Generalized end-to-end loss for speaker verification
论文题目:2018_说话人验证的广义端到端损失
论文代码:https://google.github.io/speaker-id/publications/GE2E/
地址:https://www.cnblogs.com/LXP-Never/p/11799985.html
作者:凌逆战
摘要
在本论文中,我们提出了一种新的损失函数,称为广义端到端( generalized end-to-end,GE2E)损失,使得说话人验证模型的训练比以往基于元组的端到端(tuple based end to end,TE2E)损失函数更加有效,与TE2E不同,GE2E损失函数以强调实例的方式更新网络,这些实例在训练过程的每个步骤中都难以验证。此外,GE2E损失不需要选择示例的初始阶段。利用这些特性,我们的新损失函数模型使说话人验证EER降低了10%以上,同时使训练时间减少了60%。从而学习出一个更好的模型。我们还介绍了MultiReader技术,它允许我们进行域自适应训练一个更精确的模型,该模型支持多个关键字(即OK Google和Hey Google)以及多个方言。
索引词:Speaker verification, end-to end,MultiReader,key word detection
1 引言
1.1 背景
说话者验证(SV)是使用语音匹配[1、2]等应用程序根据说话者的已知语音(即注册说话)验证说话是否属于特定说话者的过程。
根据用于注册和验证的话语限制,说话人验证模型通常分为两类:与文本相关的说话人验证(TD-SV)和文本无关的说话人验证(TI-SV)。在TD-SV中,注册和验证话语的转录本都受到语音的限制,而在TI-SV中,在注册或验证话语的转录本上没有词汇限制,暴露音素和话语持续时间的较大变化[3, 4 ]。在这项工作中,我们主要关注TI-SV和TD-SV的一个子任务,称为global password TD-SV,其中验证是基于检测到的关键字,例如OK、Google[5,6]
在以往的研究中,基于i-向量的系统一直是TD-SV和TI-SV应用[7]的主要方法。近年来,更多的努力集中在使用神经网络进行说话人验证,而最成功的系统是使用端到端训练[8,9,10,11,12]。在这样的系统中,神经网络输出向量通常被称为嵌入向量(也称为d-向量)。与i-vector的情况类似,这种嵌入可以用于表示固定维空间中的话语,在固定维空间中,可以使用其他通常更简单的方法来消除说话者之间的歧义。
1.2 Tuple-Based端到端损失
在前面的工作[13]中,我们提出了基于元组的端到端(TE2E)模型,该模型模拟了训练过程中运行时注册和验证的两阶段过程。在我们的实验中,TE2E模型与LSTM[14]结合达到了当时最好的性能。在每个训练步骤中,一个评估话语$x_{j~}$和$M$个注册话语$x_km$(其中$m=1,...,M$)的元组fed进了我们的LSTM网络:${x_{j~},(x_{k1},...,x_{kM})}$,其中$x$代表一个定长语音段的特征(对数mel滤波器组能量),$j$和$k$代表说出话术的人,$j$可能等于也可能不等于$k$,元组包括来自说话人$j$的单个话语和来自说话人$k$的$M$个不同的话语。如果$x_{j~}$和$M$注册语句来自同一个说话人,我们称之为元组正,即$j=k$,否则称之为负。我们交替生成正元组和负元组。
对于每个输入元组,我们计算LSTM的L2归一化响应:${e_{j~}, (e_{k1},...,e_{kM})}$。这里每个e是一个固定维度的嵌入向量,它是由LSTM定义的序列到向量的映射产生的。元组的质心$(e_{k1},...,e_{kM})$表示由M个话语构建的声纹,定义如下:
$$公式1:c_k=E_m[e_{km}]=\frac{1}{M}\sum_{m=1}^Me_{km}$$
相似度由余弦相似度函数定义:
$$公式2:s=w*cos(e_{j~},c_k)+b$$
