Apache Hadoop下一代MapReduce框架(YARN)简介 (Apache Hadoop NextGen MapReduce (YARN))
英文看着头大,先试着翻译一下。
E文原文:http://archive.cloudera.com/cdh5/cdh/5/hadoop/hadoop-yarn/hadoop-yarn-site/YARN.html
翻译真是太难了,而且我翻译的好烂,好烂,有时候自己也只能理解个大概。
====================================begin====================================
MapReduce在hadoop-0.2.3中发生了很大的变化,现在是MapReduce 2.0,又称为YARN。
MRv2的基本思想是将JobTracker的两个主要功能:资源管理和作业调度/监控分割成单独的守护进程。
我们是这样做的:有一个全局的ResourceManager ( RM),每个应用程序都有一个ApplicationMaster ( AM ) 。一个应用程序既可以是单个的传统意义上的Map-Reduce作业,也可以是单个DAG作业。
数据的计算框架由ResourceManager,每个节点的从站,节点管理器( NM )组成。 ResourceManager是仲裁系统中的所有应用程序的资源的最终者。
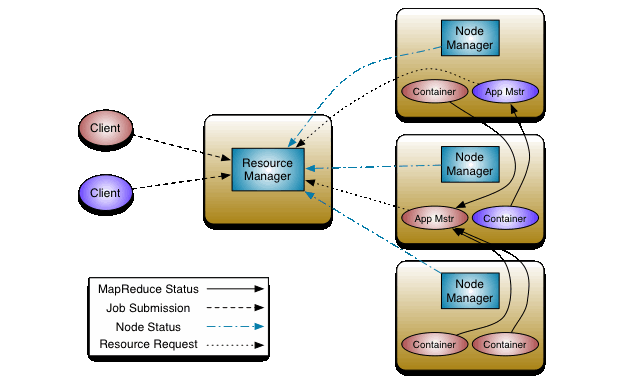
ResourceManager中有两个主要组件:Scheduler 和ApplicationsManager 。
Scheduler因为了解容量的限制,队列等,所以负责分配资源至各运行中的应用程序。Scheduler是纯粹的调度程序,它不执行任何监视或跟踪状态的应用程序。此外,它不保证会重新启动失败的任务,无论是因为应用程序错误还是因为硬件故障所导致的。Scheduler履行其调度的功能,对于应用程序的资源需求,它基于抽象出的资源容器的概念,如内存,CPU ,磁盘,网络等等的组合。在第一个版本,它仅仅支持内存。Scheduler有一个可插拔的插件策略,它负责在各种不同的队列,应用程序等中分配群集的资源,比如当前的Map-Reduce调度器中的CapacityScheduler和FairScheduler。
CapacityScheduler支持层次化队列,以允许更多的可预见的共享群集资源。
ApplicationsManager负责接受作业提交,协商用于执行该应用程序特定的ApplicationMaster并提供用于重启因ApplicationMaster容器失败的服务的第一容器。
NodeManager是每台机器的计算框架的代理,它负责容器,监控他们的资源使用情况(CPU ,内存,磁盘,网络)并报告到ResourceManager/Scheduler。
每个应用程序的ApplicationMaster负责从Scheduler协商恰当的资源容器,跟踪他们的状态和监控进程。
MRV2保持与以前的稳定版本(的hadoop - 0.20.205 )API的兼容性 。这意味着所有的Map-Reduce作业只需重新编译一下就可以在MRv2上运行。
=========================================over====================================================
Apache Hadoop下一代MapReduce框架(YARN)简介 (Apache Hadoop NextGen MapReduce (YARN))的更多相关文章
- 更快、更强——解析Hadoop新一代MapReduce框架Yarn(CSDN)
摘要:本文介绍了Hadoop 自0.23.0版本后新的MapReduce框架(Yarn)原理.优势.运作机制和配置方法等:着重介绍新的Yarn框架相对于原框架的差异及改进. 编者按:对于业界的大数据存 ...
- Hadoop 之 MapReduce 框架演变详解
经典版的MapReduce 所谓的经典版本的MapReduce框架,也是Hadoop第一版成熟的商用框架,简单易用是它的特点,来看一幅图架构图: 上面的这幅图我们暂且可以称谓Hadoop的V1.0版本 ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- mapreduce框架详解【转载】
[本文转载自:http://www.cnblogs.com/sharpxiajun/p/3151395.html] 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoo ...
- mapreduce框架详解
hadoop 学习笔记:mapreduce框架详解 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感 ...
- 【原创 Hadoop&Spark 动手实践 3】Hadoop2.7.3 MapReduce理论与动手实践
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 下一代Apache Hadoop MapReduce框架的架构
背景 随着集群规模和负载增加,MapReduce JobTracker在内存消耗,线程模型和扩展性/可靠性/性能方面暴露出了缺点,为此需要对它进行大整修. 需求 当我们对Hadoop MapReduc ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
随机推荐
- java zxing生成二维码
package zxing.test; import com.google.zxing.BarcodeFormat; import com.google.zxing.EncodeHintType; i ...
- 转:初探nginx架构(一)
来源:http://tengine.taobao.org/book/chapter_02.html 众所周知,nginx性能高,而nginx的高性能与其架构是分不开的.那么nginx究竟是怎么样的呢? ...
- WireShark开启IP, TCP,UDP校验和的办法
首先点击编辑->首选项
- 使用Repository Creation Utility创建档案库并连接
使用Repository Creation Utility创建档案库 档案库创建方式 1. 使用Repository Creation Utility创建 1.1使用下载的RCU http://www ...
- Xamarin.Android之ListView和Adapter
一.前言 如今不管任何应用都能够看到列表的存在,而本章我们将学习如何使用Xamarin去实现它,以及如何使用适配器和自定义适配器(本文中的适配器的主要内容就是将原始的数据转换成了能够供列表控件显示的项 ...
- Quartz.NET开源作业调度框架系列(四):Plugin Job-转
如果在Quartz.NET作业运行时我们想动态修改Job和Trigger的绑定关系,同时修改一些参数那么该怎么办呢?Quartz.NET提供了插件技术,可以通过在XML文件中对Job和Trigger的 ...
- MyChatRoom——C#自制聊天室
一个用C#编写的基于Socket的Windows版聊天室,包括服务端和客户端.当服务端启动服务后,客户端可以连接到服务端,给服务端发送数据,服务端可以接收数据:服务端可以给客户端发送数据,客户端接收: ...
- 【TP3.2】TP3.2的 FIND_IN_SET()的用法
1.mysql的find_in_set 用法我这里就不介绍了,很好用的一个方法. 2.TP3.2使用: $where['_string'] = 'FIND_IN_SET('."'$id'&q ...
- 【Algorithm】回溯法与深度优先遍历的异同
1.相同点: 回溯法在实现上也是遵循深度优先的,即一步一步往前探索,而不像广度优先那样,由近及远一片一片地扫. 2.不同点 (1)访问序 深度优先遍历: 目的是“遍历”,本质是无序的.也就是说访问次序 ...
- NFS安装及优化过程--centos6.6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 3 ...