使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析系统(该系统目前用虚拟机实现了离线分析模块,实时分析由于资源问题尚未完成---这次spark集群用于该项目的实时分析)
一、根据架构图搭建基础环境

①Scala版本:2.13以及JDK版本:1.8.231,scala下载地址:https://www.scala-lang.org/download/(安装过程略)
②Docker版本:Docker version 19.03.5,下载地址:https://docs.docker.com/install/linux/docker-ce/centos/(安装过程略)
③搭建zookeeper集群(版本:3.4.14),下载地址:http://mirror.bit.edu.cn/apache/zookeeper/
④搭建hadoop集群(版本:2.7.7),下载地址:https://archive.apache.org/dist/hadoop/common/
⑤安装flume(版本:1.9.0),下载地址:http://flume.apache.org/download.html
⑥搭建Kafka集群(版本:2.4.0),下载地址:http://kafka.apache.org/downloads
⑦搭建HBase集群(版本:0.98.17),下载地址:https://archive.apache.org/dist/hbase/
⑧搭建Spark集群(版本:2.4.4),下载地址:https://www.apache.org/dyn/closer.lua/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
基于以上环境来搭建Spark集群,最终实现网站流量的实时分析(离线分析模块已完成)--------网站日志流量分析系统,鄙人使用6个容器来实现以上环境的搭建,如下所示

二、启动容器并固定IP
可参考鄙人博客:使用Docker搭建Hadoop集群(伪分布式与完全分布式)里面有固定ip相关说明。
1、Dockerfile构建具备ssh的centos镜像
1.1编写Dockerfile
FROM centos # 镜像的作者
MAINTAINER xiedong # 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
#安装openssh-clients
RUN yum install -y openssh-clients # 添加测试用户root,密码root,并且将此用户添加到sudoers里
RUN echo "root:root" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 启动sshd服务并且暴露22端口
RUN mkdir /var/run/sshd
EXPOSE
CMD ["/usr/sbin/sshd", "-D"]
Dockerfile
1.2构建镜像
docker build -t 'xd/centos-ssh' . #注意别忘记末尾的点
2、Dockerfile构建具备JDK1.8的centos镜像
2.1编写Dockerfile
#基于上一个ssh镜像构建
FROM xd/centos-ssh
#拷贝并解压jdk
ADD jdk-8u231-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1..0_231 /usr/local/jdk1.
ENV JAVA_HOME /usr/local/jdk1.
ENV PATH $JAVA_HOME/bin:$PATH
Dockerfile
2.2构建镜像
docker build -t 'xd/centos-jdk' .
3、查看构建镜像
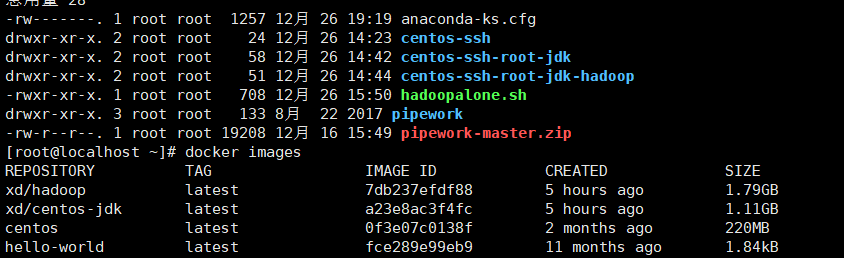
4、Docker容器数据卷共享文件
建议还是针对不同容器建立不同数据卷,鄙人为了方便,但是这样浪费空间了。
4.1 宿主机建立目录并上传软件
mkdir -p /home/container-softwares
4.2宿主机界面
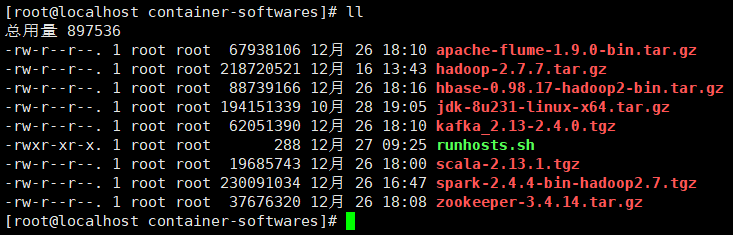
ps:runhosts.sh脚本用于配置hosts文件映射,后续需要ssh配置免密登录。
#!/bin/bash
echo 192.168.2.10 hadoop0 >> /etc/hosts
echo 192.168.2.11 hadoop1 >> /etc/hosts
echo 192.168.2.12 hadoop2 >> /etc/hosts echo 192.168.2.20 spark0 >> /etc/hosts
echo 192.168.2.21 spark1 >> /etc/hosts
echo 192.168.2.22 spark2 >> /etc/hosts
runhosts.sh
5、启动容器并固定IP
由于每次开机重启Docker、重启容器比较麻烦,所以弄一个脚本最好
5.1容器初始化脚本(第一次执行)
#/bin/bash
#启动Docker
sudo systemctl restart docker
echo "Docker restarts successfully!" #启动6个容器
#NameNode-zk-HBase-Flume
docker run --name hadoop0 --hostname hadoop0 -v /home/container-softwares:/home/container-softwares -d -P -p : -p : -p : xd/centos-jdk
echo "hadoop0 container start success====="
#DataNode--zk-HBase-Flume
docker run --name hadoop1 --hostname hadoop1 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk
echo "hadoop1 container start success====="
#DataNode-zk-HBase-Flume
docker run --name hadoop2 --hostname hadoop2 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk
echo "hadoop2 container start success=====" #spark0-kafka节点
docker run --name spark0 --hostname spark0 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk
echo "spark0 container start success======="
#spark1-kafka节点
docker run --name spark1 --hostname spark1 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk
echo "spark1 container start success====="
#spark2-kafka节点
docker run --name spark2 --hostname spark2 -v /home/container-softwares:/home/container-softwares -d -P xd/centos-jdk
echo "spark2 container start success=====" #固定IP========
#pipework下载
yum install -y wget bridge-utils unzip #wget https://github.com/jpetazzo/pipework/archive/master.zip unzip pipework-master-old.zip
mv pipework-master pipework
cp -rp pipework/pipework /usr/local/bin/ -f #创建网络
brctl addbr br0
ip link set dev br0 up
ip addr add 192.168.2.1/ dev br0
echo "网络创建完成正在固定IP"
pipework br0 hadoop0 192.168.2.10/
pipework br0 hadoop1 192.168.2.11/
pipework br0 hadoop2 192.168.2.12/ pipework br0 spark0 192.168.2.20/
pipework br0 spark1 192.168.2.21/
pipework br0 spark2 192.168.2.22/ echo "固定IP完成,正在测试" for i in {,,,,,}
do
ips=192.168..$i
result=`ping -w -c ${ips} | grep packet | awk -F" " '{print $6}'| awk -F"%" '{print $1}'| awk -F' ' '{print $1}'`
if [ $result -eq ]; then
echo ""${ips}" is ok !"
else
echo ""${ips}" is not connected ....."
fi done echo "测试完成"
Init初始化容器脚本
5.2 容器启动脚本(关机重启后执行)
注:该脚本用于已经初始化过的容器
#/bin/bash
#启动Docker
sudo systemctl restart docker
echo "Docker restarts successfully!" #启动6个容器
docker start hadoop0 hadoop1 hadoop2 spark0 spark1 spark2 #固定IP
brctl addbr br0
ip link set dev br0 up
ip addr add 192.168.2.1/ dev br0 pipework br0 hadoop0 192.168.2.10/
pipework br0 hadoop1 192.168.2.11/
pipework br0 hadoop2 192.168.2.12/ pipework br0 spark0 192.168.2.20/
pipework br0 spark1 192.168.2.21/
pipework br0 spark2 192.168.2.22/ echo "固定IP完成,正在测试" for i in {,,,,,}
do
ips=192.168..$i
result=`ping -w -c ${ips} | grep packet | awk -F" " '{print $6}'| awk -F"%" '{print $1}'| awk -F' ' '{print $1}'`
if [ $result -eq ]; then
echo ""${ips}" is ok !"
else
echo ""${ips}" is not connected ....."
fi done echo "测试完成"
start启动脚本
5.3容器停止脚本
#/bin/bash
sudo docker stop hadoop0 hadoop1 hadoop2 spark0 spark1 spark2
echo "容器已停止"
systemctl stop docker
echo "docker 服务已停"
stop停止脚本
5.4执行初始化脚本,出现以下界面说明成功
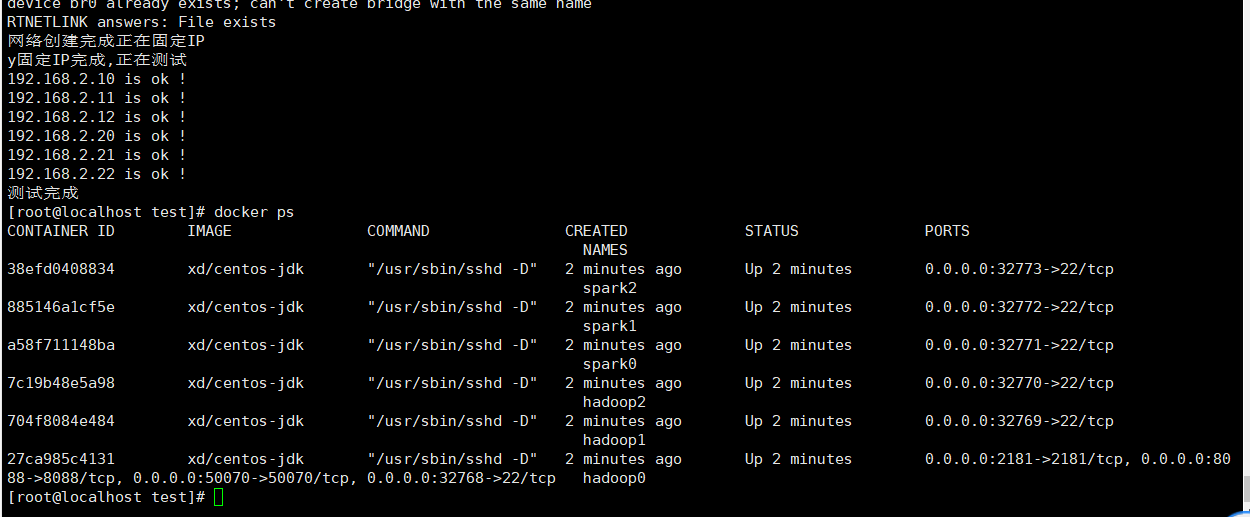
三、基础环境搭建
1、搭建Zookeeper集群
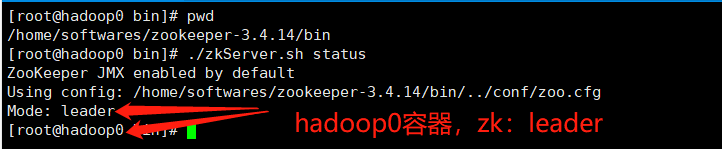
注:根据之前的部署结构,Zookeeper搭建在hadoop0、hadoop1、hadoop2这3个容器,安装过程可参考鄙人之前博客:zookeeper集群的搭建,其中Zookeeper的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
1.1Hadoop0容器zk角色为leader
1.2Hadoop1容器zk角色为follower