其中$w$和$b$是可训练参数,TE2E损失最终定义为:
$$公式3:L_T(e_{j~},c_k)=\delta (j,k)\sigma (s)+(1-\delta (j,k))(1-\sigma (s))$$
这里$\sigma (x)=\frac{1}{(1+e^{-x})}$是标准的sigmoid函数,如果$j=k$那么$\delta (j,k)=1$,否则等于0。当$k=j$时,TE2E的损失函数激励s值更大。当$k\neq j$时$s$值更小。考虑到正元组和负元组的更新,这个损失函数与FaceNet中的三重损失非常相似[15]。
1.3 综述
在本文中,我们介绍了我们的TE2E体系结构的一个推广。这种新的体系结构以一种更有效的方式从不同长度的输入序列构建元组,显著提高了TD-SV和TI-SV的性能和训练速度。本文组织如下:在第2.1节中给出了GE2E损失函数的定义;第2.2节是GE2E更有效更新模型参数的理论依据;第2.3节介绍了一种称为“MultiReader”的技术,它使我们能够训练支持多种关键词和语言的模型;最后,我们在第3节中给出了我们的实验结果。
2 广义的端到端模型
广义端到端(GE2E)训练是基于一次性处理大量的话语,以包含N个说话者的batch的形式,平均每个说话者发出M个话语,如图1所示。
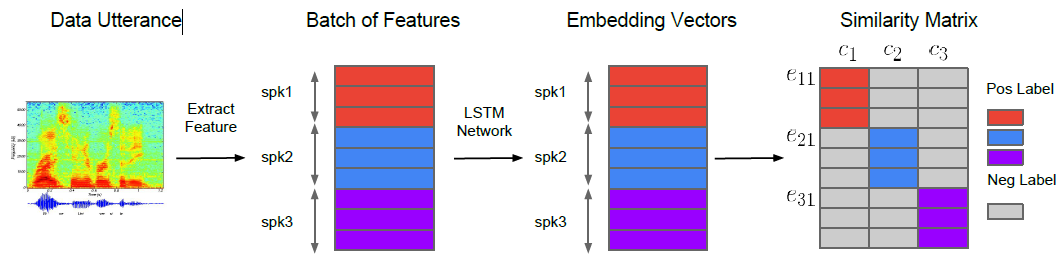
图1所示。系统概述。不同的颜色表示不同说话者的话语/embeddings(嵌入)。
2.1 训练模型
我们用N*M个语句来构建一个batch。这些话语来自N个不同的speaker,每个speaker有M个话语。每个特征向量$x_{ji}$($1\leq j\leq N$和$1\leq i\leq M$)表示从说话人$j$话语$i$中提取的特征。
与我们之前的工作[13]类似,我们把每一个话语$x_{ji}$提取的特征输入到LSTM网络中。线形层作为LSTM层的最后一层,用作数据的变维(把数据转换成语音帧)。我们将整个神经网络的输出表示为$f(x_{ji};w)$,其中$w$代表所有神经网络的参数(包括LSTM层和线性层)。嵌入向量(d-vector)定义为网络输出的L2 归一化(normalization):
$$公式4:e_{ji}=\frac{f(x_{ji};w)}{||f(x_{ji};w)||_2}$$
其中$e_{ji}$表示第$j$个说话者第$i$个话语的 embedding(嵌入) 向量。第j个说话者的嵌入向量的质心$[e_{j1},...,e_{jm}]$通过公式1被定义为$c_j$。
相似矩阵$S_{ji,k}$定义为每个嵌入向量$e_{ji}$与所有质心$c_k(1\leq j,k\leq N和1\leq i \leq M$之间的缩放余弦相似性:
$$公式5:S_{ji,k}=w*cos(e_{ji},c_k)+b$$
其中$w$和$b$是可学习:参数,我们将权重约束为正$w>0$,因为当余弦相似度较大时,我们希望相似度较大。TE2E和GE2E的主要区别如下:
- TE2E的相似度(公式2)是一个标量值,它定义嵌入向量$e_{j~}$和单个元组质心centroid $c_k$之间的相似度。
- GE2E建立了一个相似度矩阵(公式5),定义了每个$e_{ji}$和所有质心centroid $c_k$之间的相似度。
图1展示了整个过程,包括来自不同说话人的特征、嵌入向量和相似度评分,用不同的颜色表示。
在训练中,我们希望每个话语的embedding(嵌入)与所有说话者的centroid(形心)相似,同时远离其他说话者的centroid。如图1中的相似矩阵所示,我们希望彩色区域的相似值较大,而灰色区域的相似值较小。图2以另一种方式说明了相同的概念:我们希望蓝色嵌入向量靠近它自己的speaker的形心(蓝色三角形),远离其他的形心(红色和紫色三角形),特别是最近的那个(红色三角形)。给定一个嵌入向量$e_{ji}$,所有的centroids(质心)$c_k$,以及相应的相似矩阵$S_{ji,k}$,有两种方法来实现这个概念:
softmax 我们在$S_{ji,k}$上设置一个softmax,其中$k=1,...,N$,如果$k=j$使输出等于1,否则使输出等于0。因此,每个嵌入向量$e_{ji}$上的损失可以定义为:
$$公式6:L(e_{ji})=S_{ji,j}-\log \sum_{k=1}^Nexp(S_{ji,k})$$
这个损失函数意味着我们将每个嵌入向量推到其形心附近,并将其从所有其他形心拉出
Contrast 对比度损失的定义是阳性(positive)对和最积极的阴性(negative)对,如:
$$公式7:\max\limits_{\substack{1\leq k\leq N \\k\neq j}}\sigma (S_{ji,k}})$$
其中$\sigma (x)=\frac{1}{1+e^{-x}}$是sigmoid函数。对于每一个话语,损失中正好增加了两个部分:
(1)一个正分量,它与嵌入向量和它的真说话人声纹(形心)之间的正匹配相关。
(2)一个硬 nagative(负)分量,它与嵌入向量和声纹(形心)之间的负匹配有关,在所有假说话者中相似性最高。
在图2中,正项对应于将$e_{ji}$(蓝色圆)推向$c_j$(蓝色三角形)。负项对应于将$e_ji$(蓝色圆圈)从$c_k$(红色三角形)中拉出来,因为$c_k$与$c_{k`}$相比更类似于$e_{ji}$。因此,对比度损失使我们能够集中于嵌入向量和负质心对。
在我们的实验中,我们发现GE2E损失的两种实现都是有用的:contrast 损失在TD-SV中表现更好,而softmax 损失在TI-SV中表现稍好。
此外,我们还观察到,在计算真正说话者的质心时去掉$e_{ji}$可以使训练变得稳定,并有助于避免繁琐的解决方案。因此,虽然我们在计算负相似性$(i.e.,k\neq j)$时仍然使用方程式1,但当$k=j$时,我们使用方程式8:
$$公式8:c_j^{-i}=\frac{1}{M-1}\sum_{m=1\\m\neq i}^Me_{jm}$$
$$公式9:S_{ji,k}=\left\{\begin{matrix}
w*\cos (e_{ji,c_j^{-i}})+b&&k=j\\
w*\cos (e_{ji},c_k)+b&&otherwise
\end{matrix}\right.$$
结合方程式4、6、7和9,最终的GE2E损失$L_G$是相似矩阵上所有损失的总和$(1\leq j\leq N,1\leq i\leq M)$
$$公式10:L_G(x;w)=L_G(S)=\sum_{j,i}L(e_{ji})$$
2.2 TE2E与GE2E的比较
考虑GE2E中的单个batch loss更新:我们有N个说话人,每个说话人有M个话语。每一步更新都会将所有N*M的嵌入向量推向它们自己的中心,并将它们拉离其他中心。
这反映了TE2E损失函数[13]中每个$x_{ji}$的所有可能元组的情况。假设我们在比较说话者$j$时随机选择P个话语:
1、Positive 元组:对于$\{x_{ji},(x_{j,i_1},...,x_{j,i_p})\}$,其中$1\leq i_p\leq M$,$p=1,...,P$。有$\begin{pmatrix}M\\ P\end{pmatrix}$个这样的正元组。
2、Nagative 元组:$\{x_{ji},(x_{k,i_1},...,x_{k,i_p})\},k\neq j$和$1\leq i_p\leq M,p=1,...,P$。对于每一个$x_{ji}$,我们必须与其他所有的N-1给质心进行比较,其中每一组比较都包含$\begin{pmatrix}M\\ P\end{pmatrix}$个元组。
每个正元组与一个负元组进行平衡,因此总数是正元组和负元组的最大数目乘以2。因此,TE2E损失的元组总数为:
$$公式11:
2 \times \max \left(\left(\begin{array}{c}{M} \\{P}\end{array}\right),(N-1)\left(\begin{array}{c}{M} \\{P}\end{array}\right)\right) \geq 2(N-1)
