Update(Stage5):Kudu入门_项目介绍_ CDH搭建
Kudu
什么是
Kudu操作
Kudu如何设计
Kudu的表
1. 什么是 Kudu
Kudu的应用场景是什么?Kudu在大数据平台中的位置在哪?Kudu用什么样的设计, 才能满足其设计目标?Kudu中有什么集群角色?
1.1. Kudu 的应用场景
- 现代大数据的应用场景
-
例如现在要做一个类似物联网的项目, 可能是对某个工厂的生产数据进行分析
- 项目特点
-
数据量大
有一个非常重大的挑战, 就是这些设备可能很多, 其所产生的事件记录可能也很大, 所以需要对设备进行数据收集和分析的话, 需要使用一些大数据的组件和功能
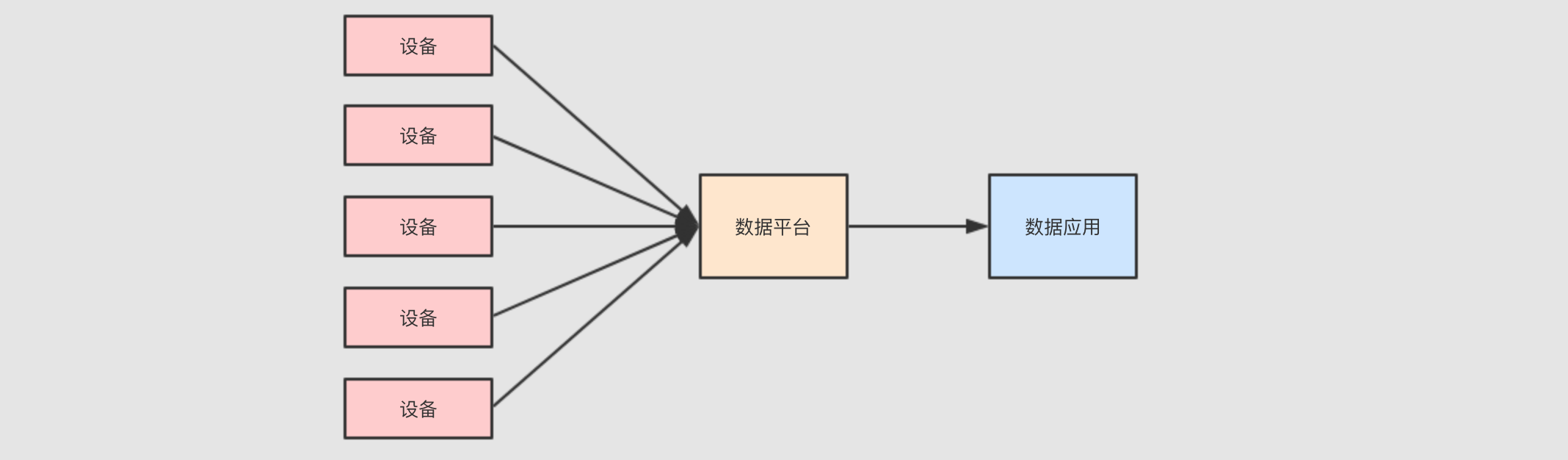
流式处理
因为数据是事件, 事件是一个一个来的, 并且如果快速查看结果的话, 必须使用流计算来处理这些数据
数据需要存储
最终需要对数据进行统计和分析, 所以数据要先有一个地方存, 后再通过可视化平台去分析和处理
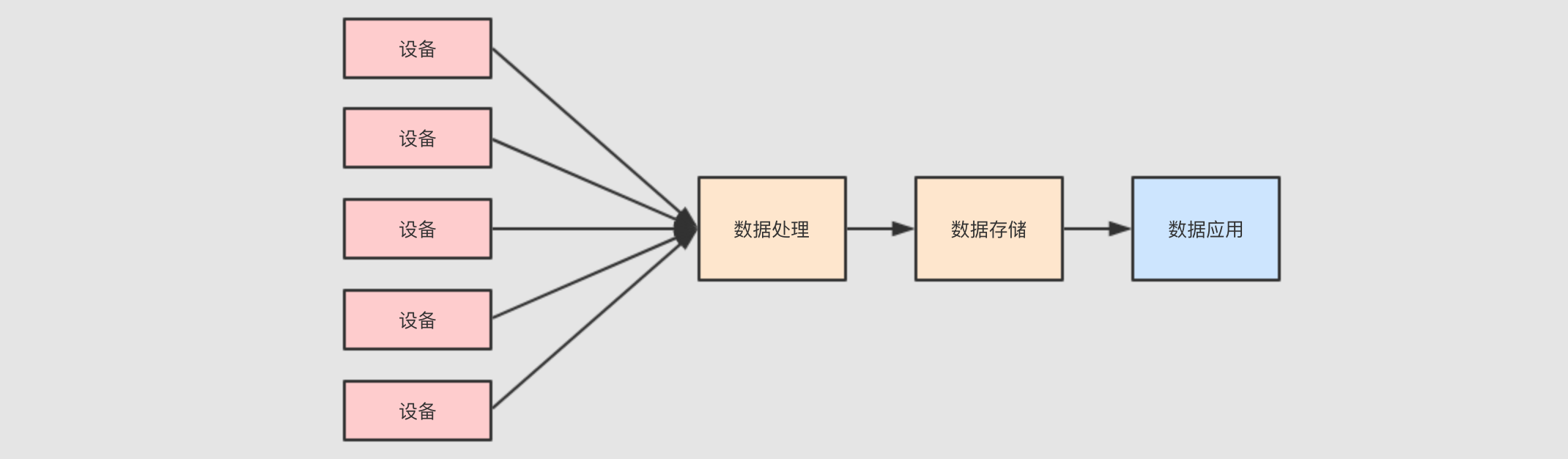
- 对存储层的要求
-
这样的一个流计算系统, 需要对数据进行什么样的处理呢?
要能够及时的看到最近的数据, 判断系统是否有异常
要能够扫描历史数据, 从而改进设备和流程
所以对数据存储层就有可能进行如下的操作
逐行插入, 因为数据是一行一行来的, 要想及时看到, 就需要来一行插入一行
低延迟随机读取, 如果想分析某台设备的信息, 就需要在数据集中随机读取某一个设备的事件记录
快速分析和扫描, 数据分析师需要快速的得到结论, 执行一行
SQL等上十天是不行的
- 方案一: 使用
Spark Streaming配合HDFS存储 -
总结一下需求
实时处理,
Spark Streaming大数据存储,
HDFS使用 Kafka 过渡数据

但是这样的方案有一个非常重大的问题, 就是速度机器之慢, 因为
HDFS不擅长存储小文件, 而通过流处理直接写入HDFS的话, 会产生非常大量的小文件, 扫描性能十分的差 - 方案二:
HDFS+compaction -
上面方案的问题是大量小文件的查询是非常低效的, 所以可以将这些小文件压缩合并起来

但是这样的处理方案也有很多问题
一个文件只有不再活跃时才能合并
不能将覆盖的结果放回原来的位置
所以一般在流式系统中进行小文件合并的话, 需要将数据放在一个新的目录中, 让
Hive/Impala指向新的位置, 再清理老的位置 - 方案三:
HBase+HDFS -
前面的方案都不够舒服, 主要原因是因为一直在强迫
HDFS做它并不擅长的事情, 对于实时的数据存储, 谁更适合呢?HBase好像更合适一些, 虽然HBase适合实时的低延迟的数据村醋, 但是对于历史的大规模数据的分析和扫描性能是比较差的, 所以还要结合HDFS和Parquet来做这件事
因为
HBase不擅长离线数据分析, 所以在一定的条件触发下, 需要将HBase中的数据写入HDFS中的Parquet文件中, 以便支持离线数据分析, 但是这种方案又会产生新的问题维护特别复杂, 因为需要在不同的存储间复制数据
难以进行统一的查询, 因为实时数据和离线数据不在同一个地方
这种方案, 也称之为
Lambda, 分为实时层和批处理层, 通过这些这么复杂的方案, 其实想做的就是一件事, 流式数据的存储和快速查询 - 方案四:
Kudu -
Kudu声称在扫描性能上, 媲美HDFS上的Parquet. 在随机读写性能上, 媲美HBase. 所以将存储存替换为Kudu, 理论上就能解决我们的问题了.
对于实时流式数据处理, Spark, Flink, Storm 等工具提供了计算上的支持, 但是它们都需要依赖外部的存储系统, 对存储系统的要求会比较高一些, 要满足如下的特点
支持逐行插入
支持更新
低延迟随机读取
快速分析和扫描
1.2. Kudu 和其它存储工具的对比
OLAP和OLTP行式存储和列式存储
Kudu和MySQL的区别Kudu和HBase的区别
OLAP和OLTP-
广义来讲, 数据库分为
OLTP和OLAP。数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。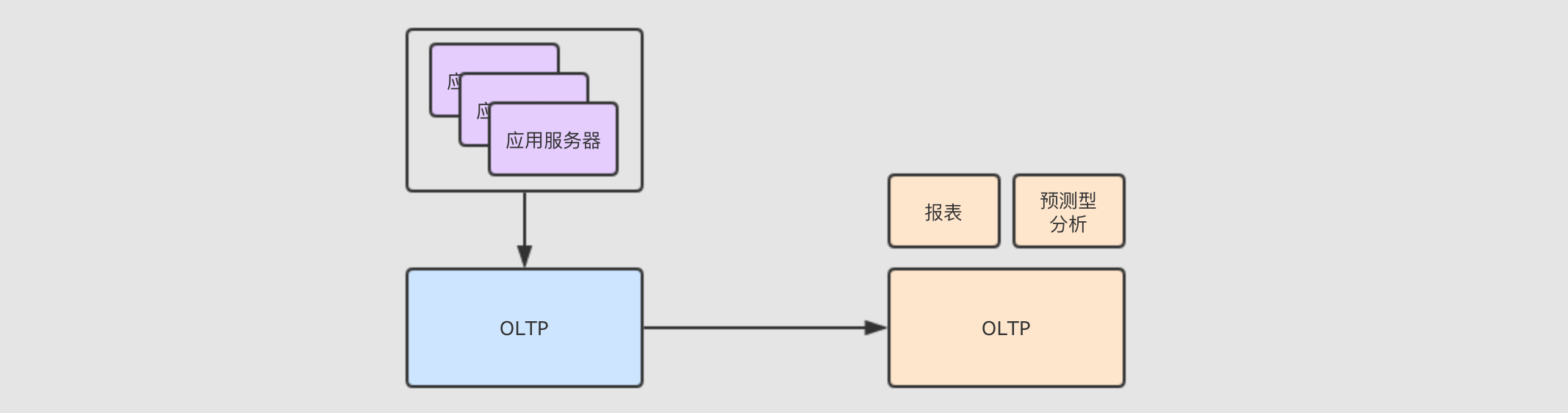
OLTP先举个栗子, 在电商网站中, 经常见到一个功能 - "我的订单", 这个功能再查询数据的时候, 是查询的某一个用户的数据, 并不是批量的数据
OLTP需要做的事情是快速插入和更新
精确查询
所以
OLTP并不需要对数据进行大规模的扫描和分析, 所以它的扫描性能并不好, 它主要是用于对响应速度和数据完整性很高的在线服务应用中OLAPOLAP和OLTP的场景不同,OLAP主要服务于分析型应用, 其一般是批量加载数据, 如果出错了, 重新查询即可总结
OLTP随机访问能力比较强, 批量扫描比较差OLAP擅长大规模批量数据加载, 对于随机访问的能力则比较差大数据系统中, 往往从
OLTP数据库中ETL放入OLAP数据库中, 然后做分析和处理
- 行式存储和列式存储
-
行式和列式是不同的存储方式, 其大致如下
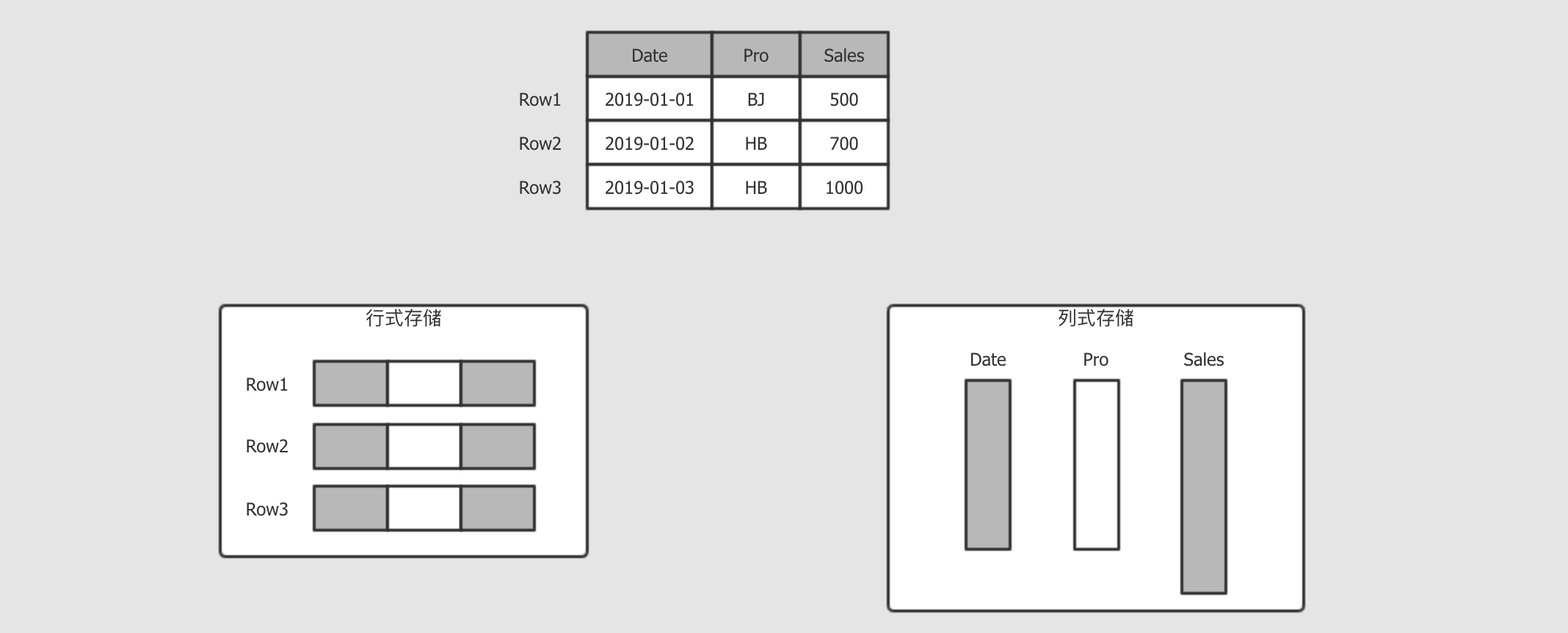
行式存储
行式一般用做于
OLTP, 例如我的订单, 那不仅要看到订单, 还要看到收货地址, 付款信息, 派送信息等, 所以OLTP一般是倾向于获取整行所有列的信息列式存储
而分析平台就不太一样了, 例如分析销售额, 那可能只对销售额这一列感兴趣, 所以按照列存储, 只获取需要的列, 这样能减少数据的读取量
- 存储模型
-
- 结构
-
Kudu的存储模型是有结构的表OLTP中代表性的MySQL,Oracle模型是有结构的表HBase是看起来像是表一样的Key-Value型数据,Key是RowKey和列簇的组合,Value是具体的值
- 主键
-
Kudu采用了Raft协议, 所以Kudu的表中有唯一主键关系型数据库也有唯一主键
HBase的RowKey并不是唯一主键
- 事务支持
-
Kudu缺少跨行的ACID事务关系型数据库大多在单机上是可以支持
ACID事务的
- 性能
-
Kudu的随机读写速度目标是和HBase相似, 但是这个目标建立在使用SSD基础之上Kudu的批量查询性能目标是比HDFS上的Parquet慢两倍以内
- 硬件需求
-
Hadoop的设计理念是尽可能的减少硬件依赖, 使用更廉价的机器, 配置机械硬盘Kudu的时代SSD已经比较常见了, 能够做更多的磁盘操作和内存操作Hadoop不太能发挥比较好的硬件的能力, 而Kudu为了大内存和SSD而设计, 所以Kudu对硬件的需求会更大一些
1.3. Kudu 的设计和结构
Kudu是什么Kudu的整体设计Kudu的角色Kudu的概念
Kudu是什么-
HDFS上的数据分析-
HDFS是一种能够非常高效的进行数据分析的存储引擎HDFS有很多支持压缩的列式存储的文件格式, 性能很好, 例如Parquet和ORCHDFS本身支持并行
HBase可以进行高效的数据插入和读取-
HBase主要用于完成一些对实时性要求比较高的场景HBase能够以极高的吞吐量来进行数据存储, 无论是批量加载, 还是大量putHBase能够对主键进行非常高效的扫描, 因为其根据主键进行排序和维护但是对于主键以外的列进行扫描则性能会比较差
