Spark学习之路 (二十三)SparkStreaming的官方文档[转]
SparkCore、SparkSQL和SparkStreaming的类似之处

SparkStreaming的运行流程
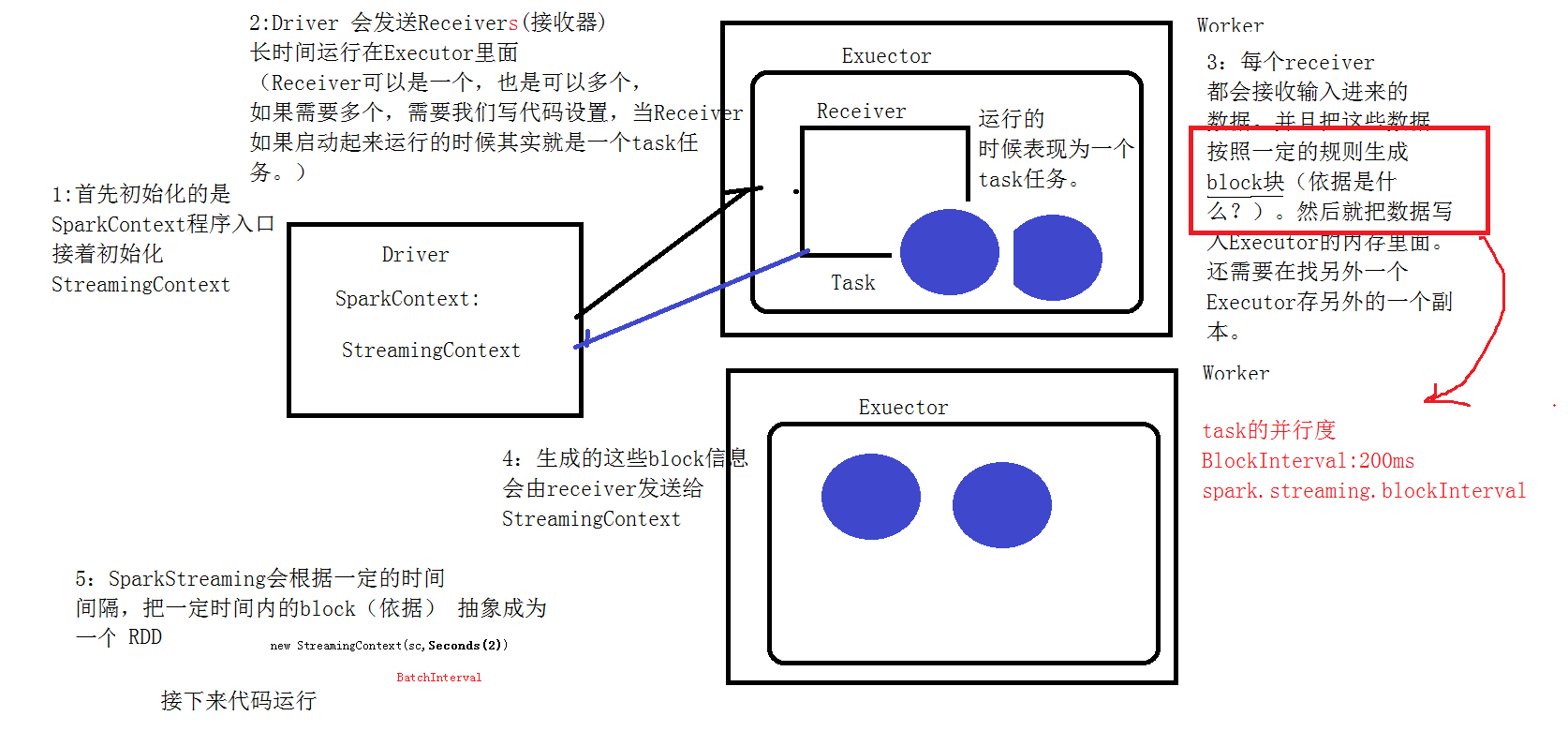
1、我们在集群中的其中一台机器上提交我们的Application Jar,然后就会产生一个Application,开启一个Driver,然后初始化SparkStreaming的程序入口StreamingContext;
2、Master会为这个Application的运行分配资源,在集群中的一台或者多台Worker上面开启Excuter,executer会向Driver注册;
3、Driver服务器会发送多个receiver给开启的excuter,(receiver是一个接收器,是用来接收消息的,在excuter里面运行的时候,其实就相当于一个task任务)
4、receiver接收到数据后,每隔200ms就生成一个block块,就是一个rdd的分区,然后这些block块就存储在executer里面,block块的存储级别是Memory_And_Disk_2;
5、receiver产生了这些block块后会把这些block块的信息发送给StreamingContext;
6、StreamingContext接收到这些数据后,会根据一定的规则将这些产生的block块定义成一个rdd;
SparkStreaming的3个组成部分
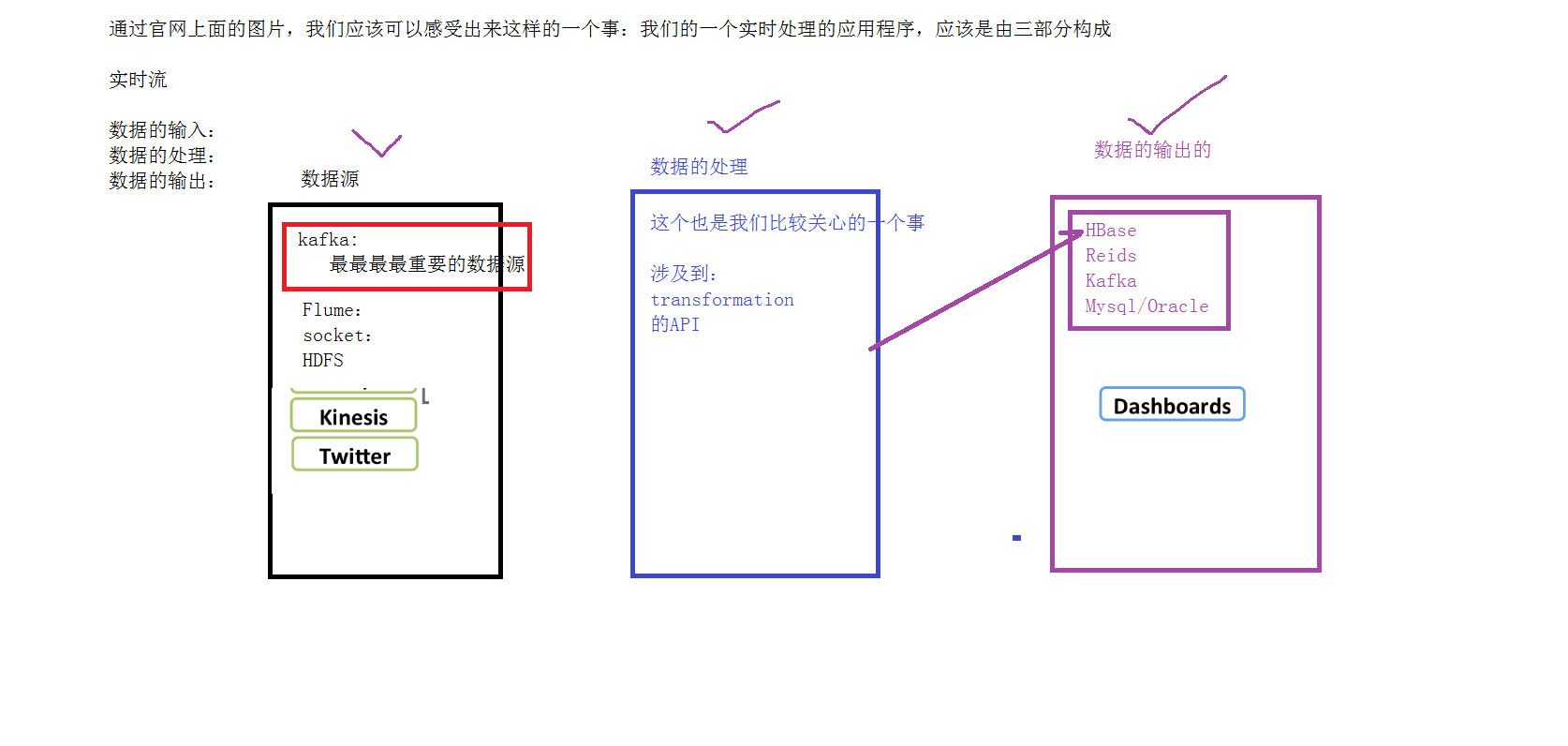
离散流(DStream)

例子
简单的单词计数
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object NetWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
val sparkContext = new SparkContext(conf)
val sc = new StreamingContext(sparkContext,Seconds(2))
/**
* 数据的输入
* */
val inDStream: ReceiverInputDStream[String] = sc.socketTextStream("bigdata",9999)
