Caffe实例
下载链接以及说明:
1.caffe代码按照官方教程下载windows分支下面的就可以了(https://github.com/BVLC/caffe/tree/windows)。
2.cmake(https://cmake.org/download/)
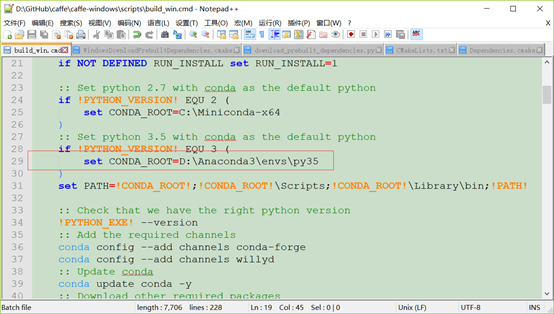
3.miniconda3 python3.6 x64(https://conda.io/miniconda.html) (注意:官方只能下载python 3.6版本的,在安装完python3.6版本的miniconda之后,注意在安装的时候将目录添加到环境变量中,然后命令行中执行:
conda create -n py35 python=3.5
anaconda,执行之后,会下载并安装python3.5下面的库,成功之后;
命令行中执行
activate py35,即可激活python3.5,但是当退出之后仍然是默认的3.6,这个时候命令行执行:
conda info --envs,可以看到有2个python环境:一个是root,一个是py35,并且可以看到py35这个包的安装路径。
然后在windows的环境变量中,把py35这个环境的路径和这个路径下的scripts路径添加到path路径中,
并在系统变量的path路径中删除掉原来的miniconda3/bin和miniconda3/scripts路径,这个再进入命令行中输入python,
默认就是python3.5了。
4.下载相应的caffe依赖包,地址https://github.com/willyd/caffe-builder/releases/ (注意我这里下载的是:libraries_v140_x64_py35_1.1.0.tar.bz2 ,这个文件非常难下载,我下载了很多次都没下载下来,如果有需要的,请看百度云链接: https://pan.baidu.com/s/1bp4hJiv 密码: zwn8)
Q: CMake Error
at D:/cmake/share/cmake-3.11/Modules/FindPackageHandleStandardArgs.cmake:137
(message):
Could NOT find Atlas (missing: Atlas_CLAPACK_INCLUDE_DIR
Atlas_CBLAS_LIBRARY Atlas_BLAS_LIBRARY Atlas_LAPACK_LIBRARY)
Call Stack (most recent call first):
solve:提示atlas错误,把BLAS 选项改为Open,意思是用OpenBlas
总算cmake成功了,接着就是编译了。
Caffe实例
Mnist数据转化成lemdb格式
mnist测试
可以参考http://blog.csdn.net/qq_14845119/article/details/52415090
mnist测试:
下面通过一个一个最简单的网络结构lenet来对刚才安装的caffe进行测试。
(1)去官网http://yann.lecun.com/exdb/mnist/下载mnist数据集。下载后解压到E:\caffe\data\mnist,如下图所示。
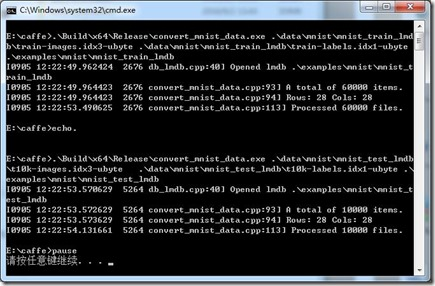
(2)在caffe根目录下,新建一个create_mnist.bat,里面写入如下的脚本:
.\Build\x64\Release\convert_mnist_data.exe
.\data\mnist\mnist_train_lmdb\train-images.idx3-ubyte
.\data\mnist\mnist_train_lmdb\train-labels.idx1-ubyte
.\examples\mnist\mnist_train_lmdb
echo.