Kudu的设计目标-
Kudu最初的目标是成为一个新的存储引擎, 可以进行快速的数据分析, 又可以进行高效的数据随机插入, 这样就能简化数据从源端到Hadoop中可以用于被分析的过程, 所以有如下的一些设计目标尽可能快速的扫描, 达到
HDFS中Parquet的二分之一速度尽可能的支持随机读写, 达到
1ms的响应时间列式存储
支持
NoSQL样式的API, 例如put,get,delete,scan
- 总体设计
-
Kudu不支持SQLKudu和Impala都是Cloudera的项目, 所以Kudu不打算自己实现SQL的解析和执行计划, 而是选择放在Impala中实现, 这两个东西配合来完成任务Kudu的底层是一个基于表的引擎, 但是提供了NoSQL的APIKudu中存储两类的数据Kudu存储自己的元信息, 例如表名, 列名, 列类型Kudu当然也有存放表中的数据
这两种数据都存储在
tablet中Master server存储元数据的
tablet由Master server管理Tablet server存储表中数据的
tablet由不同的Tablet server管理tabletMaster server和Tablet server都是以tablet作为存储形式来存储数据的, 一个tablet通常由一个Leader和两个Follower组成, 这些角色分布的不同的服务器中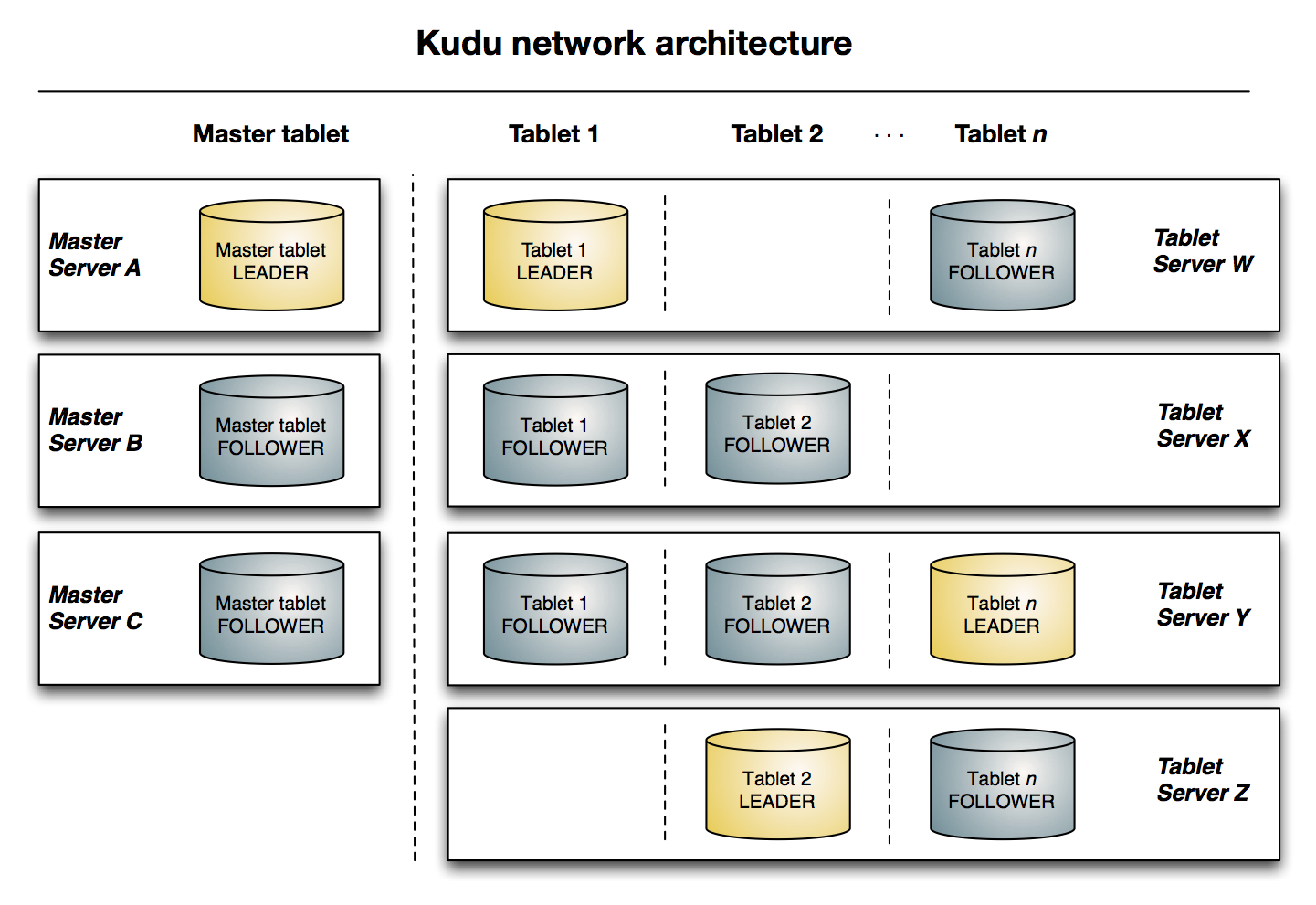
Master server-
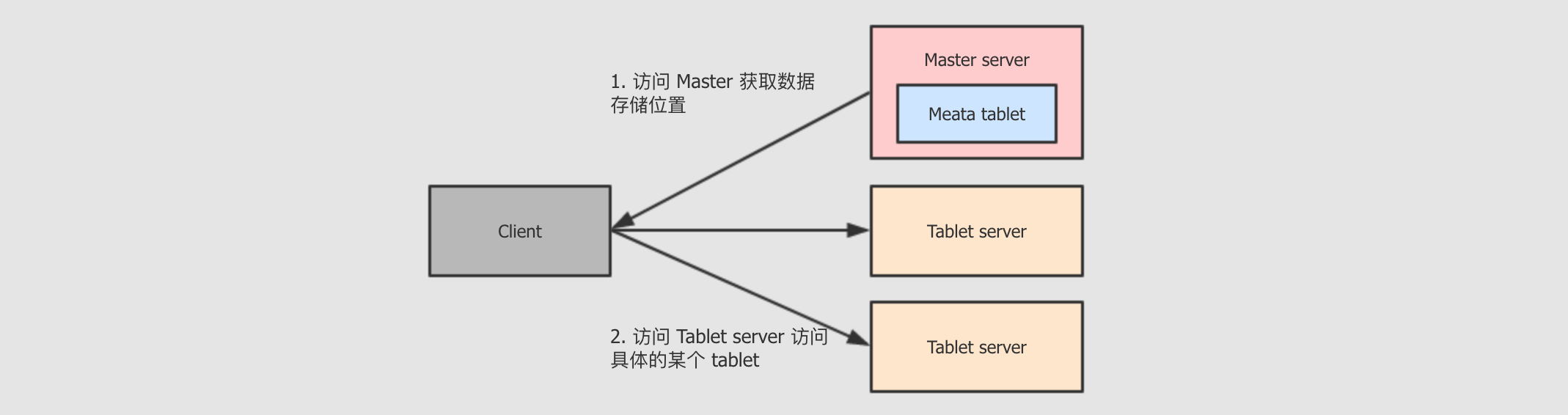
Master server中存储的其实也就是一个tablet, 这个tablet中存储系统的元数据, 所以Kudu无需依赖Hive客户端访问某一张表的某一部分数据时, 会先询问
Master server, 获取这个数据的位置, 去对应位置获取或者存储数据虽然
Master比较重要, 但是其承担的职责并不多, 数据量也不大, 所以为了增进效率, 这个tablet会存储在内存中生产环境中通常会使用多个
Master server来保证可用性
Tablet server-
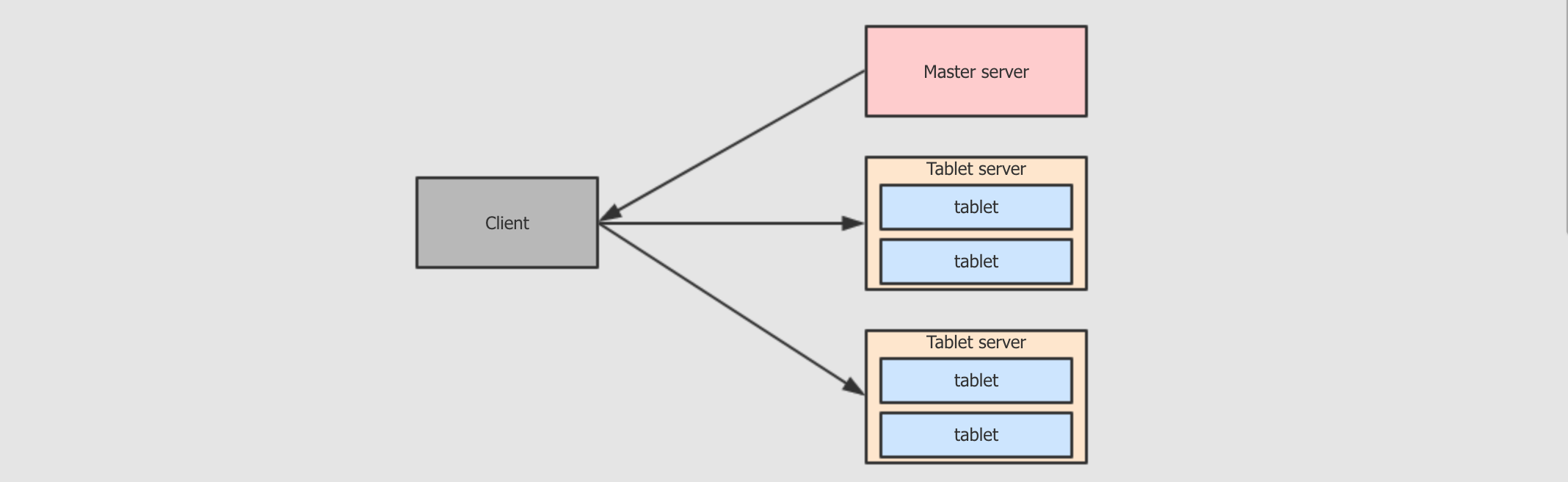
Tablet server中也是tablet, 但是其中存储的是表数据Tablet server的任务非常繁重, 其负责和数据相关的所有操作, 包括存储, 访问, 压缩, 其还负责将数据复制到其它机器因为
Tablet server特殊的结构, 其任务过于繁重, 所以有如下的限制Kudu最多支持300个服务器, 建议Tablet server最多不超过100个建议每个
Tablet server至多包含2000个tablet(包含Follower)建议每个表在每个
Tablet server中至多包含60个tablet(包含Follower)每个
Tablet server至多管理8TB数据理想环境下, 一个
tablet leader应该对应一个CPU核心, 以保证最优的扫描性能
tablet的存储结构-
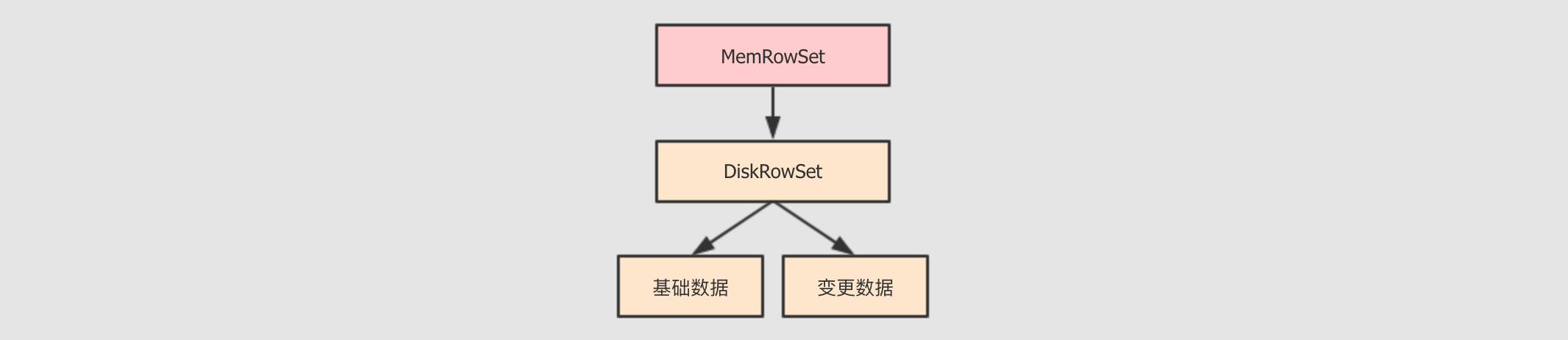
在
Kudu中, 为了同时支持批量分析和随机访问, 在整体上的设计一边参考了Parquet这样的文件格式的设计, 一边参考了HBase的设计MemRowSet这个组件就很像
HBase中的MemoryStore, 是一个缓冲区, 数据来了先放缓冲区, 保证响应速度DiskRowSet列存储的好处不仅仅只是分析的时候只
I/O对应的列, 还有一个好处, 就是同类型的数据放在一起, 更容易压缩和编码DiskRowSet中的数据以列式组织, 类似Parquet中的方式, 对其中的列进行编码, 通过布隆过滤器增进查询速度
tablet的Insert流程-
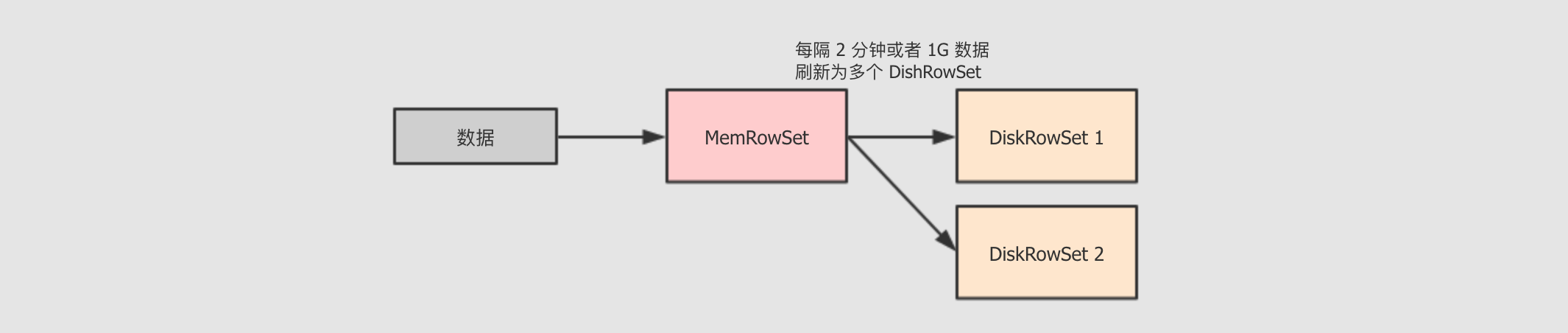
使用 MemRowSet 作为缓冲, 特定条件下写为多个 DiskRowSet
在插入之前, 为了保证主键唯一性, 会已有的 DiskRowSet 和 MemRowSet 进行验证, 如果主键已经存在则报错
tablet的Update流程-
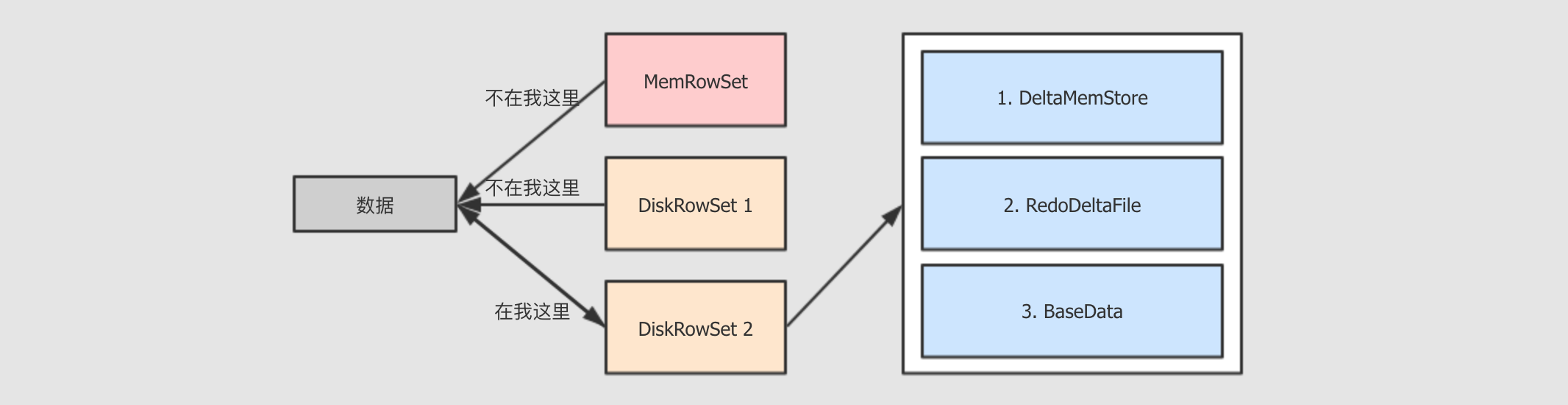
查找要更新的数据在哪个
DiskRowSet中数据放入
DiskRowSet所持有的DeltaMemStore中, 这一步也是暂存特定时机下,
DeltaMemStore会将数据溢写到磁盘, 生成RedoDeltaFile, 记录数据的变化定时合并
RedoDeltaFile合并策略有三种, 常见的有两种, 一种是
major, 会将数据合并到基线数据中, 一种是minor, 只合并RedoDeltaFile
2. Kudu 安装和操作
因为 Kudu 经常和 Impala 配合使用, 所以我们也要安装 Impala, 但是又因为 Impala 强依赖于 CDH, 所以我们连 CDH 一起安装一下, 做一个完整的 CDH 集群, 搭建一套新的虚拟机
创建虚拟机准备初始环境
安装
Zookeeper安装
Hadoop安装
MySQL安装
Hive安装
Kudu安装
Impala
2.1. 准备初始环境
之前的环境中已经安装了太多环境, 所以换一个新的虚拟机, 从头开始安装
创建虚拟机
安装系统
复制三台虚拟机
配置时间同步服务
配置主机名
关闭
SELinux关闭防火墙
重启
配置免密登录
安装
JDK
Step 1: 创建虚拟机-
在
VmWare中点击创建虚拟机
打开向导
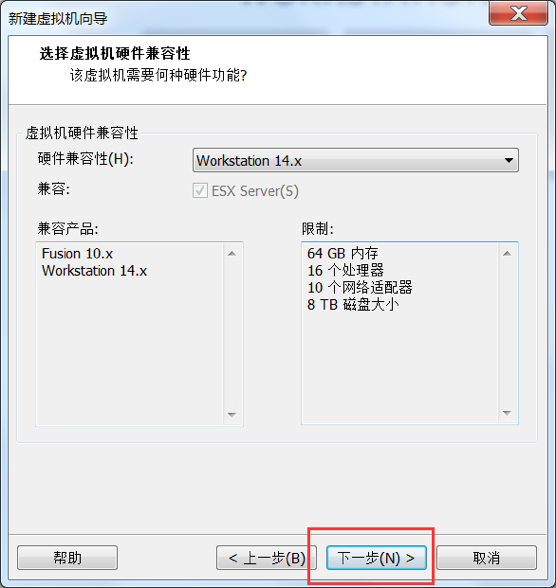
设置硬件兼容性
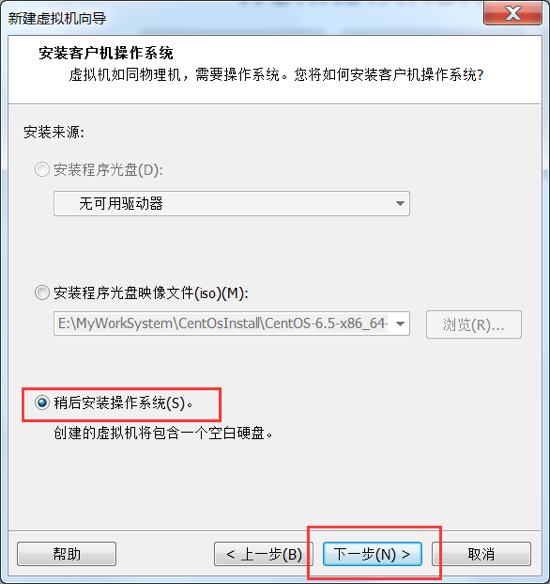
指定系统安装方式
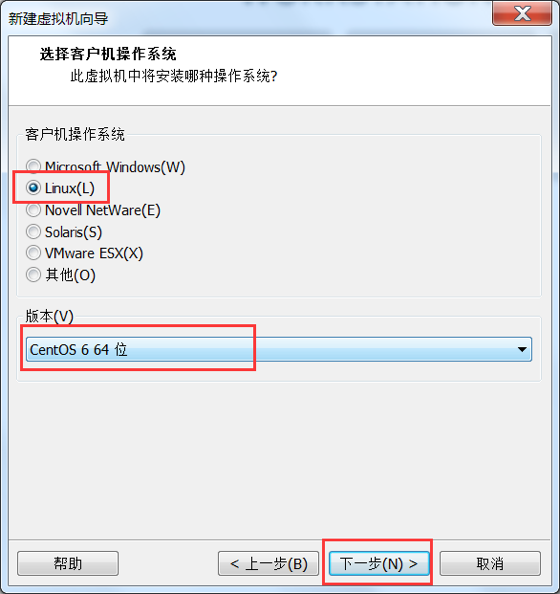
指定系统类型
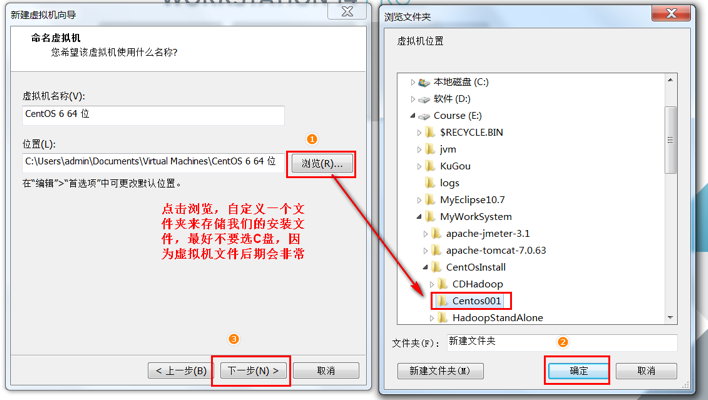
指定虚拟机位置
处理器配置
内存配置
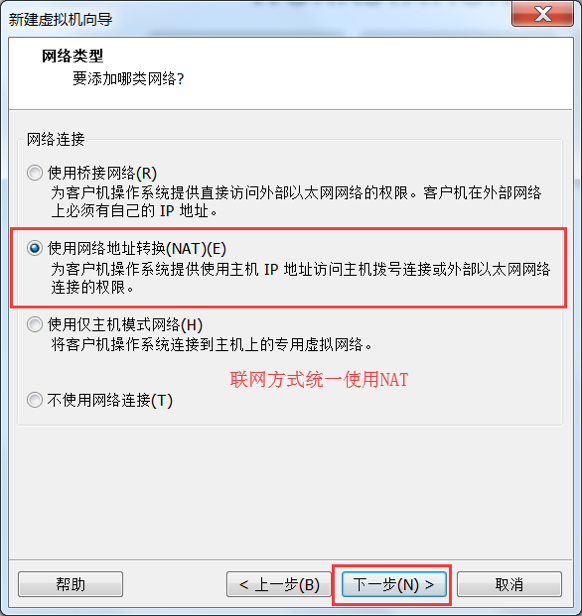
选择网络类型, 这一步非常重要, 一定要配置正确
选择
I/O类型
选择虚拟磁盘类型
选择磁盘创建方式
创建新磁盘
指定磁盘文件位置
终于, 虚拟机创建好了, 复制图片差点没给我累挂
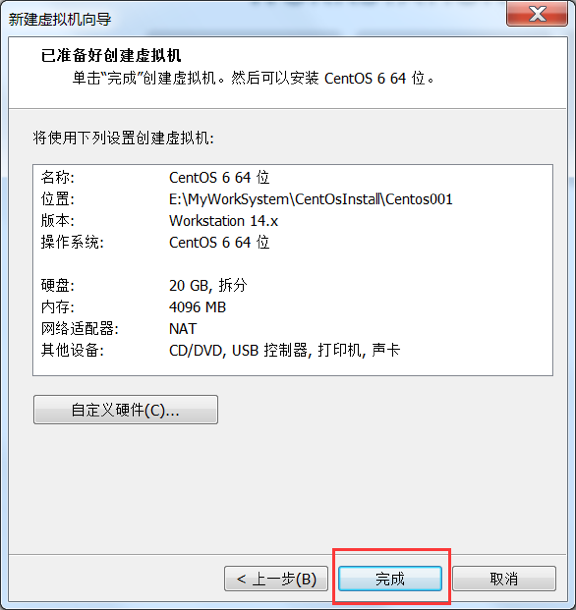
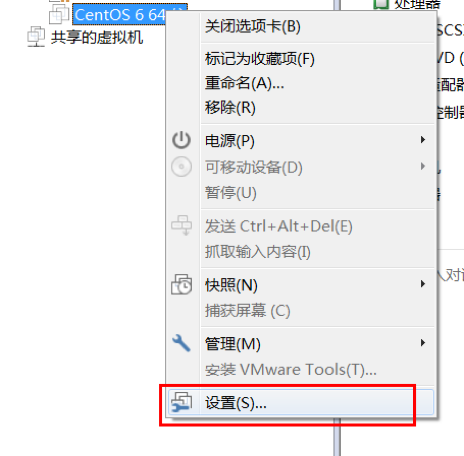
Step 2: 安装CentOS 6-
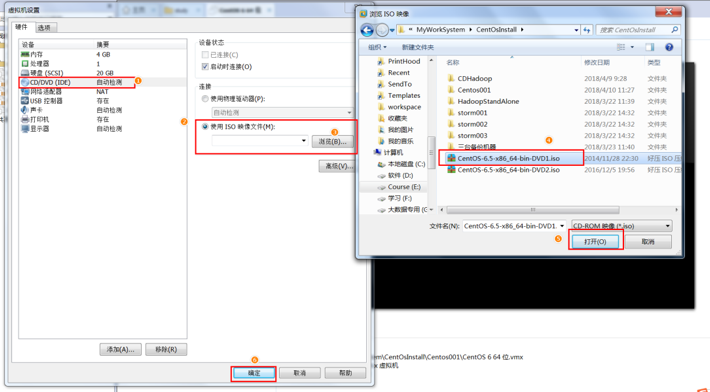
为虚拟机挂载安装盘
选择安装盘
开启虚拟机
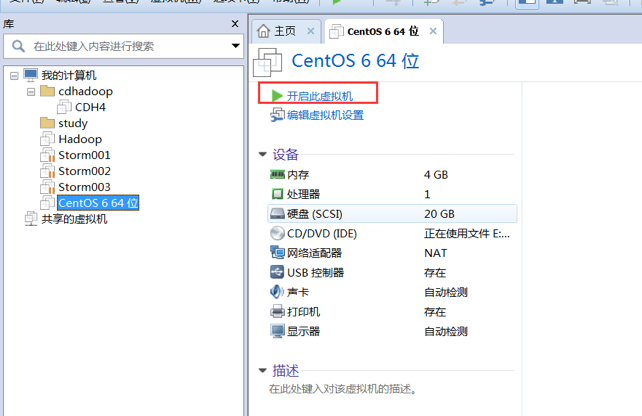
进入 CentOS 6 的安装
跳过磁盘选择
选择语言
选择键盘类型
选择存储设备类型
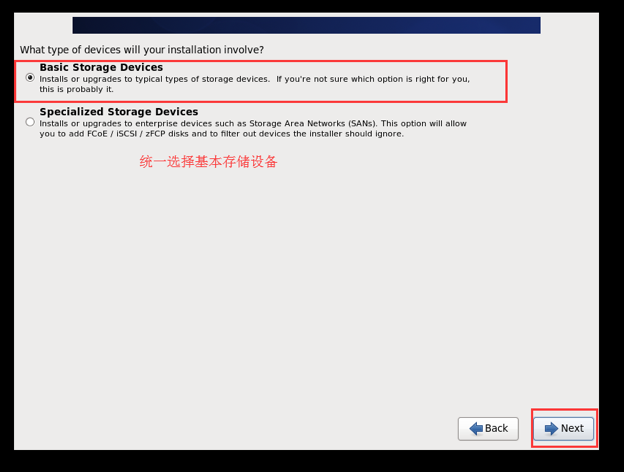
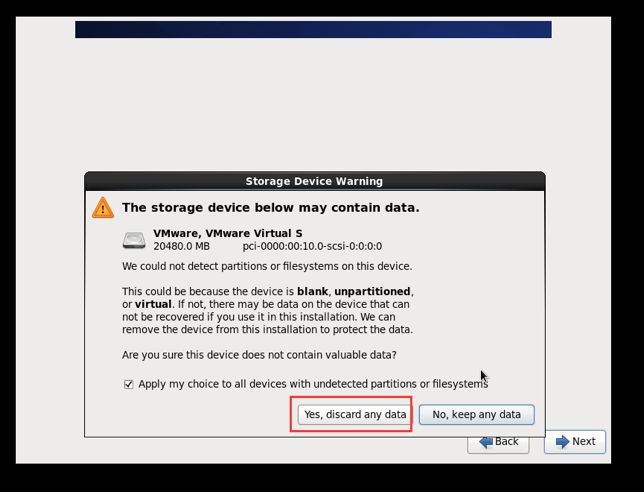
清除数据
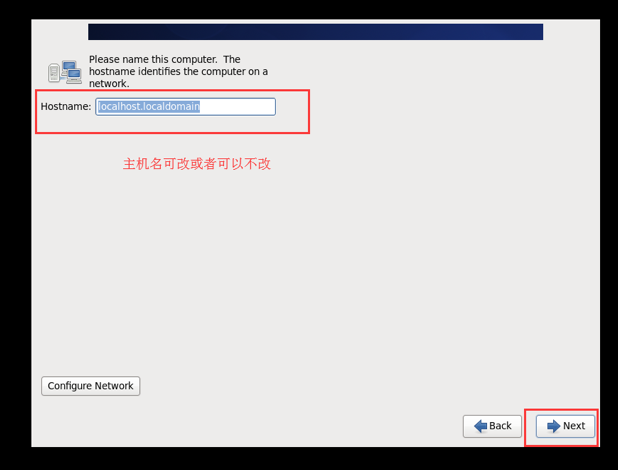
主机名
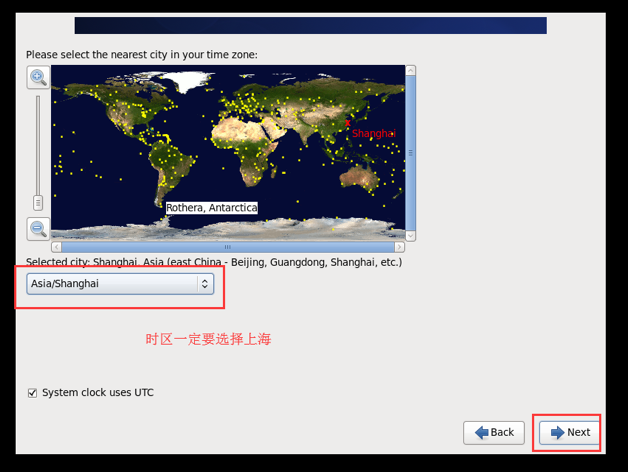
选择时区, 这一步很重要, 一定要选
设置
root账号, 密码最好是统一的, 就hadoop吧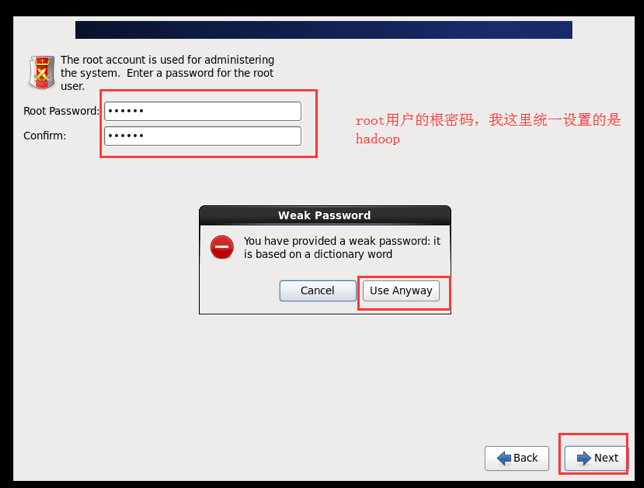
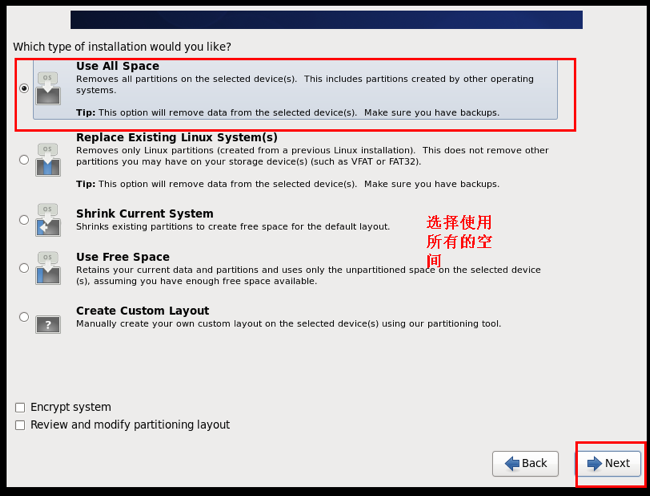
选择安装类型
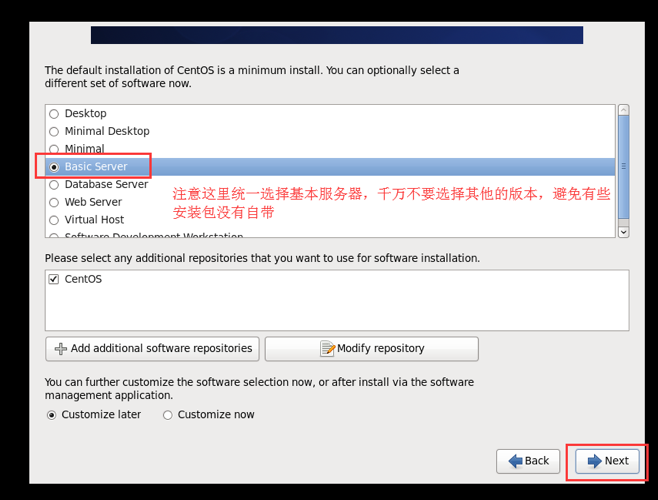
选择安装软件的类型
安装完成, 终于不用复制图片了, 开心

Step 3: 集群规划-
HostNameIPcdh01.itcast.cn
192.168.169.101
cdh02.itcast.cn
192.168.169.102
cdh03.itcast.cn
192.168.169.103
已经安装好一台虚拟机了, 接下来通过复制的方式创建三台虚拟机
复制虚拟机文件夹(Ps. 在创建虚拟机时候选择的路径)
进入三个文件夹中, 点击
vmx文件, 让 VmWare 加载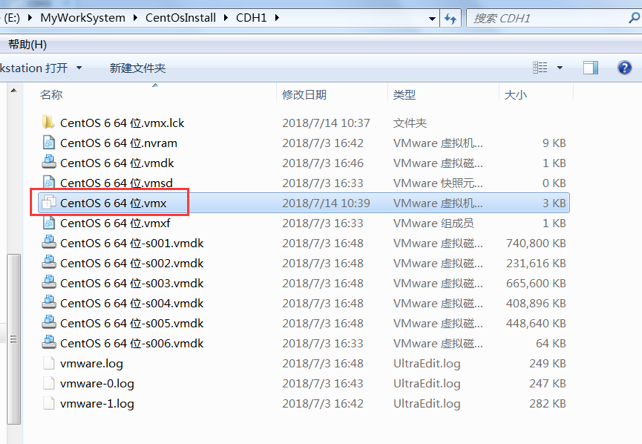
为所有的虚拟机生成新的
MAC地址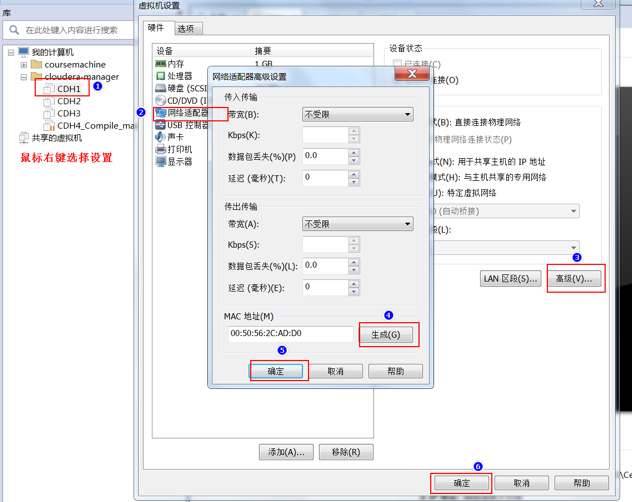
确认
vmnet8的网关地址, 以及这块虚拟网卡的地址修改网卡信息
进入每台机器中, 修改
70-persistent-net.rulesvi /etc/udev/rules.d/70-persistent-net.rules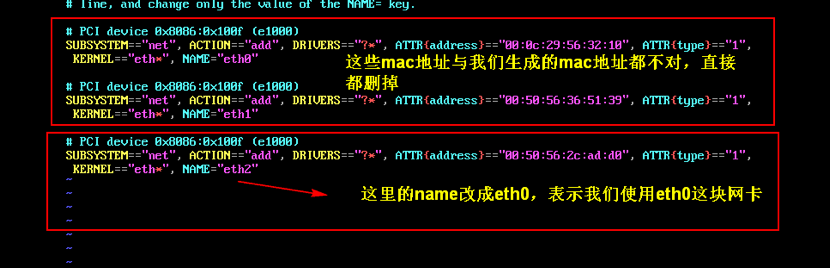
更改
IP地址, 修改/etc/sysconfig/network-scripts/ifcfg-eth0 文件。 注意: 1. 网关地址要和vmnet8的网关地址一致, 2.IP改为192.168.169.101; 3.修改好后,重启系统! 4.可以通过ifconfig 或者 ip addr这2个命令来查验IP地址是否正确。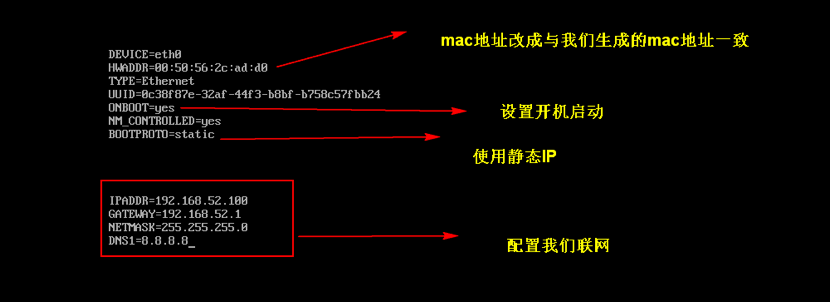
Step 4: 配置时间同步服务-
在几乎所有的分布式存储系统上, 都需要进行时钟同步, 避免出现旧的数据在同步过程中变为新的数据, 包括
HBase,HDFS,Kudu都需要进行时钟同步, 所以在一切开始前, 先同步一下时钟, 保证没有问题时钟同步比较简单, 只需要确定时钟没有太大差异, 然后开启
ntp的自动同步服务即可yum install -y ntp
service ntpd start
chkconfig ntpd on 设置开机启动同步大概需要
5 - 10分钟, 然后查看是否已经是同步状态即可ntpstat最后在其余两台节点也要如此配置一下
Step 5: 配置主机名-
配置主机名是为了在网络内可以通信
修改
/etc/sysconfig/network文件, 声明主机名# 在三个节点上使用不同的主机名
HOSTNAME=cdh01.itcast.cn修改
/etc/hosts文件, 确定DNS的主机名127.0.0.1 cdh01.itcast.cn localhost cdh01 192.168.169.101 cdh01.itcast.cn cdh01
192.168.169.102 cdh02.itcast.cn cdh02
192.168.169.103 cdh03.itcast.cn cdh03在其余的两台机器中也要如此配置
Step 6: 关闭SELinux-
修改
