pytorch中如何处理RNN输入变长序列padding
一、为什么RNN需要处理变长输入
假设我们有情感分析的例子,对每句话进行一个感情级别的分类,主体流程大概是下图所示:
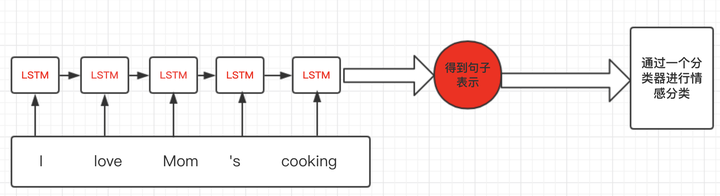
思路比较简单,但是当我们进行batch个训练数据一起计算的时候,我们会遇到多个训练样例长度不同的情况,这样我们就会很自然的进行padding,将短句子padding为跟最长的句子一样。
比如向下图这样:
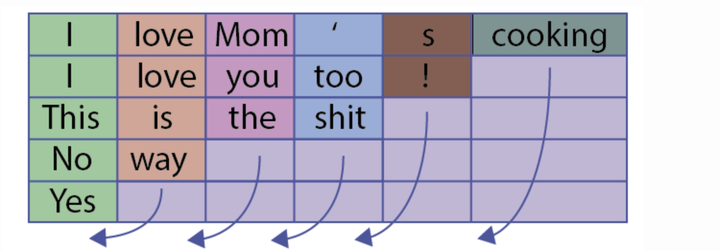
但是这会有一个问题,什么问题呢?比如上图,句子“Yes”只有一个单词,但是padding了5的pad符号,这样会导致LSTM对它的表示通过了非常多无用的字符,这样得到的句子表示就会有误差,更直观的如下图:
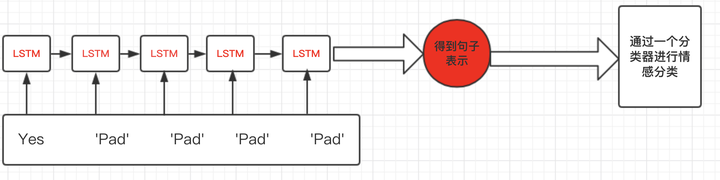
那么我们正确的做法应该是怎么样呢?
这就引出pytorch中RNN需要处理变长输入的需求了。在上面这个例子,我们想要得到的表示仅仅是LSTM过完单词"Yes"之后的表示,而不是通过了多个无用的“Pad”得到的表示:如下图:
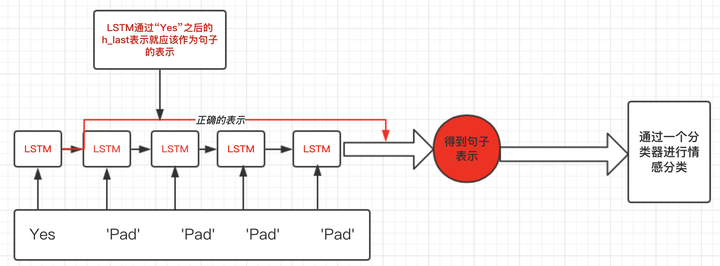
二、pytorch中RNN如何处理变长padding
主要是用函数torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()来进行的,分别来看看这两个函数的用法。
这里的pack,理解成压紧比较好。 将一个 填充过的变长序列 压紧。(填充时候,会有冗余,所以压紧一下)
输入的形状可以是(T×B×* )。T是最长序列长度,B是batch size,*代表任意维度(可以是0)。如果batch_first=True的话,那么相应的 input size 就是 (B×T×*)。
Variable中保存的序列,应该按序列长度的长短排序,长的在前,短的在后(特别注意需要进行排序)。即input[:,0]代表的是最长的序列,input[:, B-1]保存的是最短的序列。
参数说明:
input (Variable) – 变长序列 被填充后的 batch
lengths (list[int]) – Variable 中 每个序列的长度。(知道了每个序列的长度,才能知道每个序列处理到多长停止)
batch_first (bool, optional) – 如果是True,input的形状应该是B*T*size。
返回值:
一个PackedSequence 对象。一个PackedSequence表示如下所示:
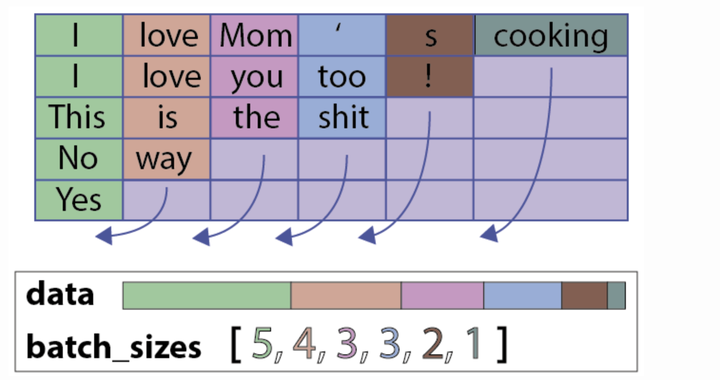
具体代码如下:
embed_input_x_packed = pack_padded_sequence(embed_input_x, sentence_lens, batch_first=True)
encoder_outputs_packed, (h_last, c_last) = self.lstm(embed_input_x_packed)此时,返回的h_last和c_last就是剔除padding字符后的hidden state和cell state,都是Variable类型的。代表的意思如下(各个句子的表示,lstm只会作用到它实际长度的句子,而不是通过无用的padding字符,下图用红色的打钩来表示):
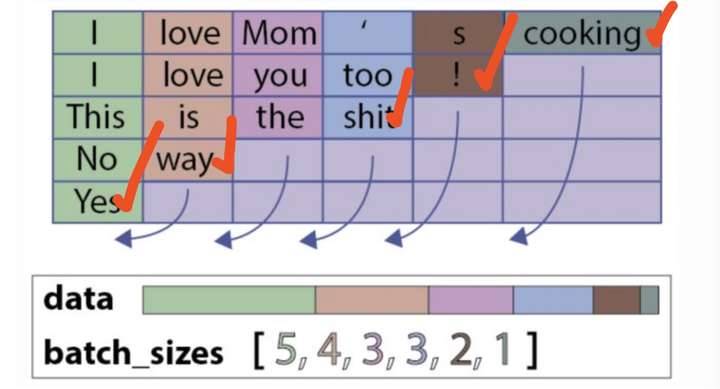
但是返回的output是PackedSequence类型的,可以使用:
encoder_outputs, _ = pad_packed_sequence(encoder_outputs_packed, batch_first=True)将encoderoutputs在转换为Variable类型,得到的_代表各个句子的长度。
三、总结
这样综上所述,RNN在处理类似变长的句子序列的时候,我们就可以配套使用torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()来避免padding对句子表示的影响
参考:
pytorch中如何处理RNN输入变长序列padding的更多相关文章
- keras: 在构建LSTM模型时,使用变长序列的方法
众所周知,LSTM的一大优势就是其能够处理变长序列.而在使用keras搭建模型时,如果直接使用LSTM层作为网络输入的第一层,需要指定输入的大小.如果需要使用变长序列,那么,只需要在LSTM层前加一个 ...
- pytorch 对变长序列的处理
一开始写这篇随笔的时候还没有了解到 Dateloader有一个 collate_fn 的参数,通过定义一个collate_fn 函数,其实很多batch补齐到当前batch最长的操作可以放在colla ...
- GCC 中零长数组与变长数组
前两天看程序,发现在某个函数中有下面这段程序: int n; //define a variable n int array[n]; //define an array with length n 在 ...
- 0-3为变长序列建模modeling variable length sequences
在本节中,我们会讨论序列的长度是变化的,也是一个变量 we would like the length of sequence,n,to alse be a random variable 一个简单的 ...
- 在C#中如何定义一个变长的结构数组?如果定义好了,如何获得当前数组的长度?
用ArrayList,他就相当于动态数组,用add方法添加元素,remove删除元素,count计算长度
- [改善Java代码]若有必要,使用变长数组
Java中的数组是定长的,一旦经过初始化声明就不可改变长度,这在实际使用的时候非常不方便.比如要对一个班级的学生信息进行统计,因为我们不知道班级会有多少个学生(随时可能有退学,入学,转学),所以需要一 ...
- pytorch 中的重要模块化接口nn.Module
torch.nn 是专门为神经网络设计的模块化接口,nn构建于autgrad之上,可以用来定义和运行神经网络 nn.Module 是nn中重要的类,包含网络各层的定义,以及forward方法 对于自己 ...
- scala学习手记21 - 传递变长参数
在Java中是可以使用变长参数的,如下面的方法: public void check(String ... args){ for(String tmp : args){ System.out.prin ...
- Pytorch基础——使用 RNN 生成简单序列
一.介绍 内容 使用 RNN 进行序列预测 今天我们就从一个基本的使用 RNN 生成简单序列的例子中,来窥探神经网络生成符号序列的秘密. 我们首先让神经网络模型学习形如 0^n 1^n 形式的上下文无 ...
随机推荐
- golang字符串常用系统函数
- 使用mpvue开发github小程序总结
前言 最近有点闲,想起关注已久的mpvue写小程序,所以稍微肝了半个多月写了个github版的微信小程序,已上线.现在总结一下遇到的坑. 扫码体验. 项目地址.https://github.com/c ...
- java 2类与对象[学堂在线]
java的面向对象方法和特征(略) 累的声明格式 语法:先定义一个引用变量名 穿件对象 new aclock=new CLock() 没有ststaic 就是实例变量 类变量static 类变量 方法 ...
- VisualTreeHelper使用——使用BFS实现高效率的视觉对象搜索
BFS,即广度优先搜索,是一种典型的图论算法.BFS算法与DFS(深度优先搜索)算法相对应,都是寻找图论中寻路的常用算法,两者的实现各有优点. 其中DFS算法常用递归实现,也就是常见的一条路找到黑再找 ...
- PyCharm2019 永久激活
<!-- 2019激活码 2019-06-21新更新 --> D00F1BDTGF-eyJsaWNlbnNlSWQiOiJEMDBGMUJEVEdGIiwibGljZW5zZWVOYW1l ...
- Spark day03
补充算子 transformations mapPartitionWithIndex 类似于mapPartitions,除此之外还会携带分区的索引值. repartition 增加或减少分区.会产生s ...
- QT_OPENGL-------- 1. WINDOW
opengl学习第一步,首先来实现一个显示窗口. 1.首先要下载配置glfw,我在前面的文章中也提到过,具体作用可以另行百度.配置出现无法引用可参考ubuntu 使用glfw.h 出现函数无法调用. ...
- NDK(1)简介
AndroidNDK Android NDK 是在SDK前面又加上了“原生”二字,即Native Development Kit,因此又被Google称为“NDK”. Android程序运行在Dalv ...
- MUI - 引导页制作
引导页制作 本文的引导页和[官方的引导页示例](https://github.com/dcloudio/mui/blob/master/examples/hello-mui/examples/guid ...
- Java中清空session的方法
session.removeAttribute("sessionname")是清除SESSION里的某个属性. session.invalidate()是让SESSION失效. 或 ...