Python 编码问题(十四)
一、了解字符编码的知识储备
1. 文本编辑器存取文件的原理(nodepad++,pycharm,word)
打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容也都是存放与内存中的,断电后数据丢失,因而需要保存到硬盘上,点击保存按钮,就从内存中把数据刷到了硬盘上。在这一点上,我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
即:在没有点击保存时,我们所写的内容都是写入内存。注意这一点,很重要!!当我们点击保存,内容才被刷到硬盘。
上面做了两件事:写内容到内存,从内存将内存刷到硬盘。这是两个过程。
2. python解释器执行py文件的原理 ,例如python test.py
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码
python解释器执行py文件分为两个步骤:1.将文件读到内存,2.解释执行内容。
二、字符编码简介
要搞清楚字符编码,首先要解决的问题是:什么是字符编码?
我们都知道,计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字(010101).如果我们想保存数据,首先得将我们的数据进行一些处理,最终得转换成010101才能让计算机识别。
所以必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
那么问题就来了?作为一种编码方案,还得解决两个问题:
a.字节是怎么分组的,如8 bits或16 bits一组,这也被称作编码单元。
b.编码单元和字符之间的映射关系。例如,在ASCII码中,十进制65映射到字母A上。
ASCII码是上个世纪最流行的编码体系之一,至少在西方是这样。下图显示了ASCII码中编码单元是怎么映射到字符上的。

三、字符编码的发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
随着计算机越来越流行,厂商之间的竞争更加激烈,在不同的计算机体系间转换数据变得十分蛋疼,人们厌烦了这种自定义造成的混乱。最终,计算机制造商一起制定了一个标准的方法来描述字符。他们定义使用一个字节的低7位来表示字符,并且制作了如上图所示的对照表来映射七个比特的值到一个字符上。例如,字母A是65,c是99,~是126等等, ASCII码就这样诞生了。原始的ASCII标准定义了从0到127 的字符,这样正好能用七个比特表示。
为什么选择了7个比特而不是8个来表示一个字符呢?我并不关心。但是一个字节是8个比特,这意味着1个比特并没有被使用,也就是从128到255的编码并没有被制定ASCII标准的人所规定,这些美国人对世界的其它地方一无所知甚至完全不关心。其它国家的人趁这个机会开始使用128到255范围内的编码来表达自己语言中的字符。例如,144在阿拉伯人的ASCII码中是گ,而在俄罗斯的ASCII码中是ђ。ASCII码的问题在于尽管所有人都在0-127号字符的使用上达成了一致,但对于128-255号字符却有很多很多不同的解释。你必须告诉计算机使用哪种风格的ASCII码才能正确显示128-255号的字符。
总结:ASCII,一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符,ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符),后来为了将拉丁文也编码进了ASCII表,将最高位也占用了。
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符;为了满足其他国家,各个国家纷纷定制了自己的编码。日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:万国码Unicode编码
后来,有人开始觉得太多编码导致世界变得过于复杂了,让人脑袋疼,于是大家坐在一起拍脑袋想出来一个方法:所有语言的字符都用同一种字符集来表示,这就是Unicode。
Unicode统一用2Bytes代表一个字符,2**16-1=65535,可代表6万多个字符,因而兼容万国语言.但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(英文字母只需要一个字节就足够,用两个字节来表示,无疑是浪费空间).于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes.UTF-8是一个非常惊艳的概念,它漂亮的实现了对ASCII码的向后兼容,以保证Unicode可以被大众接受。
在UTF-8中,0-127号的字符用1个字节来表示,使用和US-ASCII相同的编码。这意味着1980年代写的文档用UTF-8打开一点问题都没有。只有128号及以上的字符才用2个,3个或者4个字节来表示。因此,UTF-8被称作可变长度编码。于是下面字节流如下:
0100100001000101010011000100110001001111
这个字节流在ASCII和UTF-8中表示相同的字符:HELLO
至于其他的UTF-16,这里就不再叙述了。
总结一点:unicode:简单粗暴,所有字符都是2Bytes,优点是字符----->数字的转换速度快,缺点是占用空间大。
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示。
因此,内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快);硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
四、字符编码的使用

不管是哪种类型的文件,只要记住一点:文件以什么编码保存的,就以什么编码方式打开.