$$
公式11的下界出现在$P=M$时。因此,GE2E中的每个$x_{ji}$更新至少与TE2E中的两个(N-1)步骤相同。上面的分析说明了为什么GE2E比TE2E更有效地更新模型,这与我们的经验观察一致:GE2E在更短的时间内收敛到更好的模型(详见第3节)。
2.3 训练MultiReader
考虑以下情况:我们关心小数据集$D_1$模型的应用。同时,我们有一个更大的数据集$D_2$在一个类似的,但不是相同的领域。我们想要在$D_2$的帮助下,训练一个在$D_1$数据集上表现良好的模型:
$$公式12:
L\left(D_{1}, D_{2} ; \mathbf{w}\right)=\mathbb{E}_{x \in D_{1}}[L(\mathbf{x} ; \mathbf{w})]+\alpha \mathbb{E}_{x \in D_{2}}[L(\mathbf{x} ; \mathbf{w})]
$$
这类似于正则化技术:在正规正则化中,我们使用$\alpha||w||_2^2$对模型进行正则化。但在这里,我们使用$E_{x\in D_2}[L(x;w)]$进行正则化。当数据集$D_1$没有足够的数据时,在$D_1$上训练网络会导致过度拟合。要求网络在$D_2$上也表现得相当好有助于使网络正规化。
这可以概括为组合K个不同的、可能极不平衡的数据源:$D_1,...,D_K$。我们给每个数据源分配一个权重$\alpha_k$,表示该数据源的重要性。在训练过程中,在每个步骤中,我们从每个数据源中提取一batch(批)/一tuple(组)话语,并计算联合损失:$L(D_1,...,D_K)=\sum_{k=1}^K\alpha_kE_{x_k\in D_k}[L(x_k;w)]$,其中每个$L(x_k;w)$是等式10中定义的损失。
3 实验
在我们的实验中,特征提取过程与[6]相同。首先将音频信号转换为宽为25ms,步长为10ms的帧。然后我们提取40维的log-mel-filterbank能量作为每个帧的特征。对于TD-SV应用程序,关键字检测和说话人验证都使用相同的功能。关键字检测系统只会将包含关键字的帧传递给说话者验证系统。这些帧构成一个固定长度(通常为800ms)的段。对于TI-SV应用,我们通常在语音活动检测(VAD)后提取随机定长片段,并使用滑动窗口方法进行推理(在第3.2节中讨论)。
我们的产品系统使用带有projection[16]的三层LSTM。嵌入向量(d-向量)大小与LSTM projection(投影)大小相同。对于TD-SV,我们使用了128个隐藏节点,投影大小为64。对于TI-SV,我们使用了768个隐藏节点,投影大小为256。当训练GE2E模型时,每批包含N = 64个说话者,M = 10个说话者。我们使用初始学习率0.01用SGD训练网络,每30M步减少一半。将梯度的l2范数裁剪为3[17],将LSTM中投影节点的梯度比例尺设置为0.5。关于比例因子$(w,b)$在损失函数中,我们还观察到一个好的初值是$(w,b) = (10,-5)$,较小的梯度scale 0.01有助于平滑收敛。
3.1 文本依赖说话人验证
虽然现有的语音助手通常只支持一个关键字,但研究表明,用户更希望同时支持多个关键字。对于谷歌Home的多用户,同时支持两个关键字:OK谷歌和Hey谷歌。
启用多个关键字的说话人验证介于TD-SV和TI-SV之间,因为文本既不受单个短语的约束,也不完全不受约束。我们使用MultiReader技术解决了这个问题(第2.3节)。与更简单的方法(如直接混合多个数据源)相比,MultiReader有很大的优势,它可以处理不同数据源大小不平衡的情况。在我们的案例中,我们有两个用于数量的数据源:1)一个来自匿名用户查询的“OK Google”数据集,其中约有150M条语音和约630K个说话人;2)一个混合的“OK/Hey Google”数据集,其中约有1.2M条语音和约1800个说话人。第一个数据集比第二个数据集大125倍的话语数和35倍的说话人数。
