4-MySQL拆分表
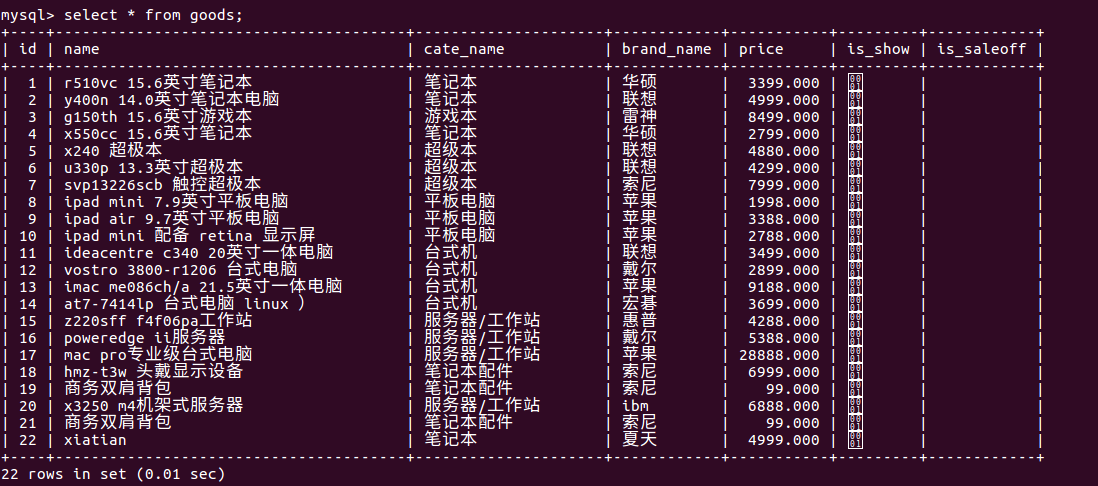
如上图,将goods表中的cate_name字段拆分一个商品分类表goods_cates,步骤如下:
1,创建商品分类表-goods_cates;
create table goods_cates( id int unsigned primary key auto_increment, name varchar(40) not null
);
2,将goods表数据根据字段cate_name分组,将分组后的商品种类信息添加到goods_cates表;
注: 这里insert into 语句没有values 关键字!
insert into goods_cates (name) select cate_name from goods group by cate_name;
3,同步表数据-使用goods_cates表的id字段数据更新goods表的cate_name字段数据;
update goods as g inner join goods_cates as c on g.cate_name=c.name set g.cate_name=c.id;
4,将goods表的cate_name字段修改为cate_id,并修改数据类型属性与goods_cates表的id字段的数据类型属性一致;
alter table goods change cate_name cate_id int unsigned not null;
5,在goods表中添加外键(foreign key)
外键约束:对数据的有效性进行验证
关键字: foreign key,只有 innodb数据库引擎 支持外键约束
在实际开发中,很少会使用到外键约束,会极大的降低表更新的效率
alter table goods add foreign key(cate_id) references goods_cates(id);
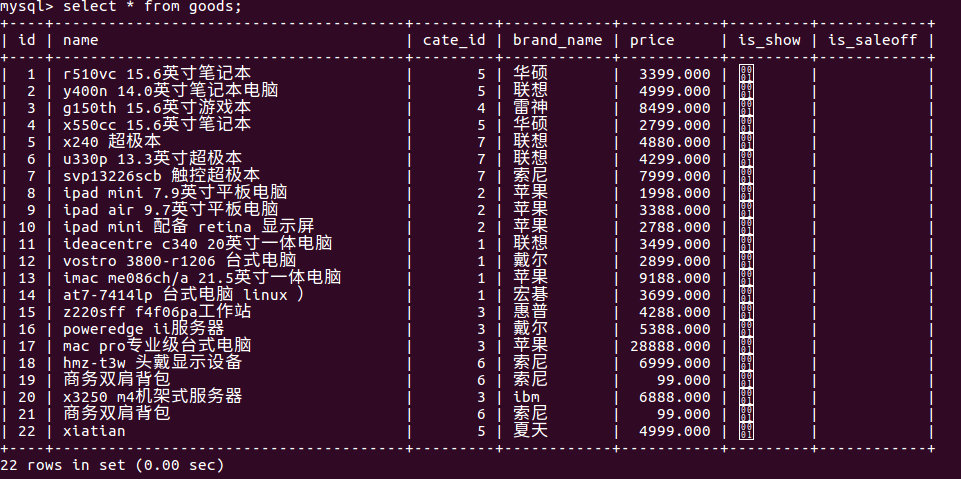
拆分后的goods表
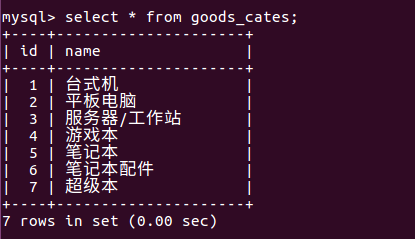
拆分后的goods_cates表
4-MySQL拆分表的更多相关文章
- MySQL建表规范与常见问题
一. 表设计 库名.表名.字段名必须使用小写字母,“_”分割. 库名.表名.字段名必须不超过12个字符. 库名.表名.字段名见名知意,建议使用名词而不是动词. 建议使用InnoDB存储引擎. 存储精确 ...