/etc/selinus/config将SELinux关闭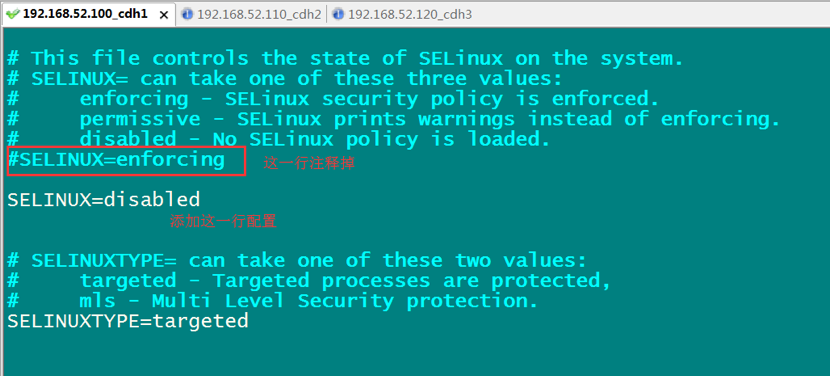
最后别忘了再其它节点也要如此配置
Step 7: 关闭防火墙-
执行如下命令做两件事, 关闭防火墙, 关闭防火墙开机启动
service iptables stop
chkconfig iptables off最后别忘了再其它节点也要如此配置
Step x: 重启-
刚才有一些配置是没有及时生效的, 为了避免麻烦, 在这里可以重启一下, 在三台节点上依次执行命令
reboot -h now Step 8: 配置三台节点的免密登录-
SSH 有两种登录方式
输入密码从而验证登录
服务器生成随机字符串, 客户机使用私钥加密, 服务器使用预先指定的公钥解密, 从而验证登录
所以配置免密登录就可以使用第二种方式, 大概步骤就是先在客户机生成密钥对, 然后复制给服务器
# 生成密钥对
ssh-keygen -t rsa # 拷贝公钥到服务机
ssh-copy-id cdh01
ssh-copy-id cdh02
ssh-copy-id cdh03然后在三台节点上依次执行这些命令
Step 9: 安装JDK-
安装
JDK之前, 可以先卸载已经默认安装的JDK, 这样可以避免一些诡异问题查看是否有存留的
JDKrpm -qa | grep java如果有, 则使用如下命令卸载
rpm -e -nodeps xx上传 JDK 包到服务器中
解压并拷贝到
/usr/java中tar xzvf jdk-8u192-linux-x64.tar.gz
mv jdk1.8.0_192 /usr/java/修改
/etc/hosts配置环境变量export JAVA_HOME=/usr/java/jdk1.8.0_192
export PATH=$PATH:$JAVA_HOME/bin在剩余两台主机上重复上述步骤
2.2. 创建本地 Yum 仓库
创建本地 Yum 仓库的目的是因为从远端的 Yum 仓库下载东西的速度实在是太渣, 然而 CDH 的所有组件几乎都要从 Yum 安装, 所以搭建一个本地仓库会加快下载速度
下载
CDH的所有安装包生成
CDH的Yum仓库配置服务器, 在局域网共享仓库
Step 1: 下载CDH的安装包-
创建本地
Yum仓库的原理是将CDH的安装包下载下来, 提供Http服务给局域网其它主机(或本机), 让其它主机的Yum能够通过Http服务下载CDH的安装包, 所以需要先下载对应的CDH安装包需要注意的是, 这一步可以一点都不做, 因为已经为大家提供了对应的安装包, 在 DMP的目录中, 就能找到cloudera-cdh5这个目录, 上传到服务器即可下载
CDH的安装包需要使用CDH的一个工具, 要安装CDH的这个工具就要先导入CDH的Yum源wget https://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/cloudera-cdh5.repo
mv cloudera-cdh5.repo /etc/yum.repos.d/安装
CDH安装包同步工具yum install -y yum-utils createrepo同步
CDH的安装包reposync -r cloudera-cdh5
Step 2: 创建本地Yum仓库服务器-
创建本地
Yum仓库的原理是将CDH的安装包下载下来, 提供Http服务给局域网其它主机(或本机), 让其它主机的Yum能够通过Http服务下载CDH的安装包, 所以需要提供Http服务, 让本机或者其它节点可以通过Http下载文件, Yum 本质也就是帮助我们从Yum的软件仓库下载软件安装
Http服务器软件yum install -y httpd