.\Build\x64\Release\convert_mnist_data.exe
.\data\mnist\mnist_test_lmdb\t10k-images.idx3-ubyte
.\data\mnist\mnist_test_lmdb\t10k-labels.idx1-ubyte
.\examples\mnist\mnist_test_lmdb
pause
然后双击该脚本运行,即可在E:\caffe\examples\mnist下面生成相应的lmdb数据文件。
(3)修改E:\caffe\examples\mnist\lenet_solver.prototxt,将最后一行改为solver_mode:CPU,
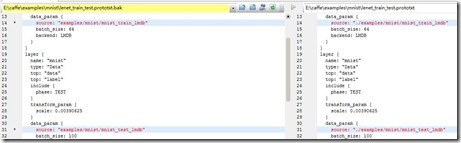
修改E:\caffe\examples\mnist\lenet_train_test.prototxt,如下所示,左面为原始的,右面为修改后的。
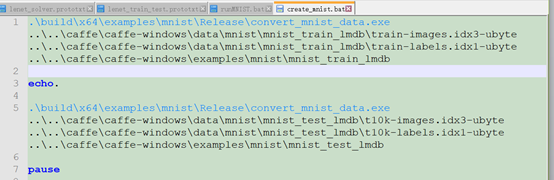
(4)在caffe根目录下,新建train_mnist.bat,然后输入如下的脚本,
.\Build\x64\Release\caffe.exetrain
--solver=.\examples\mnist\lenet_solver.prototxt
pause
然后双击运行,就会开始训练,训练完毕后会得到相应的准确率和损失率。

需要注意的是:
1.将他们都下载下来,在./data/mnist中建立两个文件夹分别装好

2. 写脚本语言是应核对好路径是否正确,要用自己的路径,不能照抄作者的。
3. 如果只用CPU,网络训练时间在一小时左右(可能是我笔记本配置低)
我的操作
一些错误,及解决办法
[libprotobuf ERROR
C:\Users\guillaume\work\caffe-builder\build_v140_x64\packages\protobuf\protobuf_download-prefix\src\p
rotobuf_download\src\google\protobuf\text_format.cc:298] Error
parsing text-format caffe.NetParameter: 14:17: Invalid es
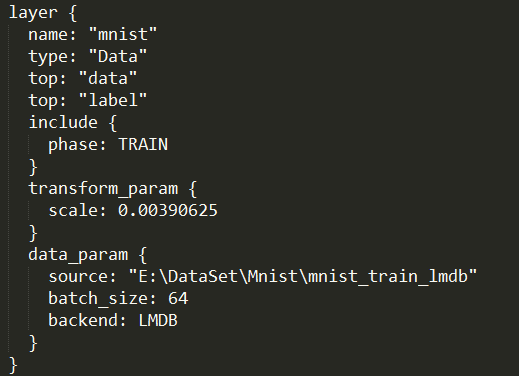
可以看出是解析lenet_train_test.prototxt出错,NetParameter后面跟的是错误的位置,比如第一个是14行17列,找到lenet_train_test.prototxt这个位置发现是’\’。
问题原因:
在windows中路径分隔符是’\’,比如我一开始直接复制lmdb的路径到prototxt中的:
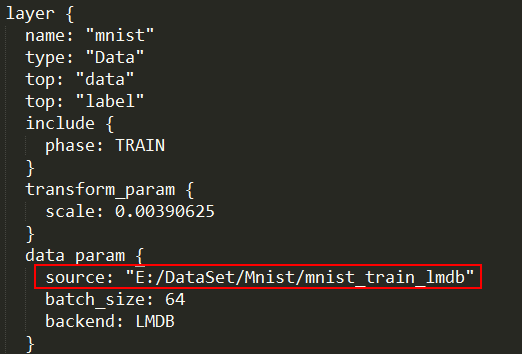
source这个字符串在c里面解析为转义,所以出错。
解决方法:
将‘\’改为‘/’或者‘\\’
我的
双击运行runMNIST.bat文件,训练数据集。
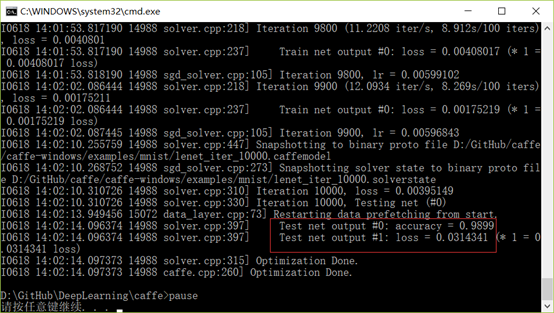
第一个测试程序已经完成了,准确度还挺高,下一步该研究网络结构了。
Caffe实例的更多相关文章
- [转]caffe+Ubuntu14.0.4 64bit 环境配置说明(无CUDA,caffe在CPU下运行) --for --Amd
caffe是一个简洁高效的深度学习框架,具体介绍可以看这里,caffe环境配置过程可以参考这里,我在搭建环境时搜集了许多资料,这里整理了一下,介绍一下caffe在无CUDA的环境下如何配置. 1. 安 ...