为了评估,我们报告了四种情况的等错误率(EER):用任一关键字注册,并验证任一关键字。所有的评价数据集都是从665个说话者中手动收集的,平均每个说话者有4.5个登记话语和10个评价话语。结果如表1所示。正如我们所看到的,MultiReader在所有四种情况下都带来了大约30%的相对改进。
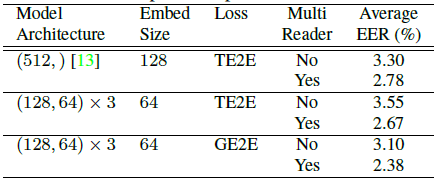
我们还对一个更大的数据集进行了更全面的评估,该数据集来自约83K个不同的说话人和环境条件,包括匿名日志和手动收集。我们平均每个说话者使用7.3注册话语和5个评价话语。表2总结了使用和不使用MultiReader设置训练的不同损失函数的平均能效比。基线模型是具有512个节点和128个嵌入向量大小的单层LSTM[13]。第二和第三行模型架构是三层LSTM。比较第2行和第3行,我们发现GE2E比TE2E好10%左右。与表1类似,这里我们还看到,使用MultiReader时,该模型的性能明显更好。虽然没有显示在表中,但也值得注意的是,GE2E模型的训练时间比TE2E少了约60%。
表1:MultiReader vs directly mixing multiple data sources
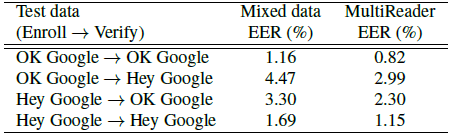
表2:文本依赖的说话人验证EER
3.2 文本独立说话人验证
在TI-SV训练中,我们将训练话语分成更小的片段,我们称之为部分话语。虽然我们不要求所有的部分话语都具有相同的长度,但同一batch的所有部分话语必须具有相同的长度。因此,对于每一批数据,我们在$[lb;ub]=[140;180]$帧内随机选择一个时间长度t,并强制该批中的所有部分语句都是长度t(如图3所示)。
在推理过程中,我们对每一个话语应用一个固定大小的滑动窗口$(lb+ub)/2=160$帧,50%重叠。我们计算每个窗口的d-vector。最后一个与话语相关的d向量是通过L2规范化窗口相关的d向量,然后取元素相关的平均值(如图4所示)生成的。
我们的TI-SV模型是对来自18K个说话人的大约36M个话语进行训练的,这些话语是从匿名日志中提取的。为了评估,我们使用了另外1000个演讲者,平均每个演讲者有6.3条注册话语和7.2条评估话语。表3显示了不同训练损失函数之间的性能比较。第一列是softmax,它预测训练数据中所有扬声器的扬声器标签。第二列是用TE2E损失训练的模型。第三列是用GE2E损失训练的模型。如表所示,GE2E的性能优于softmax和TE2E,EER性能改善大于10%。此外,我们还观察到,GE2E训练比其他损失函数快约3倍。
表3:文本无关的说话人验证EER(%)

4 总结
在本文中,我们提出了广义端到端(GE2E)损失函数来更有效地训练说话人验证模型。理论和实验结果都验证了该损失函数的优越性。我们还引入了MultiReader技术来组合不同的数据源,使我们的模型能够支持多个关键字和多种语言。通过结合这两种技术,我们得到了更精确的说话人验证模型。
5 参考文献
[1] Yury Pinsky, “Tomato, tomahto.google home now supports multiple users,”https://www.blog.google/products/assistant/tomato-tomahtogoogle-home-now-supports-multiple-users, 2017.
[2] Mihai Matei, “Voice match will allow google home to recognize your voice,”https://www.androidheadlines.com/2017/10/voice-matchwill-allow-google-home-to-recognize-your-voice.html, 2017.
