y, epochs=50) predictions = model.predict(X)
plt.scatter(X, y)
plt.plot(X, predictions, 'ro')
plt.show()

案列6:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
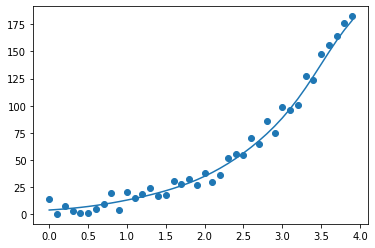
x = list(np.arange(0,4,0.1))
#给3次多项式添加噪音
y = list(map(lambda val: val**3*3 + np.random.random()*20 , x) ) plt.scatter(x, y) #指明用3次多项式匹配
w = np.polyfit (x, y, 3)
fn = np.poly1d(w) #打印适配出来的参数和函数
print(w)
print(fn) plt.plot(x, fn(x))
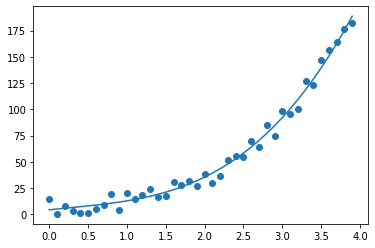
案列7
1 %matplotlib inline
2 import matplotlib.pyplot as plt
3 from keras.datasets import mnist
4 from keras.models import Sequential
5 from keras.layers.core import Dense, Activation
6 from keras.layers.advanced_activations import LeakyReLU, PReLU
7 from keras.optimizers import SGD
8
9 x = list(np.arange(0,4,0.1))
10 #给3次多项式添加噪音
11 y = list(map(lambda val: val**3*3 + np.random.random()*20 , x) )
12
13 model = Sequential()
14 #神经元个数越多,效果会越好,收敛越快,太少的话难以收敛到所需曲线
15 model.add(Dense(100, input_shape=(1,)))
16
17 #Relu,得到的是一条横线
18 #Tanh,稍稍好于Relu,但是拟合的不够
19 #sigmoid, 只要神经元个数足够(50+),训练1000轮以上,就能达到比较好的效果
20 model.add(Activation('sigmoid'))
21 #model.add(LeakyReLU(alpha=0.01))
22 #model.add(Dense(3))
23
24 model.add(Dense(1))
25 model.compile(optimizer="sgd", loss="mse")
26 model.fit(x, y, epochs=2000, verbose=0)
27
28 print(type(fn(3)))
29 print(fn(1))
30 print(fn(3))
31
32 plt.scatter(x, y)
33 plt.plot(x, model.predict(x))
Keras 回归 拟合 收集的更多相关文章
- [R] 回归拟合
如下示例 > fit <- lm(y~x, data = data01) > summary(fit) Call: lm(formula = data01$P ~ data01$M, ...
- NN:实现BP神经网络的回归拟合,基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat plot(NIR') title('Near infrared spectrum curve—Jason niu') temp = randperm(siz ...
- [DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 训练/开发/测试集 对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验 ...
- 局部加权回归LOWESS
1. LOWESS 用kNN做平均回归: \[ \hat{f(x)} = Ave(y_i | x_i \in N_k(x)) \] 其中,\(N_k(x)\)为距离点x最近k个点组成的邻域集合(nei ...
- logistic逻辑回归公式推导及R语言实现
Logistic逻辑回归 Logistic逻辑回归模型 线性回归模型简单,对于一些线性可分的场景还是简单易用的.Logistic逻辑回归也可以看成线性回归的变种,虽然名字带回归二字但实际上他主要用来二 ...
- 数学建模:1.概述& 监督学习--回归分析模型
数学建模概述 监督学习-回归分析(线性回归) 监督学习-分类分析(KNN最邻近分类) 非监督学习-聚类(PCA主成分分析& K-means聚类) 随机算法-蒙特卡洛算法 1.回归分析 在统计学 ...
- seaborn(2)---画分类图/分布图/回归图/矩阵图
二.分类图 1. 分类散点图 (1)散点图striplot(kind='strip') 方法1: seaborn.stripplot(x=None, y=None, hue=None, data=No ...
- sklearn调用逻辑回归算法
1.逻辑回归算法即可以看做是回归算法,也可以看作是分类算法,通常用来解决分类问题,主要是二分类问题,对于多分类问题并不适合,也可以通过一定的技巧变形来间接解决. 2.决策边界是指不同分类结果之间的边界 ...
- Machine Learning With Go 第4章:回归
4 回归 之前有转载过一篇文章:容量推荐引擎:基于吞吐量和利用率的预测缩放,里面用到了基本的线性回归来预测容器的资源利用情况.后面打算学一下相关的知识,译自:Machine Learning With ...
随机推荐
- 【Java并发工具类】原子类
前言 为保证计数器中count=+1的原子性,我们在前面使用的都是synchronized互斥锁方案,加锁独占访问的方式未免太过霸道,于是我们来介绍另一种解决原子性问题的无锁方案:原子变量.在正式介绍 ...
- Docker深入浅出系列 | 容器数据持久化
Docker深入浅出系列 | 容器数据持久化 Docker已经上市很多年,不是什么新鲜事物了,很多企业或者开发同学以前也不多不少有所接触,但是有实操经验的人不多,本系列教程主要偏重实战,尽量讲干货,会 ...
- vue垂死挣扎--遇到的问题
1, 原生js监听浏览器后退及禁用返回 +. 涉及到的history的知识 2, watch监听路由变化
- Apache Solr JMX服务 RCE 漏洞复现
Apache Solr JMX服务 RCE 漏洞复现 ps:Apache Solr8.2.0下载有点慢,需要的话评论加好友我私发你 0X00漏洞简介 该漏洞源于默认配置文件solr.in.sh中的EN ...
- EF--封装三层架构IOC
为什么分层? 不分层封装的话,下面的代码就是上端直接依赖于下端,也就是UI层直接依赖于数据访问层,分层一定要依赖抽象,满足依赖倒置原则,所以我们要封装,要分层 下面这张图和传统的三层略有不同,不同之处 ...
- ELK学习002:Elasticsearch 7.x 的安装及配置
Elasticsearch 的安装与启动 1.1 下载 Elasticsearch 7.6.0 下载地址:https://www.elastic.co/cn/downloads/elasticsear ...
- codeforces 995C
题意:从L到R 找有几个x,使x=a^p(a>0,p>1) 题解: 一开始把所有符合的次方都存到vector,然后MLE 可以看到1e6^3=1e18,所以可以将二次方单独来求,其他次方存 ...
- H5Demo_password_generator
原项目资源地址: https://www.html5tricks.com/js-passwd-generator.html codepen地址: https://codepen.io/deuscx/p ...
- Linux ps和pstree命令
1. 查看所有进程 ps -eF -e: Select all processes.-F: Extra full format. PSR (Processor)显示进程所在的CPU. 2. 查看所有进 ...
- CF 150E Freezing with Style [长链剖分,线段树]
\(sol:\) 给一种大常数 \(n \log^2 n\) 的做法 考虑二分,由于是中位数,我们就二分这个中位数,\(x>=mid\)则设为 \(1\),否则为 \(-1\) 所以我们只需要找 ...