inDStream.print()
/**
* 数据的处理
* */
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
/**
* 数据的输出
* */
resultDStream.print()
/**
*启动应用程序
* */
sc.start()
sc.awaitTermination()
sc.stop()
}
}在Linux上执行以下命令

运行结果

监控HDFS上的一个目录
HDFS上的目录需要先创建
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object HDFSWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName)
val sc = new StreamingContext(conf,Seconds(2))
val inDStream: DStream[String] = sc.textFileStream("hdfs://hadoop1:9000/streaming")
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
resultDStream.print()
sc.start()
sc.awaitTermination()
sc.stop()
}
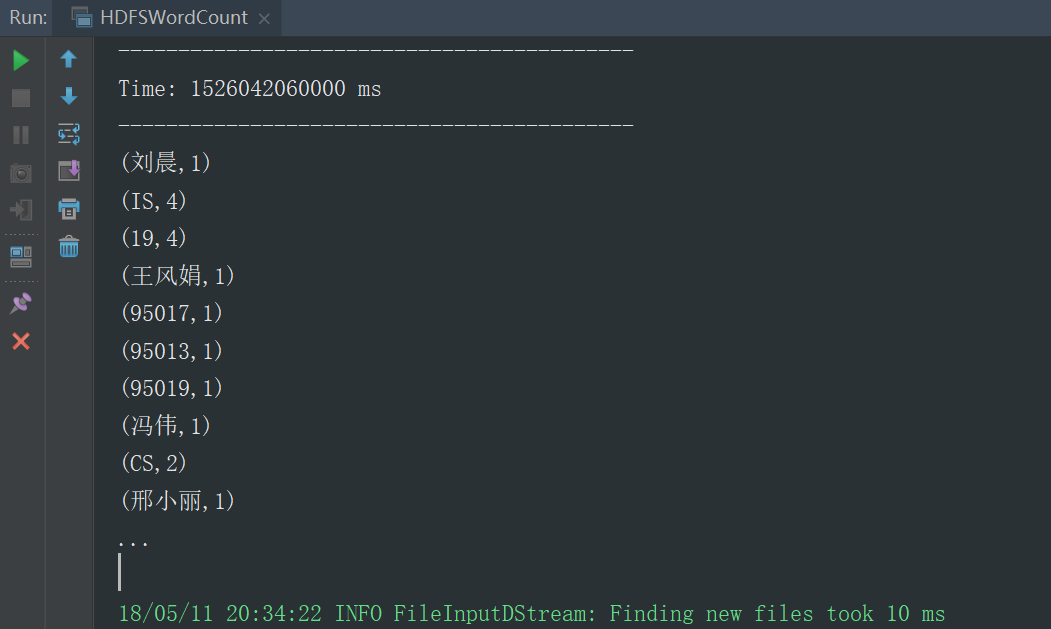
}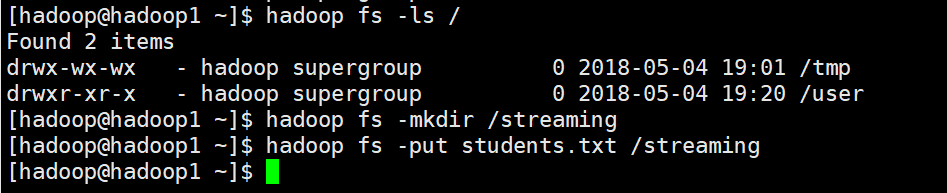
student.txt
95002,刘晨,女,19,IS
95017,王风娟,女,18,IS
95018,王一,女,19,IS
95013,冯伟,男,21,CS
95014,王小丽,女,19,CS
95019,邢小丽,女,19,IS运行结果,默认展示的10条
第二次运行的时候更新原先的结果
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object UpdateWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
System.setProperty("HADOOP_USER_NAME","hadoop")
val sparkContext = new SparkContext(conf)
val sc = new StreamingContext(sparkContext,Seconds(2))
sc.checkpoint("hdfs://hadoop1:9000/streaming")
val inDStream: ReceiverInputDStream[String] = sc.socketTextStream("hadoop1",9999)
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(","))
.map((_, 1))
.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
val currentCount: Int = values.sum
val lastCount: Int = state.getOrElse(0)
Some(currentCount + lastCount)
})
resultDStream.print()
sc.start()
sc.awaitTermination()
sc.stop()
}
}Linux运行命令
运行结果

DriverHA
5.3的代码一直运行,结果可以一直累加,但是代码一旦停止运行,再次运行时,结果会不会接着上一次进行计算,上一次的计算结果丢失了,主要原因上每次程序运行都会初始化一个程序入口,而2次运行的程序入口不是同一个入口,所以会导致第一次计算的结果丢失,第一次的运算结果状态保存在Driver里面,所以我们如果想用上一次的计算结果,我们需要将上一次的Driver里面的运行结果状态取出来,而5.3里面的代码有一个checkpoint方法,它会把上一次Driver里面的运算结果状态保存在checkpoint的目录里面,我们在第二次启动程序时,从checkpoint里面取出上一次的运行结果状态,把这次的Driver状态恢复成和上一次Driver一样的状态
Spark学习之路 (二十三)SparkStreaming的官方文档[转]的更多相关文章
- Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.简介 1.1 概述 Spark Streamin ...