service httpd start创建
Yum仓库的Http目录mkdir -p /var/www/html/cdh/5
cp -r cloudera-cdh5/RPMS /var/www/html/cdh/5/
cd /var/www/html/cdh/5
createrepo .在三台主机上配置
Yum源最后一步便是向
Yum增加一个新的源, 指向我们在cdh01上创建的Yum仓库, 但是在这个环节的第一步中, 已经下载了一个Yum的源, 只需要修改这个源的文件, 把URL替换为cdh01的地址即可所以在
cdh01上修改文件/etc/yum.repos.d/cloudera-cdh5.repo为baseurl=http://cdh01/cdh/5/在
cdh02和cdh03上下载这个文件wget https://archive.cloudera.com/cdh5/redhat/7/x86_64/cdh/cloudera-cdh5.repo
mv cloudera-cdh5.repo /etc/yum.repos.d/然后在 cdh02 和 cdh03 上修改文件
/etc/yum.repos.d/cloudera-cdh5.repobaseurl=http://cdh01/cdh/5/
Update(Stage5):Kudu入门_项目介绍_ CDH搭建的更多相关文章
- Update(Stage5):DMP项目_业务介绍_框架搭建
DMP (Data Management Platform) 导读 整个课程的内容大致分为如下两个部分 业务介绍 技术实现 对于业务介绍, 比较困难的是理解广告交易过程中各个参与者是干什么的 对于技术 ...
- VS2017中使用组合项目_windows服务+winform管理_项目发布_测试服务器部署
前言:作为一名C#开发人员,避免不了常和windows服务以及winform项目打交道,本人公司对服务的管理也是用到了这2个项目的组合方式进行:因为服务项目是无法直接安装到计算器中,需要使用命令借助微 ...
- 多测师讲解jmeter _基本介绍_(001)高级讲师肖sir
jmeter讲课课程 一.Jmeter简介 Jmeter是由Apache公司开发的一个纯Java的开源项目,即可以用于做接口测试也可以用于做性能测试. Jmeter具备高移植性,可以实现跨平台运行. ...
- SCF(SenparcCoreFramework) 系列教程(一):项目介绍及快速搭建
2020年3月25日的“盛派周三分享”活动首次使用直播的方式与大家见面,共有 500 多人参与了活动,得到了众多开发者的好评,并强烈要求我分享 PPT,这点要求当然必须满足啦! 除此以外,还有许多开发 ...
- Update(Stage4):Structured Streaming_介绍_案例
1. 回顾和展望 1.1. Spark 编程模型的进化过程 1.2. Spark 的 序列化 的进化过程 1.3. Spark Streaming 和 Structured Streaming 2. ...
- 2_MVC+EF+Autofac(dbfirst)轻型项目框架_用户权限验证
前言 接上面两篇 0_MVC+EF+Autofac(dbfirst)轻型项目框架_基本框架 与 1_MVC+EF+Autofac(dbfirst)轻型项目框架_core层(以登陆为例) .在第一篇中介 ...
- JavaWeb_(Mybatis框架)主配置文件介绍_四
系列博文: JavaWeb_(Mybatis框架)JDBC操作数据库和Mybatis框架操作数据库区别_一 传送门 JavaWeb_(Mybatis框架)使用Mybatis对表进行增.删.改.查操作_ ...
- C#_ 项目打包附加数据库
C#_ 项目打包附加数据库 2010-07-11 23:22:45| 分类: Winfrom|举报|字号 订阅 实现效果:安装项目时直接附加数据库. 1.首先在需要部 署的项目的解决方案资源 ...
- python中multiprocessing.pool函数介绍_正在拉磨_新浪博客
python中multiprocessing.pool函数介绍_正在拉磨_新浪博客 python中multiprocessing.pool函数介绍 (2010-06-10 03:46:5 ...
随机推荐
- java基础(八)之函数的复写/重写(override)
复写的意思就是子类对父类的修改. 复写的条件: 1.在具有父子类关系的两个类当中:2.父类和子类各有一个函数,这两个函数的定义保持一致(返回值类型.函数名.参数列表) 还是老样子,3个文件来说明. P ...
- DFT 问答 III
1.Boundary scan Boundary Scan就是我们俗称的边界扫描.Boundary Scan是上世纪90年代由 Joint Test Action Group(JTAG)提出的,它的初 ...
- Vue - 过渡 列表过渡
列表的进入/离开过渡 获取不大于数组长度的随机数,作为插入新值的位置 <div id="app" class="demo"> <button ...
- 【做题笔记】P2871 [USACO07DEC]手链Charm Bracelet
就是 01 背包.大意:给您 \(T\) 个空间大小的限制,有 \(M\) 个物品,第 \(i\) 件物品的重量为 \(c_i\) ,价值为 \(w_i\) .要求挑选一些物品,使得总空间不超过 \( ...
- JS-对象常用方法整理
查看对象的方法,继续控制台输出,如图: hasOwnProperty():返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键). let object1 = new Obje ...
- next路由跳转监听
next的路由跳转监听事件 { “routeChangeStart”, "beforeHisroryChange" "routeChangeComplete", ...
- Educational Codeforces Round 80 (Rated for Div. 2)E(树状数组,模拟,思维)
#define HAVE_STRUCT_TIMESPEC #include<bits/stdc++.h> using namespace std; ],mx[],a[],pos[],sum ...
- async+队列queue.Queue()
import queue import time import random import threading import asyncio import logging logging.basicC ...
- Python - 定时动态获取IP代理池,存放在文件中
定时功能通过module time + 死循环实现,因为time.sleep()会自动阻塞 get_ip_pool.py """ @__note__: while Tru ...
- opencv:截取 ROI 区域
Rect roi; roi.x = 100; roi.y = 100; roi.width = 250; roi.height = 200; // 截取 ROI 区域 // 这种方式改变 sub,原图 ...