htmlunit的使用
原文转自:https://www.cnblogs.com/davidwang456/articles/8693050.html
HtmlUnit使用场景
- httpClient的局限性
对于使用java实现的网页爬虫程序,我们一般可以使用apache的HttpClient组件进行HTML页面信息的获取,HttpClient实现的http请求返回的响应一般是纯文本的document页面,即最原始的html页面。
对于一个静态的html页面来说,使用httpClient足够将我们所需要的信息爬取出来了。但是对于现在越来越多的动态网页来说,更多的数据是通过异步JS代码获取并渲染到的,最开始的html页面是不包含这部分数据的。
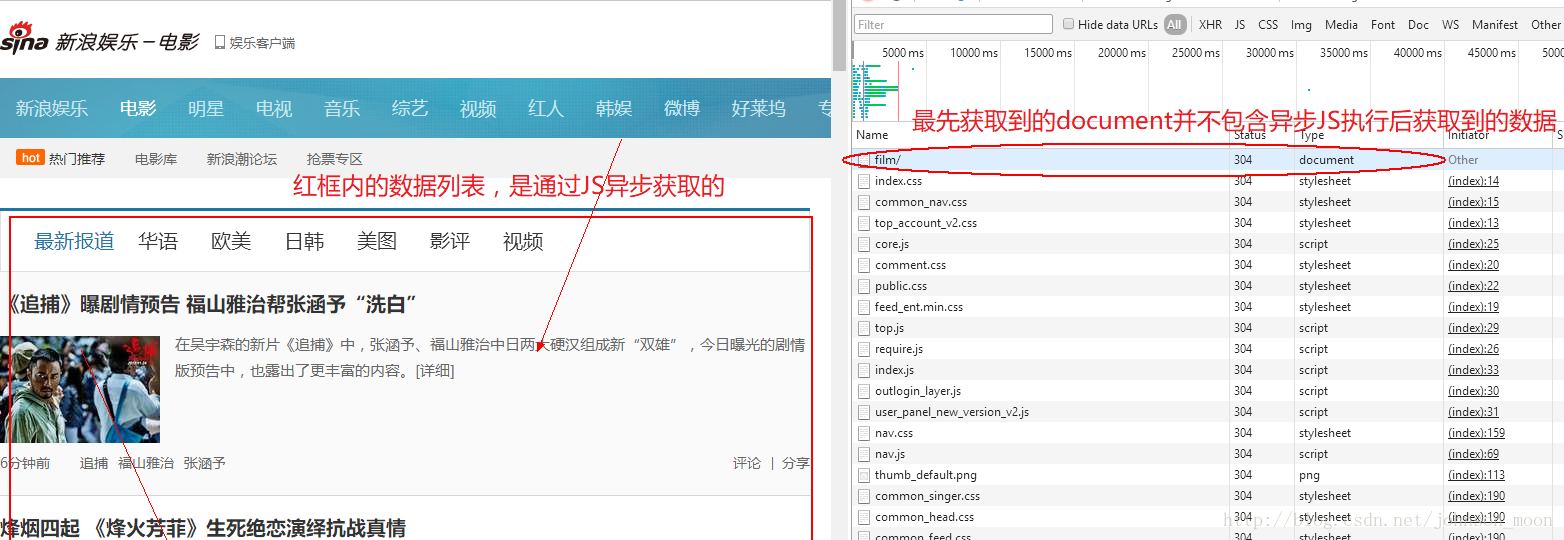
上图我们所见到的网页,在最初的document加载完成之后,并不会看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据,渲染到最初的document页面中,才最终变成了我们看到的网页。而对于这部分需要执行JS代码获取的数据,httpClient就显得无能为力了。虽然我们可以通过研究拿到JS执行的请求路径再用java代码获取我们需要的这部分数据,且不说我们能不能够从JS脚本中分析到这个请求路径和请求参数,光是分析这部分源码的代价就已经很高了。
- HtmlUnit来解决
通过上面的介绍,我们了解了现在很大一部分动态网页,展现的数据都是通过异步JS请求获取,然后再通过JS对页面进行渲染得到的。那我们是不是可以进行这么一个假设,假设我们的爬虫程序模拟了一个浏览器,在获取html页面之后,像浏览器一样执行异步JS代码,等到JS将html页面渲染完成之后,就可以愉快的获取页面上的节点信息了。那么有没有这样的java程序呢?
答案是有的。
HtmlUnit就是这么一个程序库,用来做出了界面展示意外所有的异步工作。由于没有了展示这一块耗时的工作,HtmlUnit加载完成一个完整的网页要比实际的浏览器块多了。并且根据不同配置,HtmlUnit可以模拟市面上常用的浏览器如Chrome、Firefox、IE浏览器等。
通过HtmlUnit库,加载一个完整的Html页面(图片视频除外),然后就可以将其转换成我们常用的字串格式,用其他工具如Jsoup来获取其中的元素了。当然也可以直接在HtmlUnit提供的对象中获取网页元素,甚至是操作如按钮、表单等控件。除了不能像可见浏览器一样用鼠标键盘浏览网页之外,我们可以用HtmlUnit来模拟操作其他的一切操作,像登录网站,撰写博客等等都是可以完成的。当然网页内容爬取是最简单的一个应用了。
HtmlUnit使用方法
1.新建maven工程,添加HtmlUnit依赖:
<dependencies>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.27</version>
</dependency>
</dependencies>- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.新建一个Junit TestCase来尝试一下程序库的使用
程序代码注释如下:
package xuyihao.util.depend;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.junit.Test;
import java.util.List;
/**
* Created by xuyh at 2017/11/6 14:03.
*/
public class HtmlUtilTest {
@Test
public void test() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);//新建一个模拟谷歌Chrome浏览器的浏览器客户端对象
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常, 这里选择不需要
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常, 这里选择不需要
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);//是否启用CSS, 因为不需要展现页面, 所以不需要启用
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
HtmlPage page = null;
try {
page = webClient.getPage("http://ent.sina.com.cn/film/");//尝试加载上面图片例子给出的网页
} catch (Exception e) {
e.printStackTrace();
}finally {
webClient.close();
}
webClient.waitForBackgroundJavaScript(30000);//异步JS执行需要耗时,所以这里线程要阻塞30秒,等待异步JS执行结束
String pageXml = page.asXml();//直接将加载完成的页面转换成xml格式的字符串
//TODO 下面的代码就是对字符串的操作了,常规的爬虫操作,用到了比较好用的Jsoup库
Document document = Jsoup.parse(pageXml);//获取html文档
List<Element> infoListEle = document.getElementById("feedCardContent").getElementsByAttributeValue("class", "feed-card-item");//获取元素节点等
infoListEle.forEach(element -> {
System.out.println(element.getElementsByTag("h2").first().getElementsByTag("a").text());
System.out.println(element.getElementsByTag("h2").first().getElementsByTag("a").attr("href"));
});
}
}上面的例子将获取到的页面中消息列表的标题和超链接URL打印到控制台,操作HTML文档的库是Jsoup,需要添加依赖:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>- 1
- 2
- 3
- 4
- 5
经过三十秒的等待,控制台输出的结果是这样的:
十一月 06, 2017 2:17:05 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'application/x-javascript'.
十一月 06, 2017 2:17:06 下午 com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter runtimeError
严重: runtimeError: message=[An invalid or illegal selector was specified (selector: '*,:x' error: Invalid selector: :x).] sourceName=[http://n.sinaimg.cn/lib/core/core.js] line=[1] lineSource=[null] lineOffset=[0]
十一月 06, 2017 2:17:06 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'application/x-javascript'.
