第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
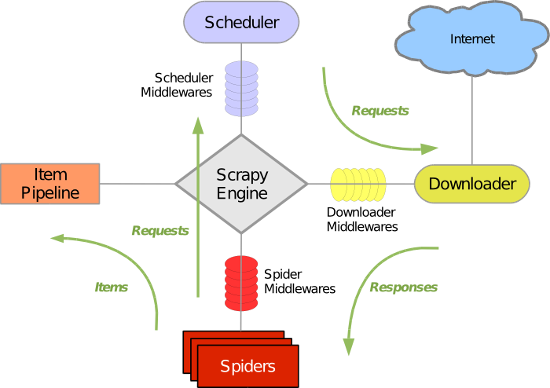
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
创建Scrapy框架项目
Scrapy框架项目是有python安装目录里的Scripts文件夹里scrapy.exe文件创建的,所以python安装目录下的Scripts文件夹要配置到系统环境变量里,才能运行命令生成项目
创建项目
首先运行cmd终端,然后cd 进入要创建项目的目录,如:cd H:\py\14
进入要创建项目的目录后执行命令 scrapy startproject 项目名称
scrapy startproject pach1
项目创建成功
项目说明
目录结构如下:
├── firstCrawler
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
scrapy.cfg: 项目的配置文件tems.py: 项目中的item文件,用来定义解析对象对应的属性或字段。pipelines.py: 负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库)settings.py: 项目的设置文件.- spiders:实现自定义爬虫的目录
- middlewares.py:Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。

创建第一个爬虫
创建爬虫文件在spiders文件夹里创建
1、创建一个类必须继承scrapy.Spider类,类名称自定义
类里的属性和方法:
name属性,设置爬虫名称
allowed_domains属性,设置爬取的域名,不带http
start_urls属性,设置爬取的URL,带http
parse()方法,爬取页面后的回调方法,response参数是一个对象,封装了所有的爬取信息
response对象的方法和属性
response.url获取抓取的rul
response.body获取网页内容字节类型
response.body_as_unicode()获取网站内容字符串类型
# -*- coding: utf-8 -*-
import scrapy class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/'] def parse(self, response):
current_url = response.url #获取抓取的rul
body = response.body #获取网页内容字节类型
unicode_body = response.body_as_unicode() #获取网站内容字符串类型
print(unicode_body)
爬虫写好后执行爬虫,cd到爬虫目录里执行scrapy crawl adc --nolog命令,说明:scrapy crawl adc(adc表示爬虫名称) --nolog(--nolog表示不显示日志)
也可以在PyCharm执行命令

第三百二十四节,web爬虫,scrapy模块介绍与使用的更多相关文章
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册
第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册 基于类的路由映射 from django.conf.urls import url, incl ...
- 第三百七十四节,Django+Xadmin打造上线标准的在线教育平台—创建课程app,在models.py文件生成4张表,课程表、课程章节表、课程视频表、课程资源表
第三百七十四节,Django+Xadmin打造上线标准的在线教育平台—创建课程app,在models.py文件生成4张表,课程表.课程章节表.课程视频表.课程资源表 创建名称为app_courses的 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection) Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数 ...
随机推荐
- dom4j: 用dom4j生成xml后第二行空行的问题
只需要指定: format.setNewLineAfterDeclaration(false); 即可. 例: OutputFormat format = OutputFormat.createPre ...
- [Windows Azure] Data Management and Business Analytics
http://www.windowsazure.com/en-us/develop/net/fundamentals/cloud-storage/ Managing and analyzing dat ...
- vim中权限不足时不用退出而强制保存
命令: :w !sudo tee % 此命令是把当前文件(即%)作为stdin传给sudo tee命令来执行.说起来挺绕口,其实就是:用sudo强制保存. 有时候在自己机器上折腾的时候需要更改一些 ...
- Flume中的HDFS Sink配置参数说明【转】
转:http://lxw1234.com/archives/2015/10/527.htm 关键字:flume.hdfs.sink.配置参数 Flume中的HDFS Sink应该是非常常用的,其中的配 ...
- SQL Server 2008 R2升级到SQL Server 2012 SP1
1.建议对生产环境对的数据库升级之前做好备份,以防不测. 2.从SQL Server 2008 R2 升级到SQL Server 2012 SP1,需要先安装SQL Server 2008 R2 的S ...
- 【Ensemble methods】组合方法&集成方法
机器学习的算法中,讨论的最多的是某种特定的算法,比如Decision Tree,KNN等,在实际工作以及kaggle竞赛中,Ensemble methods(组合方法)的效果往往是最好的,当然需要消耗 ...
- hdu1102(最小生成树水题)
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> us ...
- go语言可变参数的坑
0x00 前提 对可变参数不了解的同学,可以先看这篇文章可变参数终极指南 0x01 第一个坑 不能通过空接口类型向可变参数传递一个普通的切片 ,需要将普通切片转换为空接口切片 0x02 第二个坑 可变 ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- myeclipse之SSH整合图文详解
首先搭建开发环境 打开MyEclipse,新建一个web project ,然后右击项目执行如下步骤: 开启服务器无错误即搭建成功,整合后项目目录: 另附上SSH所必须的开发包: