python拓展3 常用算法
知识内容:
1.递归复习
2.算法基础概念
3.查找与排序
参考资料:
http://python3-cookbook.readthedocs.io/zh_CN/latest/index.html
http://www.cnblogs.com/alex3714/articles/5474411.html
关于时间复杂度:http://www.cnblogs.com/alex3714/articles/5910253.html
关于递归:http://www.cnblogs.com/alex3714/articles/8955091.html
一、递归复习
1.什么是递归:函数内部自己调用自己
2.递归的特点
- 必须有一个明确的结束条件
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 递归效率不高,递归层次过多会导致栈溢出
3.看函数说结果
def func1(x):
print(x)
func1(x-1)
func1(5)
# 一直打印到限制次数(无出口) def func2(x):
if x > 0:
print(x)
func2(x+1)
func2(5)
# 一直打印到限制次数(无出口) def func3(x):
if x > 0:
print(x)
func3(x-1)
func3(5)
# 从5打印到1 def func4(x):
if x > 0:
func4(x-1)
print(x)
func4(5)
# 从1打印到5
4.经典递归
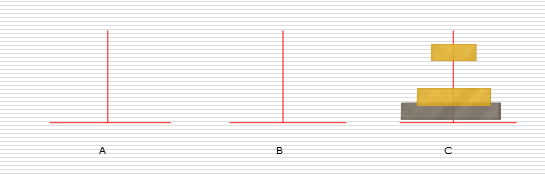
(1)汉诺塔问题
解决思路:
假设有n个盘子:
- 1.把n-1个圆盘从A经过C移动到B
- 2.把第n个圆盘从A移动到C
- 3.把n-1个小圆盘从B经过A移动到C
1:
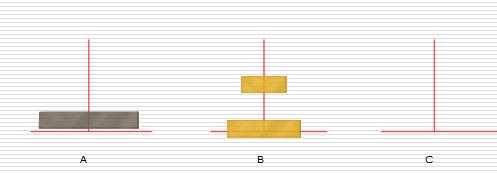
2:
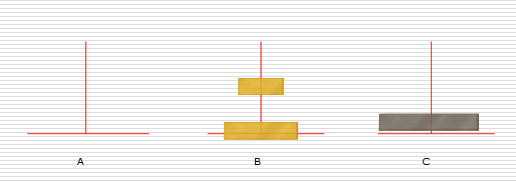
3:
代码:
def hanoi(a, b, c, n):
if n == 1:
print(a, "->", c) # 将n-1个盘子从a经过c移动到b
else:
hanoi(a, c, b, n-1) # 将剩余的最后一个盘子从a移动到c
print(a, "->", c)
hanoi(b, a, c, n-1) # 将n-1个盘子从b经过a移动到c hanoi('柱子a', '柱子b', '柱子c', 4)
总结:汉诺塔移动次数的递推式:h(x)=2h(x-1)+1
(2)字符串逆序输出
def rvs(s):
if s == "":
return s
else:
return rvs(s[1:]) + s[0] s = rvs("Hello, Python")
print(s)
5.尾递归
定义:当递归调用是整个函数体中最后执行的语句且返回值不属于表达式的一部分时,这个递归调用就是尾递归。尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码。
原理:当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
尾递归实例:
def calc(n):
print(n - 1)
if n > -50:
return calc(n-1)
二、算法基础概念
1.什么是算法
算法就是一个计算过程,解决问题的方法
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量
一个算法应该具有以下七个重要的特征:
- 有穷性(Finiteness):算法的有穷性是指算法必须能在执行有限个步骤之后终止
- 确切性(Definiteness):算法的每一步骤必须有确切的定义
- 输入项(Input):一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输 入是指算法本身定出了初始条件
- 输出项(Output):一个算法有一个或多个输出,以反映对输入数据加工后的结果。没 有输出的算法是毫无意义的
- 可行性(Effectiveness):算法中执行的任何计算步骤都是可以被分解为基本的可执行 的操作步,即每个计算步都可以在有限时间内完成(也称之为有效性)
- 高效性(High efficiency):执行速度快,占用资源少
- 健壮性(Robustness):对数据响应正确
2.时间复杂度及空间复杂度
(1)时间复杂度
print("hello, world")
for i in range(n):
print("hello, world")
for i in range(n):
for j in range(n):
print("hello, world")
for i in range(n):
for j in range(n):
for k in range(n):
print("hello, world")
问以上代码的运行时间谁最短?用什么方法来提现代码(算法)的运行快慢呢?答案就是用时间复杂度来衡量
常见算法的时间复杂度(由小到大排列):O(1) O(logn) O(n) O(nlogn) O(n^2) O(n^2logn) O(n^3)
实例:
print('hello world')
print('hello python') # O(1) 大O,可以认为它的含义是“order of”(大约是)
n= 64
while n>1:
print(n) # O(logn) # n=64是输出依次为: 64 32 16 8 4 2
n = n//2
for i in range(n):
print(i) # O(n)
for i in range(n):
for j in range(n):
print('hello world') # O(n^2)
for i in range(n):
for j in range(n):
for k in range(n):
print('hello world') # O(n^3)
注:切片的复杂度是O(n) ,因为切的时候是赋值
总结:
- 时间复杂度是用来估计算法运行时间的一个式子(单位)
- 一般来说,时间复杂度高的算法比算法时间复杂度低的算法慢
- 循环减半的过程就是O(logn),几次循环就是n的几次方的复杂度
(2)空间复杂度
空间复杂度是用来评估算法内存占用大小的一个式子,常见的空间复杂度:O(1) O(n) O(n^2)
空间换时间:计算机的资源很充足,可以用空间的消耗来换取一定的时间
三、查找与排序
1.常用查找
(1)列表查找
列表查找:从列表中查找指定元素
输入:列表、待查找的元素,输出:元素下标或未查找到元素
列表查找的方法:顺序查找和二分查找
- 顺序查找:从列表第一个元素开始,顺序进行搜索直到找到为止
- 二分查找:从有序列表的后续区开始查找,通过对查找的值和候选区中间的值进行比较,使候选区减半(二分查找的列表必须有序!)
以上两种查找的代码如下:
# 顺序查找 时间复杂 O(n)
def linear_search(find, data_list):
for i in range(len(data_list)):
if data_list[i] == find:
return i
return -1 # 二分查找 时间复杂 O(logn)
def binary_search(find, data_list):
low = 0
high = len(data_list)
while low <= high:
mid = (low + high) // 2
# 找到find
if data_list[mid] == find:
return mid
# find在左半边
elif data_list[mid] > find:
high = mid - 1
# find在右半边
else:
low = mid + 1
# 未找到find返回-1
return -1
(2)查找练习
现在有一个学员信息列表(按id增序排列),格式为:
[
{"id": 1001, "name": "张三", "age": 20},
{"id": 1002, "name": "woz", "age": 22},
{"id": 1003, "name": "alex", "age": 23},
{"id": 1004, "name": "hf", "age": 26},
{"id": 1005, "name": "kk", "age": 27},
]
现在要求修改二分查找代码,输入学生id,输出该学生在该列表下的下标并输出完整的学生信息
实现代码如下:
import random
stu_info = [] # 存储学生信息的列表 # 随机生成n个数据
def random_list(n):
ids = list(range(1001, 1001+n))
n1 = ["王", "赵", "李", "孙", "钱", "曾"]
n2 = ["浩", "杰", "丽", "", ""]
n3 = ['强', '国', "兰"]
for i in range(n):
stu_age = random.randint(20, 30)
stu_id = ids[i]
stu_name = random.choice(n1)+random.choice(n2)+random.choice(n3)
stu_info.append({"id": stu_id, "age": stu_age, "name":stu_name}) # 二分查找
def bin_search(data_set, find):
low = 0
high = len(data_set) - 1
while low <= high:
mid = (low+high)//2
if data_set[mid]["id"] == find:
return mid
elif data_set[mid]["id"] < find:
low = mid + 1
else:
high = mid - 1
return -1 # 搜索信息
def search_info(info, find):
res = bin_search(info, find)
if res == -1:
print("没有找到")
else:
print(info[res]) random_list(15)
print("以下是所有学生的id信息: ")
# print(stu_info)
for item in stu_info:
print(item["id"], end=" ")
sid = int(input("\n请输入你想要查找的学生的id: ").strip())
search_info(stu_info, sid)
2.常用排序
常用的排序有以下几种:

(1)排序:将无序序列变为有序序列
输入:无序序列,输出:有序序列
(2)应用场景
- 各种榜单
- 各种表格
- 给二分查找用
- 给其他算法用
(3)冒泡排序、选择排序、插入排序(必须背下来)
算法关键点:无序区和有序区
冒泡排序
思路:首先,列表每两个相邻的数比较大小,如果前边的比后边的大那么这两个数就互换位置,另外冒泡排序的排序趟数为n-1
# 冒泡排序:
import random def bubble_sort(s):
for i in range(len(s)-1):
for j in range(len(s)-i-1):
if s[j] > s[j+1]:
s[j], s[j+1] = s[j+1], s[j] data = list(range(100))
random.shuffle(data) # 打乱列表中的数
print(data)
bubble_sort(data) # 冒泡排序
print(data)
# 冒泡排序优化: 如果冒泡排序中执行一趟而没有发生交互,则列表已经是有序状态,可以直接结束算法
import random def bubble_sort(s):
for i in range(len(s)-1):
exchange = False
for j in range(len(s)-i-1):
if s[j] > s[j+1]:
s[j], s[j+1] = s[j+1], s[j]
exchange = True
if not exchange:
break data = list(range(100))
random.shuffle(data) # 打乱列表中的数
print(data)
bubble_sort(data) # 冒泡排序
print(data)
选择排序
思路: 一趟遍历完记录最小的数,放到第一个位置;在一趟遍历记录剩余列表中的最小的数,继续放置,那么怎么选最小的数?
每次假设最开始的为最小的数,然后从左至右扫描序列,记下最小值的位置。另外选择排序和冒泡排序一样也是n-1趟
# 选择排序:
import random def select_sort(s):
for i in range(len(s)-1):
min_locate = i # 每次的开始以第一个为最小值
for j in range(i+1, len(s)):
if s[j] < s[min_locate]: # 两数比较,如果另外一个数比最小值小,说明这个数为最小值
min_locate = j
s[i], s[min_locate] = s[min_locate], s[i] data = list(range(100))
random.shuffle(data) # 打乱列表中的数
print(data)
select_sort(data) # 选择排序
print(data)
插入排序
思路:元素被分为有序区和无序区两部分。最初有序区只有一个元素。每次从无序区中选择一个元素,插入到有序区的位置,直到无序区变空
# 插入排序:
import random def insert_sort(s):
for i in range(1, len(s)): # i 表示无序区的第一个数
tmp = s[i] # 要插入有序区的数
j = i - 1 # 指向有序区最后一个位置
while s[j] > tmp and j >= 0:
# 循环终止条件 li[j]<=tmp or j==-1
s[j + 1] = s[j] # 向后移动
j -= 1
s[j + 1] = tmp data = list(range(100))
random.shuffle(data) # 打乱列表中的数据
print(data)
insert_sort(data) # 插入排序
print(data)
注:冒泡排序、选择排序、插入排序的时间复杂度均为O(n^2)
(4)快速排序、堆排序、归并排序(排序NB三人组)
快速排序
# encoding: utf-8
# __author__ = "wyb"
# date: 2018/9/26 def quick_sort(data, left, right):
if left < right:
mid = partition(data, left, right)
quick_sort(data, left, mid-1)
quick_sort(data, mid+1, right) def partition(data, left, right):
tmp = data[left]
while left < right:
while left < right and data[right] >= tmp:
right -= 1
data[left] = data[right]
while left < right and data[left] <= tmp:
left += 1
data[right] = data[left]
data[left] = tmp
return left data = list(range(10))
quick_sort(data, 0, len(data)-1)
print(data)
注:快速排序一般时间复杂度为O(nlogn),最好复杂度为O(nlogn),最坏复杂度为O(n*n)
堆排序
关于堆排序:
堆排序实质上是利用了二叉树
实质上在工程中二叉树利用数组结构存储,抽象存储原理如下:
二叉树可以转换成数组: 节点i的左右孩子分别是2*i+1和2*i+2 节点i的父节点是(i-1)/2 大根堆和小根堆:
大根堆: 树的任何一个子树的最大值是这颗子树的顶部
小根堆: 树的任何一个子树的最小值是这颗子树的顶部 堆排序过程:
堆排序实际上就是利用堆结构的排序
建立一个大根堆(复杂度为O(n)) -> 使用heapInsert插入数
然后把大根堆第一个数和最后一个数替换 拿出这个元素把堆的size-1 然后使用heapify对堆进行调整 去掉堆顶的最大数或最小数:
把堆顶(第一个元素)和最后一个元素交换,拿出这个元素然后把堆的size-1,然后对堆顶进行hapify调整 优先级队列结构其实就是堆结构
def sift(data, low, high):
i = low
j = 2 * i + 1
tmp = data[i]
while j <= high: # 没到子树的最下边
if j + 1 <= high and data[j] < data[j+1]: # 如果有右孩子且比左孩子大
j += 1 # j指向右孩子
if data[j] > tmp: # 孩子比最高领导大
data[i] = data[j] # 孩子填到父亲的空位上
i = j # 孩子成为新父亲
j = 2 * i +1 # 新孩子
else:
break
data[i] = tmp # 最高领导放到父亲位置 def heap_sort(data):
n = len(data)
for i in range(n // 2 - 1, -1, -1):
sift(data, i, n - 1)
#堆建好了
for i in range(n-1, -1, -1): # i指向堆的最后
data[0], data[i] = data[i], data[0] # 领导退休,刁民上位
sift(data, 0, i - 1) # 调整出新领导
归并排序
def merge(a, b):
c = []
h = j = 0
while j < len(a) and h < len(b):
if a[j] < b[h]:
c.append(a[j])
j += 1
else:
c.append(b[h])
h += 1 if j == len(a):
for i in b[h:]:
c.append(i)
else:
for i in a[j:]:
c.append(i) return c def merge_sort(lists):
if len(lists) <= 1:
return lists
middle = len(lists)/2
left = merge_sort(lists[:middle])
right = merge_sort(lists[middle:])
return merge(left, right)
(5)没什么人用的排序(基数排序、希尔排序、桶排序)
这三种都是比较少用到的算法(了解即可)
- 桶排序: 时间复杂度O(N) 额外空间复杂度O(N)
- 计数排序: 时间复杂度O(N) 额外空间复杂度O(N)
- 基数排序: 时间复杂度O(N) 额外空间复杂度O(N)
- 上述三种都是非基于比较的排序,与被排序的样本数据实际情况很有关系,在实际中并不常用
- 另外以上三种都是稳定的排序
桶: 相当于一个容器,可以是数组中的某个位置也可以是双向链表也可以是一个队列也可以是一个堆
把相应东西放入相应桶内 然后再从低位置的桶依次到高位置 依次把东西倒出来 eg: 数组arr长度为60 数据值为0到60 使用桶排序: 生成一个数组temp长度为61 依次遍历arr得到arr[i]
将temp对应的数组值++ temp[arr[i]] = temp[arr[i]] + 1 遍历完了之后遍历数组temp输出结果
每个下标对应几个值就把下标值输出几遍
实际上这个实例是计数排序 实质上是桶排序的一种实现 基数排序将计数排序进行了改进,用10个桶进行排序 分别针对个位、十位、百位
(6)排序算法的稳定性
追求算法稳定性的意义: 第一次排序和第二次排序在某些值相等的情况下保持原来的排序顺序
- 冒泡排序: 可以实现稳定(相等的情况下后一个继续往后走)
- 插入排序: 可以实现稳定(相等就不往前插入)
- 选择排序: 做不到稳定
- 归并排序: 可以实现稳定(merge相等的时候就先移动左边的)
- 快速排序: 做不到稳定(partition时做不到)
- 堆排序: 做不到稳定
python拓展3 常用算法的更多相关文章
- python机器学习的常用算法
Python机器学习 学习意味着通过学习或经验获得知识或技能.基于此,我们可以定义机器学习(ML)如下 - 它可以被定义为计算机科学领域,更具体地说是人工智能的应用,其为计算机系统提供了学习数据和从经 ...