2017-11-06 14:17:11.003:INFO::JS executor for com.gargoylesoftware.htmlunit.WebClient@618c5d94: Logging initialized @7179ms to org.eclipse.jetty.util.log.StdErrLog
十一月 06, 2017 2:17:11 下午 com.gargoylesoftware.htmlunit.javascript.host.WebSocket run
严重: WS connect error
java.util.concurrent.ExecutionException: org.eclipse.jetty.websocket.api.UpgradeException: 0 null
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1895)
at com.gargoylesoftware.htmlunit.javascript.host.WebSocket$1.run(WebSocket.java:151)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:672)
at org.eclipse.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:590)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.eclipse.jetty.websocket.api.UpgradeException: 0 null
at org.eclipse.jetty.websocket.client.WebSocketUpgradeRequest.onComplete(WebSocketUpgradeRequest.java:513)
at org.eclipse.jetty.client.ResponseNotifier.notifyComplete(ResponseNotifier.java:193)
at org.eclipse.jetty.client.ResponseNotifier.notifyComplete(ResponseNotifier.java:185)
at org.eclipse.jetty.client.HttpExchange.notifyFailureComplete(HttpExchange.java:269)
at org.eclipse.jetty.client.HttpExchange.abort(HttpExchange.java:240)
at org.eclipse.jetty.client.HttpConversation.abort(HttpConversation.java:141)
at org.eclipse.jetty.client.HttpRequest.abort(HttpRequest.java:748)
at org.eclipse.jetty.client.HttpDestination.abort(HttpDestination.java:444)
at org.eclipse.jetty.client.HttpDestination.failed(HttpDestination.java:224)
at org.eclipse.jetty.client.AbstractConnectionPool$1.failed(AbstractConnectionPool.java:122)
at org.eclipse.jetty.util.Promise$Wrapper.failed(Promise.java:136)
at org.eclipse.jetty.client.HttpClient$1$1.failed(HttpClient.java:588)
at org.eclipse.jetty.client.AbstractHttpClientTransport.connectFailed(AbstractHttpClientTransport.java:154)
at org.eclipse.jetty.client.AbstractHttpClientTransport$ClientSelectorManager.connectionFailed(AbstractHttpClientTransport.java:199)
at org.eclipse.jetty.io.ManagedSelector$Connect.failed(ManagedSelector.java:655)
at org.eclipse.jetty.io.ManagedSelector$Connect.access$1300(ManagedSelector.java:622)
at org.eclipse.jetty.io.ManagedSelector$1.failed(ManagedSelector.java:364)
at org.eclipse.jetty.io.ManagedSelector$CreateEndPoint.run(ManagedSelector.java:604)
... 3 more
Caused by: java.lang.NullPointerException
at org.eclipse.jetty.io.ssl.SslClientConnectionFactory.newConnection(SslClientConnectionFactory.java:59)
at org.eclipse.jetty.client.AbstractHttpClientTransport$ClientSelectorManager.newConnection(AbstractHttpClientTransport.java:191)
at org.eclipse.jetty.io.ManagedSelector.createEndPoint(ManagedSelector.java:420)
at org.eclipse.jetty.io.ManagedSelector.access$1600(ManagedSelector.java:61)
at org.eclipse.jetty.io.ManagedSelector$CreateEndPoint.run(ManagedSelector.java:599)
... 3 more
十一月 06, 2017 2:17:16 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'application/x-javascript'.
十一月 06, 2017 2:17:21 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'text/javascript'.
十一月 06, 2017 2:17:21 下午 com.gargoylesoftware.htmlunit.IncorrectnessListenerImpl notify
警告: Obsolete content type encountered: 'text/javascript'.
时隔17年重温《EUREKA》 宫崎葵:这次哭得很凶
http://ent.sina.com.cn/m/f/2017-11-06/doc-ifynmzrs7411439.shtml
模式单一成审美疲劳 超级英雄电影该如何突围?
http://ent.sina.com.cn/m/f/2017-11-06/doc-ifynmnae2196060.shtml
组图:《天生不对》首映 薛凯琪不规则红裙优雅可人 13
http://slide.ent.sina.com.cn/film/slide_4_704_247725.html
电影资料馆达成线上售票合作 影迷不必排队买票
http://ent.sina.com.cn/m/c/2017-11-06/doc-ifynmvuq8917282.shtml
组图:詹妮弗加纳去教堂路遇好友 白裙清新心情靓 4
http://slide.ent.sina.com.cn/film/h/slide_4_704_247702.html
《东方快车》发幕后特辑 唯美复古凸显品质
http://ent.sina.com.cn/m/f/2017-11-06/doc-ifynnnsc7188105.shtml
组图:梅根福克斯穿紧身衣身材火辣 踩拖鞋抱瑜伽垫 4
http://slide.ent.sina.com.cn/film/slide_4_704_247699.html忽略HtmlUnit执行时候的报错信息,可以看到最后还是成功的将结果打印了出来了。
3.编写工具类
尝试了一下HtmlUnit加载网页并解析之后,我们可以编写一个工具类为之后的爬虫程序的使用铺路了,代码如下:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* <pre>
* Http工具,包含:
* 高级http工具(使用net.sourceforge.htmlunit获取完整的html页面,即完成后台js代码的运行)
* </pre>
* Created by xuyh at 2017/7/17 19:08.
*/
public class HttpUtils {
/**
* 请求超时时间,默认20000ms
*/
private int timeout = 20000;
/**
* 等待异步JS执行时间,默认20000ms
*/
private int waitForBackgroundJavaScript = 20000;
private static HttpUtils httpUtils;
private HttpUtils() {
}
/**
* 获取实例
*
* @return
*/
public static HttpUtils getInstance() {
if (httpUtils == null)
httpUtils = new HttpUtils();
return httpUtils;
}
public int getTimeout() {
return timeout;
}
/**
* 设置请求超时时间
*
* @param timeout
*/
public void setTimeout(int timeout) {
this.timeout = timeout;
}
public int getWaitForBackgroundJavaScript() {
return waitForBackgroundJavaScript;
}
/**
* 设置获取完整HTML页面时等待异步JS执行的时间
*
* @param waitForBackgroundJavaScript
*/
public void setWaitForBackgroundJavaScript(int waitForBackgroundJavaScript) {
this.waitForBackgroundJavaScript = waitForBackgroundJavaScript;
}
/**
* 将网页返回为解析后的文档格式
*
* @param html
* @return
* @throws Exception
*/
public static Document parseHtmlToDoc(String html) throws Exception {
return removeHtmlSpace(html);
}
private static Document removeHtmlSpace(String str) {
Document doc = Jsoup.parse(str);
String result = doc.html().replace(" ", "");
return Jsoup.parse(result);
}
/**
* 获取页面文档字串(等待异步JS执行)
*
* @param url 页面URL
* @return
* @throws Exception
*/
public String getHtmlPageResponse(String url) throws Exception {
String result = "";
final WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);//是否启用CSS
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
webClient.getOptions().setTimeout(timeout);//设置“浏览器”的请求超时时间
webClient.setJavaScriptTimeout(timeout);//设置JS执行的超时时间
HtmlPage page;
try {
page = webClient.getPage(url);
} catch (Exception e) {
webClient.close();
throw e;
}
webClient.waitForBackgroundJavaScript(waitForBackgroundJavaScript);//该方法阻塞线程
result = page.asXml();
webClient.close();
return result;
}
/**
* 获取页面文档Document对象(等待异步JS执行)
*
* @param url 页面URL
* @return
* @throws Exception
*/
public Document getHtmlPageResponseAsDocument(String url) throws Exception {
return parseHtmlToDoc(getHtmlPageResponse(url));
}
}可以通过这样的方式调用本工具:
import org.jsoup.nodes.Document;
import org.junit.Test;
public class HttpUtilsTest {
private static final String TEST_URL = "http://www.google.com/";
@Test
public void testGetHtmlPageResponse() {
HttpUtils httpUtils = HttpUtils.getInstance();
httpUtils.setTimeout(30000);
httpUtils.setWaitForBackgroundJavaScript(30000);
try {
String htmlPageStr = httpUtils.getHtmlPageResponse(TEST_URL);
//TODO
System.out.println(htmlPageStr);
} catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void testGetHtmlPageResponseAsDocument() {
HttpUtils httpUtils = HttpUtils.getInstance();
httpUtils.setTimeout(30000);
httpUtils.setWaitForBackgroundJavaScript(30000);
try {
Document document = httpUtils.getHtmlPageResponseAsDocument(TEST_URL);
//TODO
System.out.println(document);
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 解析获取的响应文本
// 以 xml 的形式获取响应文本
String pageXml = page.asXml();
// 以 文本 的形式获取响应文本
String pageText = page.asText();
// 获取当前 Url (跳转后的最终Url)
String url = page.getUrl();
关于关闭警告日志和异常日志
- 关掉所有警告日志和异常日志
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log", "org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware.htmlunit").setLevel(Level.OFF);
java.util.logging.Logger.getLogger("org.apache.commons.httpclient").setLevel(Level.OFF);
作者:demil
链接:https://www.jianshu.com/p/f6fa97f36c00
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
源码地址
https://github.com/johnsonmoon/HttpUtils.githtmlunit的使用的更多相关文章
- 爬虫 htmlUnit遇到Cannot locate declared field class org.apache.http.impl.client.HttpClientBuilder.dnsResolve错误
当在使用htmlUnit时遇到无法定位org.apache.http.impl.client.HttpClientBuilder.dnsResolver类时,此时所需要的依赖包为: <depen ...
- HtmlUnit初探
HtmlUnit是一个用java实现的浏览器,是一个无界面的浏览器(headless browser),跟phatomJS好像是同一类事物. HtmlUnit基于apache httpClient,而 ...