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark(十四)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路(十三)—— Spark Streaming 与流处理
一.流处理 1.1 静态数据处理 在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中.应用程序根据需要查询数据或计算数据.这就是传统的静态数据处理架构.Hadoop采用HDFS进行数据 ...
- Spark学习之路 (十三)SparkCore的调优之资源调优JVM的基本架构
一.JVM的结构图 1.1 Java内存结构 JVM内存结构主要有三大块:堆内存.方法区和栈. 堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间.From Su ...
- 嵌入式Linux驱动学习之路(二十三)NAND FLASH驱动程序
NAND FLASH是一个存储芯片. 在芯片上的DATA0-DATA7上既能传输数据也能传输地址. 当ALE为高电平时传输的是地址. 当CLE为高电平时传输的是命令. 当ALE和CLE都为低电平时传输 ...
- IOS学习之路二十三(EGOImageLoading异步加载图片开源框架使用)
EGOImageLoading 是一个用的比较多的异步加载图片的第三方类库,简化开发过程,我们直接传入图片的url,这个类库就会自动帮我们异步加载和缓存工作:当从网上获取图片时,如果网速慢图片短时间内 ...
- 流媒体技术学习笔记之(六)FFmpeg官方文档先进音频编码(AAC)
先进音频编码(AAC)的后继格式到MP3,和以MPEG-4部分3(ISO / IEC 14496-3)被定义.它通常用于MP4容器格式; 对于音乐,通常使用.m4a扩展名.第二最常见的用途是在MKV( ...
- 看官方文档学习springcloud搭建
很多java的朋友学习新知识时候去百度,看了之后一知半解,不知道怎么操作,不知道到底什么什么东西,那么作为java码农到底该怎么学习额 一 百度是对还是错呢? 百度是一个万能的工具,当然是对也是错的 ...
随机推荐
- MingGW Posix VS Win32 - 明瓜娃的毒因
MinGW-posix和win32纠缠的瓜娃子 官方首席佛偈(SourceForge)的官网下载页 法克油啊,让我一个小白情何以堪. 盘TA wiki posix wiki中文-UNIX API标准 ...
- ionic2的返回按钮的编辑问题
ionic2 返回按钮 首先可以在 app.module.ts 文件中配置. @NgModule 中的 imports 属性的 IonicModule.forRoot 第二个参数,如下: IonicM ...
- Centos7更改屏幕显示率
第一种,在虚拟机中安装VMwareTools,之后在虚拟机菜单栏"查看"这一项选择立即适应窗口. 第二种,修改/boot/grub2/grub.cfg配置文件,在终端输入su,输入 ...
- Optional类包含的方法介绍及其示例
Optional类的介绍 javadoc中的介绍 这是一个可以为null的容器对象.如果值存在则isPresent()方法会返回true,调用get()方法会返回> 该对象. 使用场景 用于避免 ...
- scrapy的useragent与代理ip
scrapy中的useragent与代理ip 方法一: user-agent我们可以直接在settings.py中更改,如下图,这样修改比较简单,但是并不推荐,更推荐的方法是修改使用scrapy的中间 ...
- JMeter接口测试-循环读取库的用户信息
前言 如何实现循环读取数据库的用户信息,并传递到下一个登录请求呢,下面我们一起来学习吧!在之前我们已经学会了利用JMeter连接数据库了,具体操作可以看我之前的随笔JMeter接口测试-JDBC测试 ...
- 高灵敏度自带DSP降噪算法的audio codec解决方案
背景调研 随着AI渗透到各行各业,人们对语音的需求也越来越大,最近一两年,各种AI音频设备如雨后春笋般冒出.各种智能AI设备的推出,意味者市场对低成本的音频采集设备越来越多.针对这种情况,我们开发 ...
- Android中通过ImageSwitcher实现相册滑动查看照片功能(附代码下载)
场景 效果 注: 博客: https://blog.csdn.net/badao_liumang_qizhi关注公众号 霸道的程序猿 获取编程相关电子书.教程推送与免费下载. 实现 将需要滚动查看的照 ...
- 常量, char[], const char[], char*, const char*, char* const以及const char* const的详解
注意,这里用char类型只是举了一个例子,其他的int之类的也通用. 1: 常量: 例子: char str[] = "Hello world!"; char ch = 'a'; ...
- Charles老版本教程
链接:http://pan.baidu.com/s/1c16PxEo 刮开有奖->密码:dbml 初级篇: 1.1设置代理 1.2参数设置+界面介绍 1.3屏蔽多余数据 1.4请求重发 1.5 ...