下面我们来看看python中关于编码出现的问题:
如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的python2中默认使用ascii,python3中默认使用utf-8
读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x="hello"
内存的编码使用unicode,不代表内存中全都是unicode编码的二进制,在程序执行之前,内存中确实都是unicode编码的二进制,比如从文件中读取了一行x="hello",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode编码的二进制形式存放与内存中的.但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间),可以存放任意编码格式的数据,比如x="hello",会被python解释器识别为字符串,会申请内存空间来存放"hello",然后让x指向该内存地址,此时新申请的该内存地址保存也是unicode编码的hello,如果代码换成x="hello".encode('utf-8'),那么新申请的内存空间里存放的就是utf-8编码的字符串hello了.

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
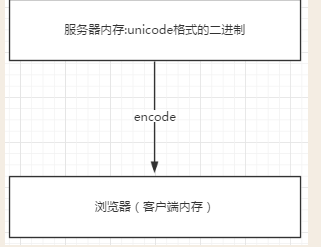
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的二进制
五、Python2与python3编码区别
1.在python2中有两种字符串类型str和unicode
str类型
当python解释器执行到产生字符串的代码时(例如s='林'),会申请新的内存地址,然后将'林'编码成文件开头指定的编码格式,这已经是encode之后的结果了,所以s只能decode。再次encode就会报错。
#_*_coding:gbk_*_
2 #!/usr/bin/env python
3
4 x='林'
5 # print x.encode('gbk') #报错
6 print x.decode('gbk') #结果:林
在python2中,str就是编码后的结果bytes,str=bytes,所以在python2中,unicode字符编码的结果是str/bytes。
#coding:utf-8
s='林' #在执行时,'林'会被以conding:utf-8的形式保存到新的内存空间中 print repr(s) #'\xe6\x9e\x97' 三个Bytes,证明确实是utf-8
print type(s) #<type 'str'> s.decode('utf-8')
# s.encode('utf-8') #报错,s为编码后的结果bytes,所以只能decode
Unicode类型
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode.
s=u'林'
print repr(s) #u'\u6797'
print type(s) #<type 'unicode'> # s.decode('utf-8') #报错,s为unicode,所以只能encode
s.encode('utf-8')
特别说明:
当数据要打印到终端时,要注意一些问题.
当程序执行时,比如:x='林';print(x) #这一步是将x指向的那块新的内存空间(非代码所在的内存空间)中的内存,打印到终端,而终端仍然是运行于内存中的,所以这打印可以理解为从内存打印到内存,即内存->内存,unicode->unicode.对于unicode格式的数据来说,无论怎么打印,都不会乱码.python3中的字符串与python2中的u'字符串',都是unicode,所以无论如何打印都不会乱码.在windows终端(终端编码为gbk,文件编码为utf-8,乱码产生)
#分别验证在pycharm中和cmd中下述的打印结果
s=u'林' #当程序执行时,'林'会被以unicode形式保存新的内存空间中 #s指向的是unicode,因而可以编码成任意格式,都不会报encode错误
s1=s.encode('utf-8')
s2=s.encode('gbk')
print s1 #打印正常否?
print s2 #打印正常否 print repr(s) #u'\u6797'
print repr(s1) #'\xe6\x9e\x97' 编码一个汉字utf-8用3Bytes
print repr(s2) #'\xc1\xd6' 编码一个汉字gbk用2Bytes print type(s) #<type 'unicode'>
print type(s1) #<type 'str'>
print type(s2) #<type 'str'>
2. 在python3中也有两种字符串类型str和bytes
str类型变为unicode类型
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中, #s可以直接encode成任意编码格式
s.encode('utf-8')
s.encode('gbk') print(type(s)) #<class 'str'>
bytes类型
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中, #s可以直接encode成任意编码格式
s1=s.encode('utf-8')
s2=s.encode('gbk') print(s) #林
print(s1) #b'\xe6\x9e\x97' 在python3中,是什么就打印什么
print(s2) #b'\xc1\xd6' 同上 print(type(s)) #<class 'str'>
print(type(s1)) #<class 'bytes'>
print(type(s2)) #<class 'bytes'>
Python 编码问题(十四)的更多相关文章
- 进击的Python【第十四章】:Web前端基础之Javascript
进击的Python[第十四章]:Web前端基础之Javascript 一.javascript是什么 JavaScript 是一种轻量级的编程语言. JavaScript 是可插入 HTML 页面的编 ...
