Logistic Regression--逻辑回归算法汇总**
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/18/2595410.html
转自别处 有很多与此类似的文章 也不知道谁是原创 因原文由少于错误 所以下文对此有修改并且做了适当的重点标记(横线见的内容没大明白 并且有些复杂,后面的运行流程依据前面的得出的算子进行分类)
初步接触
谓LR分类器(Logistic Regression Classifier),并没有什么神秘的。在分类的情形下,经过学习之后的LR分类器其实就是一组权值w0,w1,...,wm.
当测试样本集中的测试数据来到时,这一组权值按照与测试数据线性加和的方式,求出一个z值:
z = w0+w1*x1+w2*x2+...+wm*xm。 ① (其中x1,x2,...,xm是某样本数据的各个特征,维度为m)
之后按照sigmoid函数的形式求出:
σ(z) = 1 / (1+exp(z)) 。②
由于sigmoid函数的定义域是(-INF, +INF),而值域为(0, 1)。因此最基本的LR分类器适合于对两类目标进行分类。
那么LR分类器的这一组权值w0,w1,...,wm是如何求得的呢?这就需要涉及到极大似然估计MLE和优化算法的概念了。
我们将sigmoid函数看成样本数据的概率密度函数,每一个样本点,都可以通过上述的公式①和②计算出其概率密度
详细描述
1.逻辑回归模型
1.1逻辑回归模型
考虑具有p个独立变量的向量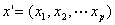 ,设条件概率
,设条件概率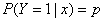 为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为
为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为
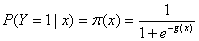 (1.1)
(1.1)
上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。

其中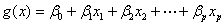 。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有
。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有
 (1.2)
(1.2)
定义不发生事件的条件概率为
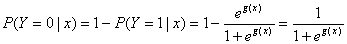 (1.3)
(1.3)
那么,事件发生与事件不发生的概率之比为
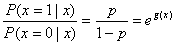 (1.4)
(1.4)
这个比值称为事件的发生比(the odds of experiencing an event),简称为odds。因为0<p<1,故odds>0。对odds取对数,即得到线性函数,
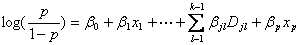 (1.5),
(1.5),
1.2极大似然函数
假设有n个观测样本,观测值分别为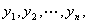 设
设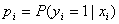 为给定条件下得到yi=1(原文
为给定条件下得到yi=1(原文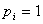 )的概率。在同样条件下得到yi=0(
)的概率。在同样条件下得到yi=0(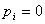 )的条件概率为
)的条件概率为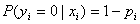 。于是,得到一个观测值的概率为
。于是,得到一个观测值的概率为
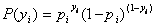 (1.6) -----此公式实际上是综合前两个等式得出,并无特别之处
(1.6) -----此公式实际上是综合前两个等式得出,并无特别之处
因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。
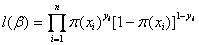
上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估计。于是,最大似然估计的关键就是求出参数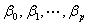 ,使上式取得最大值。
,使上式取得最大值。
对上述函数求对数
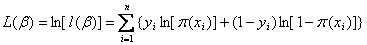 (1.8)
(1.8)
上式称为对数似然函数。为了估计能使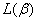 取得最大的参数
取得最大的参数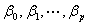 的值。
的值。
对此函数求导,得到p+1个似然方程。
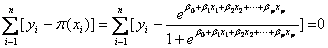 (1.9)
(1.9)
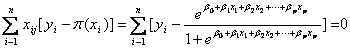 ,j=1,2,..,p.-----p为独立向量个数
,j=1,2,..,p.-----p为独立向量个数
上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森(Newton-Raphson)方法进行迭代求解。
1.3 牛顿-拉斐森迭代法
对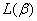 求二阶偏导数,即Hessian矩阵为
求二阶偏导数,即Hessian矩阵为
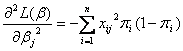
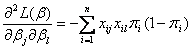 (1.10)
(1.10)
如果写成矩阵形式,以H表示Hessian矩阵,X表示
 (1.11)
(1.11)
令
 (1.12)
(1.12)
则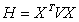 。再令
。再令 (注:前一个矩阵需转置),即似然方程的矩阵形式。
(注:前一个矩阵需转置),即似然方程的矩阵形式。
得牛顿迭代法的形式为
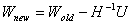 (1.13)
(1.13)
注意到上式中矩阵H为对称正定的,求解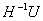 即为求解线性方程HX=U中的矩阵X。对H进行cholesky分解。
即为求解线性方程HX=U中的矩阵X。对H进行cholesky分解。
最大似然估计的渐近方差(asymptotic variance)和协方差(covariance)可以由信息矩阵(information matrix)的逆矩阵估计出来。而信息矩阵实际上是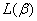 二阶导数的负值,表示为
二阶导数的负值,表示为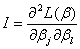 。估计值的方差和协方差表示为
。估计值的方差和协方差表示为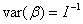 ,也就是说,估计值
,也就是说,估计值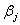 的方差为矩阵I的逆矩阵的对角线上的值,而估计值
的方差为矩阵I的逆矩阵的对角线上的值,而估计值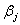 和
和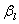 的协方差(和的协方差等于?不解。。。)为除了对角线以外的值。然而在多数情况,我们将使用估计值
的协方差(和的协方差等于?不解。。。)为除了对角线以外的值。然而在多数情况,我们将使用估计值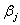 的标准方差,表示为
的标准方差,表示为
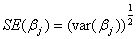 ,for j=0,1,2,…,p (1.14)
,for j=0,1,2,…,p (1.14)
-----------------------------------------------------------------------------------------------------------------------------------------------
2.显著性检验
下面讨论在逻辑回归模型中自变量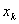 是否与反应变量显著相关的显著性检验。零假设
是否与反应变量显著相关的显著性检验。零假设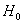 :
: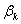 =0(表示自变量
=0(表示自变量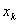 对事件发生可能性无影响作用)。如果零假设被拒绝,说明事件发生可能性依赖于
对事件发生可能性无影响作用)。如果零假设被拒绝,说明事件发生可能性依赖于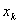 的变化。
的变化。
2.1 Wald test
对回归系数进行显著性检验时,通常使用Wald检验,其公式为
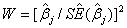 (2.1)
(2.1)
其中, 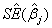 为
为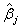 的标准误差。这个单变量Wald统计量服从自由度等于1的
的标准误差。这个单变量Wald统计量服从自由度等于1的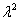 分布。
分布。
如果需要检验假设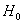 :
: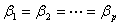 =0,计算统计量
=0,计算统计量
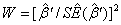 (2.2)
(2.2)
其中,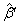 为去掉
为去掉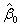 所在的行和列的估计值,相应地,
所在的行和列的估计值,相应地,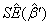 为去掉
为去掉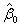 所在的行和列的标准误差。这里,Wald统计量服从自由度等于p的
所在的行和列的标准误差。这里,Wald统计量服从自由度等于p的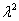 分布。如果将上式写成矩阵形式,有
分布。如果将上式写成矩阵形式,有
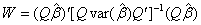 (2.3)
(2.3)
矩阵Q是第一列为零的一常数矩阵。例如,如果检验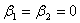 ,则
,则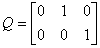 。
。
然而当回归系数的绝对值很大时,这一系数的估计标准误就会膨胀,于是会导致Wald统计值变得很小,以致第二类错误的概率增加。也就是说,在实际上会导致应该拒绝零假设时却未能拒绝。所以当发现回归系数的绝对值很大时,就不再用Wald统计值来检验零假设,而应该使用似然比检验来代替。
2.2 似然比(Likelihood ratio test)检验
在一个模型里面,含有变量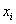 与不含变量
与不含变量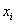 的对数似然值乘以-2的结果之差,服从
的对数似然值乘以-2的结果之差,服从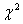 分布。这一检验统计量称为似然比(likelihood ratio),用式子表示为
分布。这一检验统计量称为似然比(likelihood ratio),用式子表示为
 (2.4)
(2.4)
计算似然值采用公式(1.8)。
倘若需要检验假设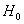 :
: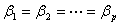 =0,计算统计量
=0,计算统计量
 (2.5)
(2.5)
式中,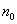 表示
表示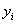 =0的观测值的个数,而
=0的观测值的个数,而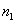 表示
表示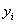 =1的观测值的个数,那么n就表示所有观测值的个数了。实际上,上式的右端的右半部分
=1的观测值的个数,那么n就表示所有观测值的个数了。实际上,上式的右端的右半部分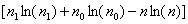 表示只含有
表示只含有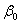 的似然值。统计量G服从自由度为p的
的似然值。统计量G服从自由度为p的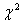 分布
分布
2.3 Score检验
在零假设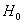 :
