强化学习 reinforcement learning: An Introduction 第一章, tic-and-toc 代码示例 (结构重建版,注释版)
强化学习入门最经典的数据估计就是那个大名鼎鼎的 reinforcement learning: An Introduction 了, 最近在看这本书,第一章中给出了一个例子用来说明什么是强化学习,那就是tic-and-toc游戏, 感觉这个名很不Chinese,感觉要是用中文来说应该叫三子棋啥的才形象。

这个例子就是下面,在一个3*3的格子里面双方轮流各执一色棋进行对弈,哪一方先把自方的棋子连成一条线则算赢,包括横竖一线,两个对角线斜连一条线。
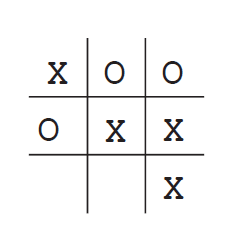

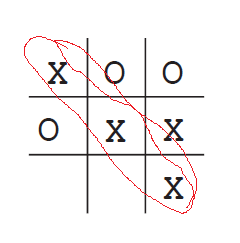
上图,则是 X 方赢,即:
reinforcement learning 的对应代码地址为:
https://github.com/ShangtongZhang/reinforcement-learning-an-introduction
该代码虽然很好,但是看起来较费力,于是自己就该它的基础上加了些注释并把结构进行了改动,具体代码如下:
源码地址:(本文给出的结构重建,注释版)
https://files.cnblogs.com/files/devilmaycry812839668/tic_tac_toe_code.zip
关于算法的解释可以具体参见书中的介绍,Reinforcement Learning:An Introduction 第一章
关于这个代码的,或者说是算法的设计主要是为了解释什么是时序差分的强化学习。
每一种状态都用一个值来表示,并用一个hash码表示,
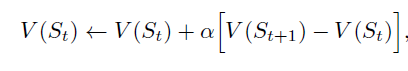
St 是此刻的棋盘状态值, St+1 是下一时刻的棋盘状态值。但是, 如果St状态到St+1 状态是因为自方进行策略探索而选择的不是最优的下一状态的动作,那么不进行此次计算。
状态值的变化树结构如下图:
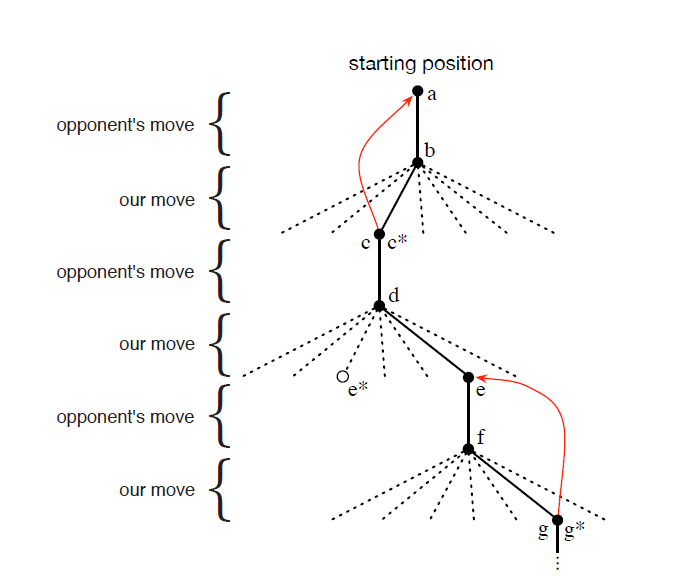
由 d 状态 到 e* 状态是此时可以选择的最优状态,但是我们选择了进入 e 状态的操作,这就是策略的探索操作。
具体的算法思想参照 reinforcement learning: An Introduction 原书。
==========================================================
目录结构如下图:

tic_tac_toe.py 是代码的主文件,需要运行该代码。
enviroment 文件夹中放的是 关于棋盘状态的类文件代码,和环境初始化的代码。

agents 文件夹中放的是 具体的下起策略中agent的代码:

interface.py 中的代码是 agent 代码和主程序的接口文件:
主文件 tic_toe_tac.py
强化学习 reinforcement learning: An Introduction 第一章, tic-and-toc 代码示例 (结构重建版,注释版)的更多相关文章
- 强化学习(Reinforcement Learning)中的Q-Learning、DQN,面试看这篇就够了!
1. 什么是强化学习 其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报. ...
- Learning From Data 第一章总结
之前上了台大的机器学习基石课程,里面用的教材是<Learning from data>,最近看了看觉得不错,打算深入看下去,内容上和台大的课程差不太多,但是有些点讲的更深入,想了解课程里面 ...
- 《Machine Learning》(第一章)序章
关键词:机器学习,基本术语,假设空间,归纳偏好,机器学习用途 一.机器学习概述 机器学习是一门从数据中,经过计算得到模型(Model)的一种过程,得到的模型不仅能反应出训练数据集中所蕴含的规律,并且能 ...
- 强化学习(Reinfment Learning) 简介
本文内容来自以下两个链接: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/ https: ...
- 【php学习】PHP 入门经典第一章笔记
第一章: php在线手册:http://php.net/manual/zh/index.php 在开始学习PHP之前,先来看一个合格的PHP程序员今后应具备哪些知识,这里只是笔者的一些总结,希望对读者 ...
- 《Deep Learning》译文 第一章 前言(中) 神经网络的变迁与称谓的更迭
转载请注明出处. 第一章 前言(中) 1.1 本书适合哪些人阅读? 能够说本书的受众目标比較广泛,可是本书可能更适合于例如以下的两类人群.一类是学习过与机器学习相关课程的大学生们(本科生或者研究生). ...
- Reinforcement Learning: An Introduction读书笔记(3)--finite MDPs
> 目 录 < Agent–Environment Interface Goals and Rewards Returns and Episodes Policies and Val ...
- 【java并发编程艺术学习】(二)第一章 java并发编程的挑战
章节介绍 主要介绍并发编程时间中可能遇到的问题,以及如何解决. 主要问题 1.上下文切换问题 时间片是cpu分配给每个线程的时间,时间片非常短. cpu通过时间片分配算法来循环执行任务,当前任务执行一 ...
- 《STL源码剖析》学习半生记:第一章小结与反思
不学STL,无以立.--陈轶阳 从1.1节到1.8节大部分都是从各方面介绍STL, 包括历史之类的(大致上是这样,因为实在看不下去我就直接略到了1.9节(其实还有一点1.8.3的内容)). 第一章里比 ...
随机推荐
- phpmyadmin 定位表
一个数据库,里面有几百个表.如何快速定位需要的表呢? 关键字查询,就好了! 很方便,很实用. 建表的时候,相关性比较强的,就用同一个前缀.
- stack_01
A.添加/移除 A.1.void stack::push(elemValue); // 栈头 添加元素 A.2.void stack::pop(); // 栈头 移除第一个元素 B.随机存取 C.数据 ...
- vs2010的VCVARS32.BAT所在位置
1. C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin\vcvars32.bat 2. ZC:vs08 和 vs2010 安装好后, ...
- AES SBox的构造(python)
几点需要注意的,求解逆元的时候使用的是拓展欧几里得,但是那些运算规则需要变一变,模2的加减乘除(或者可以理解为多项式的运算) 在进行字节的仿射变换不用进行矩阵的运算. 一个矩阵和一个列向量进行运算的时 ...
- Java基础九--抽象类
Java基础九--抽象类 一.抽象类介绍 /*抽象类:抽象:笼统,模糊,看不懂!不具体. 特点:1,方法只有声明没有实现时,该方法就是抽象方法,需要被abstract修饰. 抽象方法必须定义在抽象类中 ...
- English trip -- VC(情景课) 8 B job duties 工作职责
Vocabulary focus 核心词汇 She is a receptionist. She answers the phone. She is a cashier She counts mon ...
- mysql--------char 和 varchar 的区别
char是一种固定长度的类型,varchar则是一种可变长度的类型,它们的区别是: char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在 ...
- log4j配置文件位置详解
自动加载配置文件: (1)如果采用log4j输出日志,要对log4j加载配置文件的过程有所了解.log4j启动时,默认会寻找source folder下的log4j.xml配置文件,若没有,会寻找lo ...
- 开启turbine收集hystrix指标功能
使用turbine收集hystrix指标 1.pom中引入对turbin的依赖,并增加dashboard图形界面的展示 <dependencies> <dependency> ...
- [LeetCode] 29. Divide Two Integers(不使用乘除取模,求两数相除) ☆☆☆
转载:https://blog.csdn.net/Lynn_Baby/article/details/80624180 Given two integers dividend and divisor, ...