- [转载]爬虫的自我解剖(抓取网页HtmlUnit)
网络爬虫第一个要面临的问题,就是如何抓取网页,抓取其实很容易,没你想的那么复杂,一个开源HtmlUnit包,4行代码就OK啦,例子如下: 1 2 3 4 final WebClient webClie ...
- java htmlunit 抓取网页数据
WebClient webClient=new WebClient(BrowserVersion.CHROME); webClient.setJavaScriptTimeout(5000); webC ...
- htmlunit官网简易教程(翻译)
1 环境搭建: 1)下载 从链接:http://sourceforge.net/projects/htmlunit/files/htmlunit/ 下载最新的bin文件 2)关于bin文件 里面主要包 ...
- [HtmlUnit]Fetch Dynamic Html/Content Created By Javascript/Ajax
import com.gargoylesoftware.htmlunit.*; import com.gargoylesoftware.htmlunit.html.HtmlPage; import j ...
- 使用htmlunit在线解析网页信息
前言 最近工作上遇到一个问题,后端有一个定时任务,需要用JAVA每天判断法定节假日.周末放假,上班等情况, 其实想单独通过逻辑什么的去判断中国法定节假日的放假情况,基本不可能,因为国家每一年的假期可能 ...
- 爬虫的自我解剖(抓取网页HtmlUnit)
网络爬虫第一个要面临的问题,就是如何抓取网页,抓取其实很容易,没你想的那么复杂,一个开源`HtmlUnit`包,4行代码就OK啦,例子如下: final WebClient webClient=new ...
- 基于HtmlUnit的模板的网页数据抽取
既然方向定了,就开始做实验室吧,做舆情分析,首先就是要收集相关的语料 正好实验室有同学在做标化院的信息抽取抽取这块 于是把程序拿过来研究研究正好 完整程序在126邮箱共享: 可下载数:20 共享连接 ...
- 浅谈HtmlUnit的使用
一.htmlunit 是一款开源的java 页面分析工具,读取页面后,可以有效的使用htmlunit分析页面上的内容.项目可以模拟浏览器运行,被誉为java浏览器的开源实现.这个没有界面的浏览器,运行 ...
随机推荐
- 结合sqlmap进行sql注入过程
结合sqlmap进行sql注入:(-r后面是通过burp suite抓出来的请求包:-p后面是注入点,即该请求里携带的某个参数) Get请求的注入: ./sqlmap.py -r rss_test.t ...
- Windows Server 2008 R2远程桌面服务安装配置和授权激活
1.安装 2.远程桌面授权激活 2.1 管理工具——远程桌面服务——(远程桌面授权管理)RD授权管理器: 2.2 由于RD授权服务器还未激活,所以授权服务器图标右下角显示红色×号: 点服务器展开——右 ...
- 计算几何-Graham法-凸包
This article is made by Jason-Cow.Welcome to reprint.But please post the article's address. 关键一句话 Cr ...
- Vue.js 学习入门:介绍及安装
Vue.js 是什么? Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视图层 ...
- java spring-boot 服务器启动参数设置
java -jar -Xms5866m -Xmx5866m -Xss256k -Xloggc:/home/work/spring-boot/logs/gc-%t.log -XX:+UseGCLogFi ...
- 「JSOI2015」圈地
「JSOI2015」圈地 传送门 显然是最小割. 首先对于所有房子,权值 \(> 0\) 的连边 \(s \to i\) ,权值 \(< 0\) 的连边 \(i \to t\) ,然后对于 ...
- 运行composer出现do not run Composer as root/super user!
curl -sS https://getcomposer.org/installer | php mv composer.phar /usr/local/bin/composer composer - ...
- 读书笔记 - 把时间当作朋友 by 李笑来
要管理的不是时间,而是自己. 摸着石头渐行渐远,最终也能过河.- 朱敏 赛伯乐(中国)投资公司 董事长 一切都靠积累,一切都可提前准备,越早醒悟越好.人的一生是奋斗的一生,但是有的人一生过得很伟大,有 ...
- 改变input[type=range]的样式 动态滑动
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- awk命令_Linux awk 命令用法详解
本文索引 awk命令格式和选项 awk模式和操作 模式 操作 awk脚本基本结构 awk的工作原理 awk内置变量(预定义变量) 将外部变量值传递给awk awk运算与判断 算术运算符 赋值运算符 逻 ...