[3] Tomi Kinnunen and Haizhou Li, “An overview of textindependent speaker recognition: From features to supervectors,” Speech communication, vol. 52, no. 1, pp. 12–40, 2010.
[4] Fr´ed´eric Bimbot, Jean-Franc¸ois Bonastre, Corinne Fredouille,Guillaume Gravier, Ivan Magrin-Chagnolleau, Sylvain Meignier, Teva Merlin, Javier Ortega-Garc´ıa, Dijana Petrovska-Delacr´etaz, and Douglas A Reynolds, “A tutorial on text-independent speaker verification,” EURASIP journal on applied signal processing, vol. 2004, pp. 430–451, 2004.
[5] Guoguo Chen, Carolina Parada, and Georg Heigold, “Smallfootprint keyword spotting using deep neural networks,” in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014, pp. 4087–4091.
[6] Rohit Prabhavalkar, Raziel Alvarez, Carolina Parada, Preetum Nakkiran, and Tara N Sainath, “Automatic gain control and multi-style training for robust small-footprint keyword spotting with deep neural networks,” in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on.IEEE, 2015, pp. 4704–4708.
[7] Najim Dehak, Patrick J Kenny, R´eda Dehak, Pierre Dumouchel, and Pierre Ouellet, “Front-end factor analysis for speaker verification,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788–798, 2011.
[8] Ehsan Variani, Xin Lei, Erik McDermott, Ignacio Lopez Moreno, and Javier Gonzalez-Dominguez, “Deep neural networks for small footprint text-dependent speaker verification,” in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014, pp. 4052–4056.
[9] Yu-hsin Chen, Ignacio Lopez-Moreno, Tara N Sainath, Mirk´o Visontai, Raziel Alvarez, and Carolina Parada, “Locallyconnected and convolutional neural networks for small footprint speaker recognition,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
[10] Chao Li, Xiaokong Ma, Bing Jiang, Xiangang Li, Xuewei Zhang, Xiao Liu, Ying Cao, Ajay Kannan, and Zhenyao Zhu,“Deep speaker: an end-to-end neural speaker embedding system,” CoRR, vol. abs/1705.02304, 2017.
[11] Shi-Xiong Zhang, Zhuo Chen, Yong Zhao, Jinyu Li, and Yifan Gong, “End-to-end attention based text-dependent speaker verification,” CoRR, vol. abs/1701.00562, 2017.
[12] Seyed Omid Sadjadi, Sriram Ganapathy, and Jason W. Pelecanos,“The IBM 2016 speaker recognition system,” CoRR,vol. abs/1602.07291, 2016.
[13] Georg Heigold, Ignacio Moreno, Samy Bengio, and Noam Shazeer, “End-to-end text-dependent speaker verification,”in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on. IEEE, 2016, pp. 5115–5119.
[14] Sepp Hochreiter and J¨urgen Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780,1997.
[15] Florian Schroff, Dmitry Kalenichenko, and James Philbin,“Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 815–823.
[16] Has¸im Sak, Andrew Senior, and Franc¸oise Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling,” in Fifteenth Annual Conference of the International Speech Communication Association, 2014.
[17] Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio, “Understanding the exploding gradient problem,” CoRR, vol.abs/1211.5063, 2012.
Generalized end-to-end loss for speaker verification的更多相关文章
- Large Margin Softmax Loss for Speaker Verification
[INTERSPEECH 2019接收] 链接:https://arxiv.org/pdf/1904.03479.pdf 这篇文章在会议的speaker session中.本文主要讨论了说话人验证中的 ...
- 自然语言处理领域重要论文&资源全索引
自然语言处理(NLP)是人工智能研究中极具挑战的一个分支.随着深度学习等技术的引入,NLP领域正在以前所未有的速度向前发展.但对于初学者来说,这一领域目前有哪些研究和资源是必读的?最近,Kyubyon ...
- [转]NLP Tasks
Natural Language Processing Tasks and Selected References I've been working on several natural langu ...
