保存数据到文件的模块(json,pickle,shelve,configparser,xml)_python
一、各模块的主要功能区别
json模块:将数据对象从内存中完成序列化存储,但是不能对函数和类进行序列化,写入的格式是明文。 (与其他大多语言交互的类型)
pickle模块:将数据对象从内存中完成序列化存储,可以能对函数进行序列化,写入的格式是二进制格式wb。 (支持python的所有数据类型,python特有的)
configparser模块:保存字典内容到文件,并按照一定的格式写入文件保存。
shelve模块:将对象写入到文件,保存没有格式。(较为轻便好用)

xml模块:不同语言或程序之间数据交换(早期常用,目前较少用,逐渐被json取代)。
二、各模块使用例子
1、configparser模块
(1)写入文件
import configparser
config=configparser.ConfigParser()
config['default']={'name':'chen','age':21,'sex':'male'} #字典格式的内容1
config['default2']={'class':'1','num':'43','team':'6'} #字典格式的内容2
f=open('configfile','w') #创建一个文本
config.write(f) #将字典内容写入文本
保存格式:

(2)读取文件内容
config=configparser.ConfigParser()
config.read('configfile.ini')
print(config.sections()) #['default', 'default2'],查看键值
print(config['default']['age']) #21,读取分区里面键值内容 (3)修改文件内容
config=configparser.ConfigParser()
config.read('configfile.ini') #先读取文件放到内存
config.remove_section('default2') #对内存文件进行修改,这里是删除分区
config.set('default','name','chenchenchen') #将分区里面的'name'键对应的值改为'chenchen'
config.add_section('ddd') #增加分区
config.set('ddd','dddd','ddddd') #添加分区内容
f=open('configfile.ini','w') #直接覆盖
config.write(f) #将已修改的内存文件内容保存到硬盘文件 2、shelve模块(较为轻便,好用)
(1)写入文件
import shelve
f=shelve.open('shelvetest') #创建文件
f['default']=1 #写入内容,值可以是数值,字典,函数等等数据类型
f.close()
(2)读取文件
f=shelve.open('shelvetest') #创建文件
data=f.get('default')
print(data) #1
f['default']={'name':'chen','age':21,'sex':'male'}
data=f.get('default')
print(data) #{'name': 'chen', 'age': 21, 'sex': 'male'}
保存格式:

3、json模块
(1)写入文件
import json
dic={'name': 'chen', 'age': 21, 'sex': 'male'}
data=json.dumps(dic) #序列化简化
f=open('json.txt','w')
f.write(data) #写入
f.close()
保存格式:明文

(2)读取文件
f=open('json.txt','r')#打开文件
data=f.read() #读取文件
data=json.loads(data) #反序列化,反简化
print(data)
注:一般使用dump一次和load一次,否则数据容易混乱
4、pickle模块(对比json,可以对包括函数和类的对象做序列化)
(1)写入文件
import pickle
def add():
print('add')
data=pickle.dumps(add)
f=open('pickle.txt','wb') #注意这里写入的是二进制格式,不是明文,这也是与json不同的点
f.write(data)
f.close()
保存格式:

(2)读取文件
f=open('pickle.txt','rb') #对应也是需要二进制b读取
data=f.read()
data=pickle.loads(data) #取出变量名
data() #函数取出的是变量名add,需要执行的话脚本里面还要有add函数本体。若是保存其他对象的话,可以直接打印,如列表
json和pickle模块通用方法:
dump(简化,相当于dumps和write的功能)
f=open('pickle.txt','wb')
data=pickle.dump(add,f) #相当于后面两行
# data=pickle.dumps(add)
# f.write(data)
f.close()
load(简化,相当于loads和read的功能)
f=open('pickle.txt','rb')
data=pickle.load(f) #相当于后面两行一起
# data=f.read()
# data=pickle.loads(data) #
print(data)
5、xml模块(了解)
不同语言或程序之间数据交换的协议
(1)python处理xml


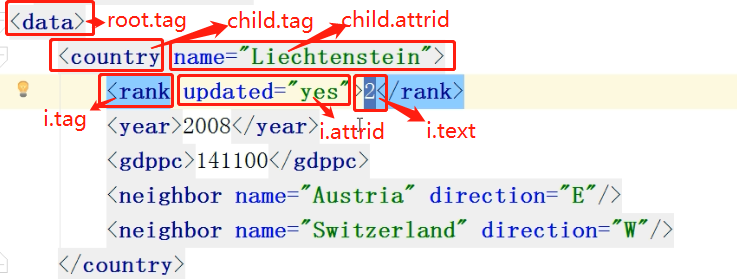

(2)修改
读取之后修改写回

修改之后:

(3)删除:

(4)创建:

保存数据到文件的模块(json,pickle,shelve,configparser,xml)_python的更多相关文章
- python 全栈开发,Day25(复习,序列化模块json,pickle,shelve,hashlib模块)
一.复习 反射 必须会 必须能看懂 必须知道在哪儿用 hasattr getattr setattr delattr内置方法 必须能看懂 能用尽量用__len__ len(obj)的结果依赖于obj. ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- python模块--json \ pickle \ shelve \ XML模块
一.json模块 之前学习过的eval内置方法可以将一个字符串转成一个python对象,不过eval方法时有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,e ...
- python开发模块基础:序列化模块json,pickle,shelve
一,为什么要序列化 # 将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化'''比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?现在我们能想到的方法就是存在文 ...
- python序列化模块 json&&pickle&&shelve
#序列化模块 #what #什么叫序列化--将原本的字典.列表等内容转换成一个字符串的过程叫做序列化. #why #序列化的目的 ##1.以某种存储形式使自定义对象持久化 ##2.将对象从一个地方传递 ...
- python_ 模块 json pickle shelve
一,什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代码( ...
- 模块 - json/pickle/shelve/xml/configparser
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化: 有种办法可以直接把内存数据(eg:10个列表,3 ...
- 序列化 json pickle shelve configparser
一 什么是 序列化 在我们存储数据或者 网络传输数据的时候,需要对我们的 对象进行处理,把对象处理成方便我们存储和传输的 数据格式,这个过程叫序列化,不同的序列化,结果也不相同,但是目的是一样的,都是 ...
- 常用模块(json/pickle/shelve/XML)
一.json模块(重点) 一种跨平台的数据格式 也属于序列化的一种方式 介绍模块之前,三个问题: 序列化是什么? 我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化. 反序列化又是什么? 将 ...
随机推荐
- Jenkins集成jacoco收集集成测试覆盖率
Jenkins集成jacoco收集集成测试覆盖率 2020-02-28 目录 0 整体思路1 安装版本2 全局工具配置3 Jenkins创建JacocoIntegrateTestDemo项目 3.1 ...
- #AcWing系列课程Level-2笔记——3. 整数二分算法
整数二分算法 编写整数二分,记住下面的思路,代码也就游刃有余了! 1.首先找到数组的中间值,mid=(left+right)>>1,区间[left, right]被划分成[left, mi ...
- 关于Git GUI克隆代码
1.首先需要使用Git GUI生成一个SSH秘钥并将其拷贝到远程(码云或者GitHub)账号下的SSH公钥中(以码云为例) 将上一步生成的SSH密钥拷贝到下面的码云的公钥中 2.拷贝下码云上代码的SS ...
- UVA750回溯法典例-八皇后
文章代码选自UVA750-8 Queens Chess Problem的部分代码 vj题目链接:https://vjudge.net/problem/UVA-750 由于UVA中要求按照字典序输出,下 ...
- 畅通工程 HDU - 1232 并查集板子题
#include<iostream> #include<cstring> using namespace std; ; int p[N]; int find(int x) { ...
- V-Box
Not ) (VERR_NEM_NOT_AVAILABLE). VT-x is disabled in the BIOS for all CPU modes (VERR_VMX_MSR_ALL_VMX ...
- 论文阅读笔记(十一)【ICCV2017】:Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification
Introduction (1)Motivation: 当前采用CNN-RNN模型解决行人重识别问题仅仅提取单一视频序列的特征表示,而没有把视频序列匹配间的影响考虑在内,即在比较不同人的时候,根据不同 ...
- 微信小程序报错TypeError: this.setData is not a function
今天在练习小程序的时候,遇到小程序报错 对于处于小白阶段的我,遇到这种报错,真还不知道是错从何来,只有一脸蒙逼,后来通过查询,终于知道了问题所在,下面对这一问题做一记录 小程序默认中是这么写的 onL ...
- mysql 视图、触发器、事务、存储过程、函数
一 视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,可以将该结果集当做表来使用. 使用视图我们可以把查询过程中的 ...
- php实现简易留言板效果
首先是Index页面效果图 index.php <?php header('content-type:text/html;charset=utf-8'); date_default_timezo ...