1.3Hadoop2容器zk角色为follower

2、搭建Hadoop集群
注:根据之前的部署结构,Hadoop集群搭建在hadoop0、hadoop1、hadoop2这3个容器,安装过程可参考鄙人之前博客:使用Docker搭建Hadoop集群(伪分布式与完全分布式),其中Hadoop的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
2.1Hadoop0容器有以下进程
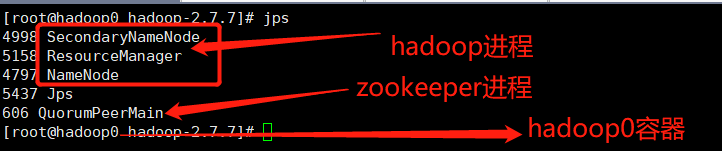
2.2Hadoop1容器有以下进程

2.3Hadoop2容器有以下进程

3、搭建HBase集群
注:根据之前的部署结构,HBase搭建在hadoop0、hadoop1、hadoop2这3个容器(安装过程可参考鄙人之前博客:HBase的完全分布式搭建),此HBase集群主要服务于Spark实时分析产生的中间临时数据(架构图中可查看),其中HBase的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
3.1Hadoop0容器有以下进程

3.2Hadoop1容器有以下进程

3.3Hadoop2容器有以下进程

4、搭建Kafka集群
注:根据之前的部署结构,Kafka搭建在spark0、spark1、spark2这3个容器(安装过程可参考鄙人之前博客:Kakfa概述及安装过程),Kafka负责接收Flume中心服务器产生的数据并对接spark用于实时分析,其中Kafka的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
4.1Spark0容器有以下进程

4.2Spark1容器有以下进程

4.3Spark2容器有以下进程

5、安装Flume
注:根据之前的部署结构,Flume搭建在hadoop0、hadoop1、hadoop2这3个容器(安装过程可参考鄙人之前博客:Flume学习笔记),Hadoop0的flume作为架构图中的FlumeAgent、另外2个容器中的flume作为中心日志服务器落地HDFS以及Kafka消息队列,其中Flume的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出),最终实现效果如下:
5.1Hadoop0容器的FlumeAgent相关配置
#声明Agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 #声明source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.regex = ^(?:[^\\|]*\\|){}\\d+_\\d+_(\\d+)\\|.*$
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.serializers.s1.name = timestamp #声明sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname =hadoop1
a1.sinks.k1.port = a1.sinks.k2.type = avro
a1.sinks.k2.hostname =hadoop2
a1.sinks.k2.port = a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random #声明channel
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = #绑定关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
FlumeAgent
ps:负责收集应用程序产生的日志并通过负载均衡分发给2个中心日志服务器
5.2Hadoop1与Hadoop2容器的Flume中心日志服务器相关配置
#声明Agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
#声明source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port =
#声明sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop0:9000/logdemo/reportTime=%Y-%m-%d
a1.sinks.k1.hdfs.rollInterval =
a1.sinks.k1.hdfs.rollSize =
a1.sinks.k1.hdfs.rollCount =
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.timeZone = GMT+
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.topic = fluxtopic
a1.sinks.k2.brokerList = spark0:,spark1:,spark2:
#声明channel
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity =
a1.channels.c2.type = memory
a1.channels.c2.capacity =
a1.channels.c2.transactionCapacity =
#绑定关系
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
FlumeServer
ps:中心日志服务器负责接收FlumeAgent客户端日志并落地HDFS以及分发Kafka(2个容器的配置相同)
6、搭建Spark集群
搭建好以上环境后,开始搭建Spark环境
注:根据之前的部署结构,Spark搭建在spark0、spark1、spark2这3个容器,其中Spark的相关安装包已经通过容器数据卷共享到容器内部路径:/home/container-softwares(可通过初始化脚本看出)
6.1配置环境变量
export SCALA_HOME=/usr/local/scala/scala-2.13.
export PATH=$PATH:$SCALA_HOME/bin
export JAVA_HOME=/usr/local/jdk1.
export SPARK_HOME=/home/softwares/spark-2.4.-bin-hadoop2.
export PATH=$PATH:$SPARK_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
6.2修改配置文件spark-env.sh(增加以下配置)
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/usr/local/jdk1.
export SCALA_HOME=/usr/local/scala/scala-2.13.
export SPARK_MASTER_IP=192.168.2.20
export SPARK_WORKER_MEMORY=512m
export HADOOP_CONF_DIR=/home/softwares/hadoop-2.7./etc/hadoop
6.3编辑slaves
cp slaves.template slaves
vim slaves #增加如下配置
spark0
spark1
spark2
6.4拷贝至其他2个容器
scp -rq spark-2.4.-bin-hadoop2. spark1:/home/softwares/
scp -rq spark-2.4.-bin-hadoop2. spark2:/home/softwares/
6.5启动spark集群
sbin目录执行:./start-all.sh
6.6spark0容器有以下进程