- caffe中在某一层获得迭代次数的方法以及caffe编译时报错 error: 'to_string' is not a member of 'std'解决方法
https://stackoverflow.com/questions/38369565/how-to-get-learning-rate-or-iteration-times-when-define ...
- 梳理caffe代码common(八)
因为想梳理data_layer的过程.整理一半发现有几个很重要的头文件就是题目列出的这几个: 追本溯源,先从根基開始学起.这里面都是些什么鬼呢? common类 命名空间的使用:google.cv.c ...
- 最近学习工作流 推荐一个activiti 的教程文档
全文地址:http://www.mossle.com/docs/activiti/ Activiti 5.15 用户手册 Table of Contents 1. 简介 协议 下载 源码 必要的软件 ...
- caffe的python接口学习(4):mnist实例---手写数字识别
深度学习的第一个实例一般都是mnist,只要这个例子完全弄懂了,其它的就是举一反三的事了.由于篇幅原因,本文不具体介绍配置文件里面每个参数的具体函义,如果想弄明白的,请参看我以前的博文: 数据层及参数 ...
- 运行caffe自带的mnist实例教程
运行caffe自带的mnist实例教程 本文结合几篇博文总结下来的,附上其中一篇原博文链接以供参考:http://blog.sina.com.cn/s/blog_168effc7e0102xjr1.h ...
- caffe mnist实例 --lenet_train_test.prototxt 网络配置详解
1.mnist实例 ##1.数据下载 获得mnist的数据包,在caffe根目录下执行./data/mnist/get_mnist.sh脚本. get_mnist.sh脚本先下载样本库并进行解压缩,得 ...
- caffe机器学习自带图片分类器classify.py实现输出预测结果的概率及caffe的web_demo例子运行实例
caffe机器学习环境搭建及python接口编译参见我的上一篇博客:机器学习caffe环境搭建--redhat7.1和caffe的python接口编译 1.运行caffe图片分类器python接口 还 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
随机推荐
- mysql 连接权限
命令解释: . 第一个表示库,第二个表示表; .对全部数据库的全部表授权,so.ok 表示只对so这个库中的ok表授权 root 表示要给哪个用户授权,这个用户可以是存在的用户,也可以是不存在的 '% ...
- POJ1273【网络流】
Drainage Ditches Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 91824 Accepted ...
- CSS一些特殊图形
CSS一些特殊图形 CSS绘制三角形 通过控制元素的border属性可以实现三角形效果; 首先来设置4个边框, 为50px solid [color] color设置成不同的颜色值看一下效果 < ...
- [CF1216C] White Sheet - 离散化,模拟
虽然分类讨论应该是比较推崇的解法,但是我就是喜欢暴力 #include <bits/stdc++.h> using namespace std; #define int long long ...
- Windows中配置MySQL环境变量
安装好MySQL后,在Windows环境下配置环境变量 1)新建MYSQL_HOME系统变量 配置MySQL的安装路径:C:\Program Files\MySQL\MySQL Server 5.7 ...
- 开放系统互联(OSI)模型
开放系统互联(OSI)模型 是由国际标准化组织(ISO)于1984年提出的一种标准参考模型,是一种关于由不同供应商提供的不同设备和应用软件之间的网络通信的概念性框架结构.它被公认为是计算机通信和 in ...
- 笔记本u盘插上不显示
u盘突然拔出笔记本再次插入时不显示: 解决方法:我的电脑-设备管理器-其他设备(你的U盘驱动)-卸载 再重新插上去,即可显示
- Windows下解决github push failed (remote: Permission to userA/XXXX.git denied to userB.) 上传gitHub失败报错
Windows环境下解决 github push failed (remote: Permission to userA/XXXX.git denied to userB.) · 初学GitHub的朋 ...
- Runtime.getRuntime.exec()执行linux脚本导致程序卡死有关问题
Runtime.getRuntime.exec()执行linux脚本导致程序卡死问题问题: 在Java程序中,通过Runtime.getRuntime().exec()执行一个Linux脚本导致程序被 ...
- poj1505(二分+贪心)
"最大值尽量小"是一种很常见的优化目标. 关乎于炒书. 题目见此: http://poj.org/problem?id=1505 我的copy的代码如下: #include< ...