- Python之路,Day21 - 常用算法学习
Python之路,Day21 - 常用算法学习 本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的 ...
- python 下的数据结构与算法---2:大O符号与常用算法和数据结构的复杂度速查表
目录: 一:大O记法 二:各函数高阶比较 三:常用算法和数据结构的复杂度速查表 四:常见的logn是怎么来的 一:大O记法 算法复杂度记法有很多种,其中最常用的就是Big O notation(大O记 ...
- 第四百一十四节,python常用算法学习
本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机 ...
- Python常用算法
本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机 ...
- STL——配接器、常用算法使用
学习STL,必然会用到它里面的适配器和一些常用的算法.它们都是STL中的重要组成部分. 适配器 在STL里可以用一些容器适配得到适配器.例如其中的stack和queue就是由双端队列deque容器适配 ...
- linux和windows下安装python拓展包及requirement.txt安装类库
python拓展包安装 直接安装拓展包默认路径: Unix(Linux)默认路径:/usr/local/lib/pythonX.Y/site-packagesWindows默认路径:C:\Python ...
- python面试总结4(算法与内置数据结构)
算法与内置数据结构 常用算法和数据结构 sorted dict/list/set/tuple 分析时间/空间复杂度 实现常见数据结构和算法 数据结构/算法 语言内置 内置库 线性结构 list(列表) ...
- Python遗传和进化算法框架(一)Geatpy快速入门
https://blog.csdn.net/qq_33353186/article/details/82014986 Geatpy是一个高性能的Python遗传算法库以及开放式进化算法框架,由华南理工 ...
随机推荐
- ubuntu18.04 server配置静态ip (转载)
原文地址: https://blog.csdn.net/mossan/article/details/80381679 最新发布的ubuntu18.04 server,启用了新的网络工具netplan ...
- 【图像处理】Haar-like特征
特征提取的原理.代码等: 如果是白黑白,是减去一个黑的还是2个黑的,网上有不同的说法:应该需要看原论文了. 论文原文 The sum of the pixels which lie within th ...
- opencv实现遍历文件夹下所有文件
前言 最近需要将视频数据集中的每个视频进行分割,分割成等长的视频片段,前提是需要首先遍历数据集文件夹中的所有视频. 实现 1.了解opencv中的Directory类: 2.实现测试代码: 系统环境 ...
- chapter02 K近邻分类器对Iris数据进行分类预测
寻找与待分类的样本在特征空间中距离最近的K个已知样本作为参考,来帮助进行分类决策. 与其他模型最大的不同在于:该模型没有参数训练过程.无参模型,高计算复杂度和内存消耗. #coding=utf8 # ...
- Sublime配置VI插件后 快捷键总结
Vi编辑器快捷键 命令行模式: yy 复制当前行 yy5 复制向下5行 p 粘贴(注意粘贴到最后时候留一个换行符) p5 粘贴5次 dd 删除一行,剪切一行 G 最后一行 1G 第一行 ...
- JavaScript 之arguments、caller 和 callee 介绍
1.前言 arguments, caller , callee 是什么? 在javascript 中有什么样的作用?本篇会对于此做一些基本介绍. 2. arguments arguments: ...
- jquery中not的用法[.not(selector)]
描述: 从匹配的元素集合中移除指定的元素. 如果提供的jQuery对象代表了一组DOM元素,.not()方法构建一个新的匹配元素的jQuery对象,用于存放筛选后的元素.所提供的选择器是对每个元素进行 ...
- solr学习二(ExtractingRequestHandler)
通过ExtractingRequestHandler,slor能够读取word.pdf等文件,并用于全文搜索.废话少说,进入主题: solr服务端是配出来的: solrconfig.x ...
- asp.net excel 操作
/// <summary> /// 数据操作 /// </summary> /// <param name="fileName"></pa ...
- C#常用插件和工具
Code generation(代码自动生成) NVelocity CodeSmith X-Code .NET XGoF - NMatrix / DEVerest Compilation(编译工具) ...