- JabRef 文献管理软件
JabRef 文献管理软件简明教程 大多只有使用LaTeX撰写科技论文的研究人员才能完全领略到JabRef的妙不可言,但随着对Word写作平台上BibTeX4Word插件的开发和便利应用,使用Word ...
- TensorFlow 中文资源全集,官方网站,安装教程,入门教程,实战项目,学习路径。
Awesome-TensorFlow-Chinese TensorFlow 中文资源全集,学习路径推荐: 官方网站,初步了解. 安装教程,安装之后跑起来. 入门教程,简单的模型学习和运行. 实战项目, ...
- [转]awesome-tensorflow-chinese
模型项目 Domain Transfer Network - Implementation of Unsupervised Cross-Domain Image Generation Show, At ...
- Awesome TensorFlow
Awesome TensorFlow A curated list of awesome TensorFlow experiments, libraries, and projects. Inspi ...
- 微软牛津计划——声纹识别与视频识别API上线啦!
上个月,我们发布了牛津计划机器学习的情感识别API,能够帮助不同平台的开发者轻松添加智能应用,而无需精通人工智能领域.牛津计划仅仅是微软在人工智能领域探索中的一个实例,而我们的期望是实现更加注重个人使 ...
- OpenCL学习笔记(三):OpenCL安装,编程简介与helloworld
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. OpenCL安装 安装我不打算 ...
随机推荐
- Java框架之MyBatis 07-动态SQL-缓存机制-逆向工程-分页插件
MyBatis 今天大年初一,你在学习!不学习做什么,斗地主...人都凑不齐.学习吧,学习使我快乐!除了诗和远方还有责任,我也想担当,我也想负责,可臣妾做不到啊,怎么办?你说怎么办,为啥人家能做到你做 ...
- 【python系统学习08】for循环知识点合集
for循环 for简介 [循环]:就是依照某些我们编写的特定规则,重复的做一件事. 当你需要重复的"搬砖"的时候,可以用for循环进行遍历,让机器循环的帮你去"搬砖&qu ...
- kuangbin专题专题十一 网络流 POJ 1087 A Plug for UNIX
题目链接:https://vjudge.net/problem/POJ-1087 题目:有n个插座,插座上只有一个插孔,有m个用电器,每个用电器都有插头,它们的插头可以一样, 有k个插孔转化器, a ...
- linux系统iot平台编程阶段总结
1.inline内联函数 在C语言中,如果一些函数被频繁调用,不断地有函数入栈,即函数栈,会造成栈空间或栈内存的大量消耗. 为了解决这个问题,特别的引入了inline修饰符,表示为内联函数. 在使用循 ...
- Realm及相关对象(四)
Shiro Realm 1.UserRealm 父类 AuthorizingRealm 将获取 Subject 相关信息分成两步:获取身份验证信息(doGetAuthenticationInfo)及授 ...
- laravel路由与控制器(资源路由restful)
目前我们大致了解了laravel下,在开始一个Http程序需要先定义路由.之前的例子中,我们的业务逻辑都是在路由里实现,这对于简单的网站或web应用没什么问题,当我们需要扩大规模,程序变得复杂,分层的 ...
- 从头学pytorch(二十二):全连接网络dense net
DenseNet 论文传送门,这篇论文是CVPR 2017的最佳论文. resnet一文里说了,resnet是具有里程碑意义的.densenet就是受resnet的启发提出的模型. resnet中是把 ...
- 如何更改cmd 编码为UTF-8
如何将cmd编码改为UTF—8 如图输入chcp 65001即可更改 改完之后是这样的 更改回GBK 输入 CHCP 936即可
- Percona-XtraDB-Cluster-57 安装操作记录
一.PXC集群的一些特性 Percona官网服务器位于境外,访问很困难.本次安装使用的是其官网提供的最新版本5.7.23-31.31.1.el7,当前日期为2018.10.10. PXC集群中,存储引 ...
- 【译】SQ3R学习法则
SQ3R 观察-提问-阅读-复述-回顾 背景 SQ3R是一种理解策略,可帮助学生在阅读时思考他们正在阅读的文章. SQ3R通常被归类为学习策略,通过教导学生在初次阅读一篇文章时如何阅读和像高效读者一样 ...