6.7spark0容器有以下进程

6.8spark0容器有以下进程

至此、已经完成Spark集群的搭建,下一篇编写scala代码实现网站流量实时分析:Scala实现网站流量实时分析
使用Docker搭建Spark集群(用于实现网站流量实时分析模块)的更多相关文章
- Docker 搭建 etcd 集群
阅读目录: 主机安装 集群搭建 API 操作 API 说明和 etcdctl 命令说明 etcd 是 CoreOS 团队发起的一个开源项目(Go 语言,其实很多这类项目都是 Go 语言实现的,只能说很 ...
- 从0到1搭建spark集群---企业集群搭建
今天分享一篇从0到1搭建Spark集群的步骤,企业中大家亦可以参照次集群搭建自己的Spark集群. 一.下载Spark安装包 可以从官网下载,本集群选择的版本是spark-1.6.0-bin-hado ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- 庐山真面目之十二微服务架构基于Docker搭建Consul集群、Ocelot网关集群和IdentityServer版本实现
庐山真面目之十二微服务架构基于Docker搭建Consul集群.Ocelot网关集群和IdentityServer版本实现 一.简介 在第七篇文章<庐山真面目之七微服务架构Consul ...
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
- Docker搭建PXC集群
如何创建MySQL的PXC集群 下载PXC集群镜像文件 下载 docker pull percona/percona-xtradb-cluster 重命名 [root@hongshaorou ~]# ...
- 搭建spark集群
搭建spark集群 spark1.6和hadoop2.61.准备hadoop环境:2.准备下载包:3.解压安装包:tar -xf spark-1.6.0-bin-hadoop2.6.tgz4.修改配置 ...
- Docker搭建RabbitMQ集群
Docker搭建RabbitMQ集群 Docker安装 见官网 RabbitMQ镜像下载及配置 见此博文 集群搭建 首先,我们需要启动运行RabbitMQ docker run -d --hostna ...
随机推荐
- Eclipse的使用配置
Eclipse 是一个开放源代码的.基于Java的可扩展开发平台.目前许多开发者开发时仍会选择使用Eclipse,很多初学者刚开始接触Java也是从使用Eclipse开始的.本篇博客主要介绍Eclip ...
- Docker最全教程——从理论到实战(十二)
前言 Ubuntu是一个以桌面应用为主的开源GNU/Linux操作系统,应用很广.本篇主要讲述Ubuntu下使用SSH远程登录并安装Docker,并且提供了Docker安装的两种方式,希望对大家有所帮 ...
- 题解【洛谷P3958】[NOIP2017]奶酪
题面 题解 我们考虑使用一个并查集维护空洞之间的关系. 如果两个空洞能相互到达,那么它们的祖先也是相同的. 枚举从哪一个空洞开始,能否到达奶酪的上表面. 如果能到达就输出Yes,否则输出No. 注意开 ...
- C#中ESRI.ArcGIS.esriSystem的引用问题
ESRI.ArcGIS.esriSystem,在引用里没有它的同名引用,其实它对应的引用为ESRI.ArcGIS.System,所以添加“ESRI.ArcGIS.System”这个引用即可
- log设计网站,一站式一键设计log网站
log设计网站,一站式一键设计log网站 log设计网站,一键式一站式设计log网站 待办 https://www.wix.com/buildyourwebsite5/designlogo?utm_s ...
- koa2第一天
router.get("/hello",async(ctx )=>{ const a=await new Promise(reslove=>reslove(123)) ...
- 题解【洛谷P3884】[JLOI2009]二叉树问题
题面 题解 这道题目可以用很多方法解决,这里我使用的是树链剖分. 关于树链剖分,可以看一下我的树链剖分学习笔记. 大致思路是这样的: 第\(1\)次\(dfs\)记录出每个点的父亲.重儿子.深度.子树 ...
- node 崩 处理
node_modules->bin webpack-dev-server.cmd @IF EXIST "%~dp0\node.exe" ( "%~dp0\node. ...
- STA之PVT
在STA星球,用library PVT.RC corner跟OCV来模拟这些不可控的随机因素.在每个工艺结点,通过大量的建模跟实测,针对每个具体的工艺,foundary厂都会提供一张推荐的timing ...
- library 中的internal power为何为负值?
下图是library中一个寄存器Q pin 的internal_power table, 表中该pin 的internal power 大多都是负值.其实library 中的internal_powe ...