- 孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块
孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块 (完整学习过程屏幕记录视频地址在文末) 由于本身tesseract模块针对普通的验证码图片的识别率并不高 ...
- 孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4
孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第六十四天学习mongoDB的基本操作并进行简单封装3
孤荷凌寒自学python第六十四天学习mongoDB的基本操作并进行简单封装3 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第十天. 今天继续学习mongoDB的简单操作, ...
- 孤荷凌寒自学python第五十四天使用python来删除Firebase数据库中的文档
孤荷凌寒自学python第五十四天使用python来删除Firebase数据库中的文档 (完整学习过程屏幕记录视频地址在文末) 今天继续研究Firebase数据库,利用google免费提供的这个数据库 ...
- 孤荷凌寒自学python第三十四天python的文件操作对file类的对象学习
孤荷凌寒自学python第三十四天python的文件操作对file类的对象学习 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 一.close() 当一个file对象执行此方法时,将关闭当前 ...
- python 教程 第十四章、 地址薄作业
第十四章. 地址薄作业 #A Byte of Python #!/usr/bin/env python import cPickle import os #define the contacts fi ...
- 刨根究底字符编码之十四——UTF-16究竟是怎么编码的
UTF-16究竟是怎么编码的 1. 首先要注意的是,代理Surrogate是专属于UTF-16编码方式的一种机制,UTF-8和UTF-32是不用代理的. 如前文所述,为了让UTF-16能继续编码基本平 ...
- Python 学习 第十四篇:命名元组
Python的元组不能为元组内部的数据进行命名,而 collections.namedtuple 可以来构造一个含有字段名称的元组类,命名元组可以通过逗号+字段名来获取元素值: collections ...
- Python学习(十四) —— 并发编程
一.进程的概念 进程即正在执行的一个过程,进程是对正在运行的程序的一个抽象. 进程的概念起源于操作系统,是操作系统最核心的概念.操作系统的其它所有内容都是围绕进程的概念展开的. #必备的理论基础 #一 ...
随机推荐
- SPOJ - HIGH Highways(矩阵树定理)
https://vjudge.net/problem/SPOJ-HIGH 题意: 给n个点m条边,求生成树个数. 思路: 矩阵树裸题. 具体的话可以看一下周冬的论文<生成树的计数及其应用> ...
- ROS编译时(catkin_make)找不到bullet,Could NOT find Bullet (missing: BULLET_DYNAMICS_LIBRARY
sudo apt-get install libbullet-dev
- Ubuntu 16.04 kinetic 编译指定包
编译指定包 catkin_make -DCATKIN_WHITELIST_PACKAGES=baoming 使用上述命令后catkin_make会一直编译上面那个包,想要编译全部包,使用 catkin ...
- Seafile 文件访问日志时间不一致问题
修改/seafile-server-latest/seahub/seahub/setting.py # Local time zone for this installation. Choices c ...
- [原][osg][osgearth]简单的通过osgDB,读取高程tif,修改高程tif
ReadResult result; osg::ref_ptr<osgDB::ReaderWriter> reader = osgDB::Registry::instance()-> ...
- Codeforces 496C - Removing Columns
496C - Removing Columns 思路:暴力,用vis标记数组实时记录一下之前的行i+1和上一行i否全相等,false表示全相等. 代码: #include<bits/stdc++ ...
- Lua---执行
1.交互式: 2.脚本式(在命令行不要启动lua解释器,直接输): Testlua.lua 的内容: print("Hello World!")
- 雷林鹏分享:Ruby 方法
Ruby 方法 Ruby 方法与其他编程语言中的函数类似.Ruby 方法用于捆绑一个或多个重复的语句到一个单元中. 方法名应以小写字母开头.如果您以大写字母作为方法名的开头,Ruby 可能会把它当作常 ...
- Linux下搜索文件
使用linux系统难免会忘记文件所在的位置,可以使用以下命令对系统中的文件进行搜索.搜索文件的命令为"find":"locate":"whereis& ...
- 4-12 如何搜索API
遇到一个参数prompt,使用rails ,API没有找到,怎么办? site关键字 在全网搜索 或者google一下,或是在stack overflow 上找答案 prompt 是FormOptio ...