: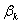 =0下,设参数的估计值为
=0下,设参数的估计值为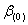 ,即对应的
,即对应的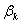 =0。计算Score统计量的公式为
=0。计算Score统计量的公式为
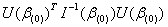 (2.6)
(2.6)
上式中,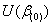 表示在
表示在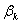 =0下的对数似然函数(1.9)的一价偏导数值,而
=0下的对数似然函数(1.9)的一价偏导数值,而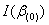 表示在
表示在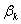 =0下的对数似然函数(1.9)的二价偏导数值。Score统计量服从自由度等于1的
=0下的对数似然函数(1.9)的二价偏导数值。Score统计量服从自由度等于1的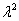 分布。
分布。
2.4 模型拟合信息
模型建立后,考虑和比较模型的拟合程度。有三个度量值可作为拟合的判断根据。
(1)-2LogLikelihood
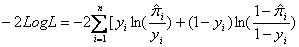 (2.7)
(2.7)
(2) Akaike信息准则(Akaike Information Criterion,简写为AIC)
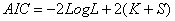 (2.8)
(2.8)
其中K为模型中自变量的数目,S为反应变量类别总数减1,对于逻辑回归有S=2-1=1。-2LogL的值域为0至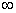 ,其值越小说明拟合越好。当模型中的参数数量越大时,似然值也就越大,-2LogL就变小。因此,将2(K+S)加到AIC公式中以抵销参数数量产生的影响。在其它条件不变的情况下,较小的AIC值表示拟合模型较好。
,其值越小说明拟合越好。当模型中的参数数量越大时,似然值也就越大,-2LogL就变小。因此,将2(K+S)加到AIC公式中以抵销参数数量产生的影响。在其它条件不变的情况下,较小的AIC值表示拟合模型较好。
(3)Schwarz准则
这一指标根据自变量数目和观测数量对-2LogL值进行另外一种调整。SC指标的定义为
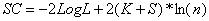 (2.9)
(2.9)
其中ln(n)是观测数量的自然对数。这一指标只能用于比较对同一数据所设的不同模型。在其它条件相同时,一个模型的AIC或SC值越小说明模型拟合越好。
3.回归系数解释
3.1发生比
odds=[p/(1-p)]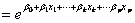 ,即事件发生的概率与不发生的概率之比。而发生比率(odds ration),即
,即事件发生的概率与不发生的概率之比。而发生比率(odds ration),即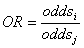
(1)连续自变量。对于自变量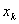 ,每增加一个单位,odds ration为
,每增加一个单位,odds ration为
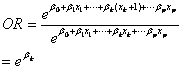 (3.1)
(3.1)
(2)二分类自变量的发生比率。变量的取值只能为0或1,称为dummy variable。当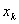 取值为1,对于取值为0的发生比率为
取值为1,对于取值为0的发生比率为
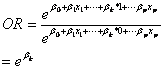 (3.2)
(3.2)
亦即对应系数的幂。
(3)分类自变量的发生比率。
如果一个分类变量包括m个类别,需要建立的dummy variable的个数为m-1,所省略的那个类别称作参照类(reference category)。设dummy variable为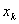 ,其系数为
,其系数为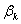 ,对于参照类,其发生比率为
,对于参照类,其发生比率为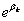 。
。
3.2 逻辑回归系数的置信区间
对于置信度1-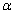 ,参数
,参数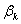 的100%(1-
的100%(1-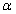 )的置信区间为
)的置信区间为
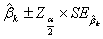 (3.3)
(3.3)
上式中,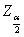 为与正态曲线下的临界Z值(critical value),
为与正态曲线下的临界Z值(critical value), 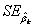 为系数估计
为系数估计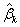 的标准误差,
的标准误差,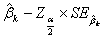 和
和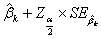 两值便分别是置信区间的下限和上限。当样本较大时,
两值便分别是置信区间的下限和上限。当样本较大时,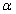 =0.05水平的系数
=0.05水平的系数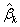 的95%置信区间为
的95%置信区间为
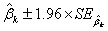 (3.4)
(3.4)
-----------------------------------------------------------------------------------------------------------------------------------------------
4.变量选择
4.1前向选择(forward selection):在截距模型的基础上,将符合所定显著水平的自变量一次一个地加入模型。
具体选择程序如下
(1) 常数(即截距)进入模型。
(2) 根据公式(2.6)计算待进入模型变量的Score检验值,并得到相应的P值。