- mysql 分表策略
mysql单表数据量巨大时,查询性能会很差,经常遇到的是存储日志相关的数据会每天产生大量的数据. 这里提供单表拆分成多表存储的三个思路: 一,固定N张表,ID取模存储 预先创建好N张表,记录按ID取模 ...
- MySQL的表分区详解
这篇文章主要介绍了MySQL的表分区,例如什么是表分区.为什么要对表进行分区.表分区的4种类型详解等,需要的朋友可以参考下 一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysq ...
- 详解MySQL大表优化方案( 转)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- Mysql数据库表排序规则不一致导致联表查询,索引不起作用问题
Mysql数据库表排序规则不一致导致联表查询,索引不起作用问题 表更描述: 将mysql数据库中的worktask表添加ishaspic字段. 具体操作:(1)数据库worktask表新添是否有图片字 ...
- MySQL 大表优化方案探讨
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- MySQL的表分区(转载)
MySQL的表分区(转载) 一.什么是表分区 通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了. 如:某用户表的记录超过了600万条,那么就可以根据入库日期将表 ...
- Mysql iot表
我们知道一般的表都以堆(heap)的形式来组织的,这是无序的组织方式. Oracle还提供了一种有序的表,它就是索引组织表,简称IOT表.IOT表上必须要有主键,而IOT表本身不对应segment,表 ...
- mysql分表分库
单库单表 单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到. 单库多表 随着用户数量的增加,user表的数据量会越来越大,当数 ...
- MYSQL 分表实践
基本条件: 无索引 主表 test_0 数据:一百万条 数据库引擎 InnoDb 分表 test_1...test_100 数据 每张一万条,一共一百万条 数据库引擎 InnoDb 流程: 主表中 ...
随机推荐
- Useful code snippets with C++ boost
Useful code snippets with C++ boost Is Punctuation It’s very straight forward to use boost.regex as ...
- python redis demo
上代码,redis-demo #!/usr/bin/env python #_*_ coding:UTF-8 _*_ import redis ####配置参数 host = '192.168.0.1 ...
- git分布式版本控制系统权威指南学习笔记(五):git checkout
文章目录 分离头指针 通过cat可以查看当前的分支 通过branch查看当前分支 checkout commitId(真正的
- Mysql 命令行下建立存储过程
建立存储过程的sql如下: CREATE PROCEDURE proc_variable () BEGIN DECLARE dec_var_ VARCHAR(100); DECLARE rep_nu ...
- Webpack4篇
[Webpack4篇] webpack4 打包优化策略 当前依赖包的版本 1 优化loader配置 1.1 缩小文件匹配范围(include/exclude) 通过排除node_modules下的文件 ...
- javascript基础入门之js中的数据类型与数据转换01
javascript基础入门之js中的数据结构与数据转换01 js的组成(ECMAScript.BOM.DOM) js中的打印语句: 数据类型 变量 ...
- style优先级
不同级别 在属性后面使用 !important 会覆盖页面内任何位置定义的元素样式. 作为style属性写在元素内的样式 id选择器 类选择器 标签选择器 通配符选择器 浏览器自定义或继承 ...
- 使用jQuery的datetimepicker插件
因为后台系统要使用年月日时分的设置,又因为使用的Bootstrap框架只有datepicker和timepicker控件.所以在jQuery库中找到轻量级的datetimepicker插件,很好地解决 ...
- 通过反射来创建对象?getConstructor()和getDeclaredConstructor()区别?
1. 通过类对象调用newInstance()方法,适用于无参构造方法: 例如:String.class.newInstance() public class Solution { public st ...
- 普通浏览器实现点击打开微信app
给予点击事件,然后调用以下方法即可(我这用的是jq的点击): $(function() { Cz.Alert().success({text: '请返回公众号查看充值结果'}); $(".a ...