(3) 找出最小的p值,如果此p值小于显著性水平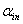 ,则此变量进入模型。如果此变量是某个名义变量的单面化(dummy)变量,则此名义变量的其它单面化变理同时也进入模型。不然,表明没有变量可被选入模型。选择过程终止。
,则此变量进入模型。如果此变量是某个名义变量的单面化(dummy)变量,则此名义变量的其它单面化变理同时也进入模型。不然,表明没有变量可被选入模型。选择过程终止。
(4) 回到(2)继续下一次选择。
4.2 后向选择(backward selection):在模型包括所有候选变量的基础上,将不符合保留要求显著水平的自变量一次一个地删除。
具体选择程序如下
(1) 所有变量进入模型。
(2) 根据公式(2.1)计算所有变量的Wald检验值,并得到相应的p值。
(3) 找出其中最大的p值,如果此P值大于显著性水平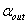 ,则此变量被剔除。对于某个名义变量的单面化变量,其最小p值大于显著性水平
,则此变量被剔除。对于某个名义变量的单面化变量,其最小p值大于显著性水平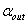 ,则此名义变量的其它单面化变量也被删除。不然,表明没有变量可被剔除,选择过程终止。
,则此名义变量的其它单面化变量也被删除。不然,表明没有变量可被剔除,选择过程终止。
(4) 回到(2)进行下一轮剔除。
4.3逐步回归(stepwise selection)
(1)基本思想:逐个引入自变量。每次引入对Y影响最显著的自变量,并对方程中的老变量逐个进行检验,把变为不显著的变量逐个从方程中剔除掉,最终得到的方程中既不漏掉对Y影响显著的变量,又不包含对Y影响不显著的变量。
(2)筛选的步骤:首先给出引入变量的显著性水平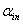 和剔除变量的显著性水平
和剔除变量的显著性水平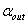 ,然后按下图筛选变量。
,然后按下图筛选变量。

(3)逐步筛选法的基本步骤
逐步筛选变量的过程主要包括两个基本步骤:一是从不在方程中的变量考虑引入新变量的步骤;二是从回归方程中考虑剔除不显著变量的步骤。
假设有p个需要考虑引入回归方程的自变量.
① 设仅有截距项的最大似然估计值为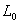 。对p个自变量每个分别计算Score检验值,
。对p个自变量每个分别计算Score检验值,
设有最小p值的变量为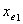 ,且有
,且有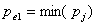 ,对于单面化(dummy)变量,也如此。若
,对于单面化(dummy)变量,也如此。若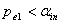 ,则此变量进入模型,不然停止。如果此变量是名义变量单面化(dummy)的变量,则此名义变量的其它单面化变量也进入模型。其中
,则此变量进入模型,不然停止。如果此变量是名义变量单面化(dummy)的变量,则此名义变量的其它单面化变量也进入模型。其中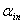 为引入变量的显著性水平。
为引入变量的显著性水平。
② 为了确定当变量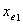 在模型中时其它p-1个变量也是否重要,将
在模型中时其它p-1个变量也是否重要,将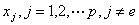 分别与
分别与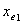 进行拟合。对p-1个变量分别计算Score检验值,其p值设为
进行拟合。对p-1个变量分别计算Score检验值,其p值设为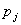 。设有最小p值的变量为
。设有最小p值的变量为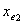 ,且有
,且有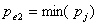 .若
.若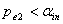 ,则进入下一步,不然停止。对于单面化变量,其方式如同上步。
,则进入下一步,不然停止。对于单面化变量,其方式如同上步。
③ 此步开始于模型中已含有变量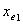 与
与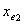 。注意到有可能在变量
。注意到有可能在变量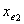 被引入后,变量
被引入后,变量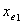 不再重要。本步包括向后删除。根据(2.1)计算变量
不再重要。本步包括向后删除。根据(2.1)计算变量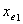 与
与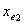 的Wald检验值,和相应的p值。设
的Wald检验值,和相应的p值。设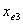 为具有最大p值的变量,即
为具有最大p值的变量,即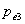 =max(
=max(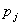 ),
),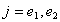 .如果此p值大于
.如果此p值大于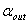 ,则此变量从模型中被删除,不然停止。对于名义变量,如果某个单面化变量的最小p值大于
,则此变量从模型中被删除,不然停止。对于名义变量,如果某个单面化变量的最小p值大于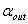 ,则此名义变量从模型中被删除。
,则此名义变量从模型中被删除。
④ 如此进行下去,每当向前选择一个变量进入后,都进行向后删除的检查。循环终止的条件是:所有的p个变量都进入模型中或者模型中的变量的p值小于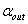 ,不包含在模型中的变量的p值大于
,不包含在模型中的变量的p值大于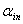 。或者某个变量进入模型后,在下一步又被删除,形成循环。
。或者某个变量进入模型后,在下一步又被删除,形成循环。
Logistic Regression--逻辑回归算法汇总**的更多相关文章
- Coursera DeepLearning.ai Logistic Regression逻辑回归总结
既<Machine Learning>课程后,Andrew Ng又推出了新一系列的课程<DeepLearning.ai>,注册了一下可以试听7天.之后每个月要$49,想想还是有 ...
- Logistic Regression(逻辑回归)
分类是机器学习的一个基本问题, 基本原则就是将某个待分类的事情根据其不同特征划分为两类. Email: 垃圾邮件/正常邮件 肿瘤: 良性/恶性 蔬菜: 有机/普通 对于分类问题, 其结果 y∈{0,1 ...
- Logistic Regression逻辑回归
参考自: http://blog.sina.com.cn/s/blog_74cf26810100ypzf.html http://blog.sina.com.cn/s/blog_64ecfc2f010 ...
- Logistic Regression(逻辑回归)(二)—深入理解
(整理自AndrewNG的课件,转载请注明.整理者:华科小涛@http://www.cnblogs.com/hust-ghtao/) 上一篇讲解了Logistic Regression的基础知识,感觉 ...
- 机器学习简要笔记(五)——Logistic Regression(逻辑回归)
1.Logistic回归的本质 逻辑回归是假设数据服从伯努利分布,通过极大似然函数的方法,运用梯度上升/下降法来求解参数,从而实现数据的二分类. 1.1.逻辑回归的基本假设 ①伯努利分布:以抛硬币为例 ...
- Deep Learning 学习笔记(4):Logistic Regression 逻辑回归
逻辑回归主要用于解决分类问题,在现实中有更多的运用, 正常邮件or垃圾邮件 车or行人 涨价or不涨价 用我们EE的例子就是: 高电平or低电平 同时逻辑回归也是后面神经网络到深度学习的基础. (原来 ...
- 【原】Coursera—Andrew Ng机器学习—Week 3 习题—Logistic Regression 逻辑回归
课上习题 [1]线性回归 Answer: D A 特征缩放不起作用,B for all 不对,C zero error不对 [2]概率 Answer:A [3]预测图形 Answer:A 5 - x1 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 6_Logistic Regression 逻辑回归
Lecture6 Logistic Regression 逻辑回归 6.1 分类问题 Classification6.2 假设表示 Hypothesis Representation6.3 决策边界 ...
- SparkMLlib学习分类算法之逻辑回归算法
SparkMLlib学习分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693 ...
随机推荐
- JDK 动态代理的简单理解
动态代理 代理模式是 Java 中的常用设计模式,代理类通过调用被代理类的相关方法,提供预处理.过滤.事后处理等服务,动态代理及通过反射机制动态实现代理机制.JDK 中的 java.lang.refl ...
- 在fork的项目里同步别人新增分支的方法
# 1.将项目B clone 到本地 git clone -b master 项目B的git地址 # 2.将项目A的git地址,添加至本地的remote git remote add upstream ...
- 使用 IntraWeb (25) - 基本控件之 TIWRegion
这应该是 IW 中最重要的容器了, 和它同父的还有 TIWTabControl TIWRegion 所在单元及继承链: IWRegion.TIWRegion 主要成员: property Align: ...
- Either, neither, both
http://speakspeak.com/resources/english-grammar-rules/various-grammar-rules/either-neither-both One ...
- LINUX 内核守护进程
http://alfred-sun.github.io/blog/2015/06/18/daemon-implementation/
- Android自己定义控件系列二:自己定义开关button(一)
这一次我们将会实现一个完整纯粹的自己定义控件,而不是像之前的组合控件一样.拿系统的控件来实现.计划分为三部分:自己定义控件的基本部分,自己定义控件的触摸事件的处理和自己定义控件的自己定义属性: 以下就 ...
- [EF]数据上下文该如何实例化?
摘要 之前使用过一段Nhibernate,最近在尝试EF做项目,但对DbContext的实例化,有点困惑,发现和Nhibernate有不同.这里将查找的例子,在这里列举一下. 资料 在EntityFr ...
- .NET中常见的内存泄漏和解决办法
在.NET中,虽然CLR的GC垃圾回收器帮我们自动回收托管堆对象,释放内存,最大程度避免了"内存泄漏"(应用程序所占用的内存没有得到及时释放),但.NET应用程序"内存泄 ...
- 【JVM】linux上tomcat中部署的web服务,时好时坏,莫名其妙宕机,报错:There is insufficient memory for the Java Runtime Environment to continue.
=========================================================================================== 环境: linu ...
- 关于spring session redis共享session的跨子域的处理
安装完redis, spring端只要下面这两个bean配置上就可以用了 <?xml version="1.0" encoding="UTF-8"?> ...