Linux进程地址空间 && 进程内存布局[转]
一 进程空间分布概述
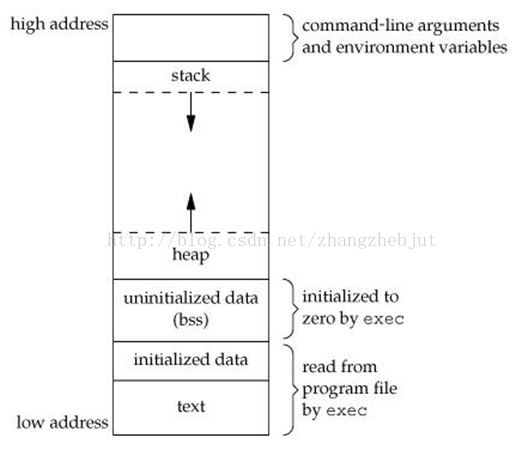
程序段(Text):程序代码在内存中的映射,存放函数体的二进制代码。
初始化过的数据(Data):在程序运行初已经对变量进行初始化的数据。
未初始化过的数据(BSS):在程序运行初未对变量进行初始化的数据。
栈 (Stack):存储局部、临时变量,函数调用时,存储函数的返回指针,用于控制函数的调用和返回。在程序块开始时自动分配内存,结束时自动释放内存,其操作方式类似于数据结构中的栈。
堆 (Heap):存储动态内存分配,需要程序员手工分配,手工释放.注意它与数据结构中的堆是两回事,分配方式类似于链表。
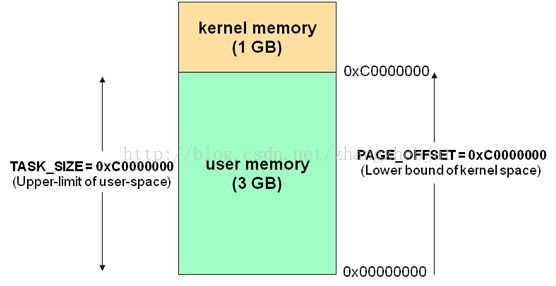
Linux使用两级保护机制:0级供内核使用,3级供用户程序使用,每个进程有各自的私有用户空间(0~3G),这个空间对系统中的其他进程是不可见的,最高的1GB字节虚拟内核空间则为所有进程以及内核所共享。
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。 虽然内核空间占据了每个虚拟空间中的最高1GB字节,但映射到物理内存却总是从最低地址(0x00000000),另外,使用虚拟地址可以很好的保护内核空间被用户空间破坏,虚拟地址到物理地址转换过程有操作系统和CPU共同完成(操作系统为CPU设置好页表,CPU通过MMU单元进行地址转换)。
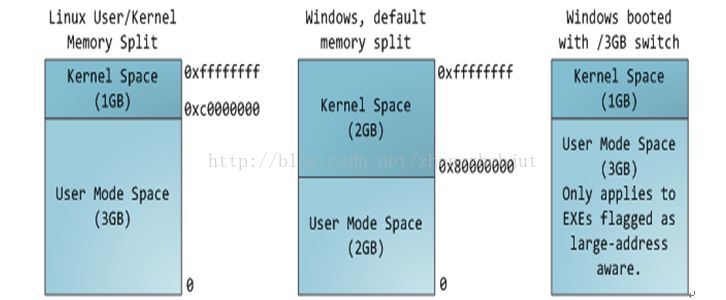
相对地,应用程序则是在“用户空间”中运行。运行在用户空间的应用程序只能看到允许它们使用的部分系统资源,并且不能使用某些特定的系统功能,也不能直接访问内核空间和硬件设备,以及其他一些具体的使用限制。
将用户空间和内核空间置于这种非对称访问机制下有很好的安全性,能有效抵御恶意用户的窥探,也能防止质量低劣的用户程序的侵害,从而使系统运行得更稳定可靠。
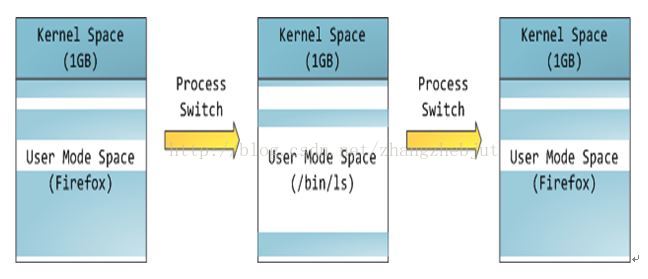
上图中蓝色区域表示映射到物理内存的虚拟地址,而白色区域表示未映射的部分。可以看出,Firefox使用了相当多的虚拟地址空间,因为它占用内存较多。
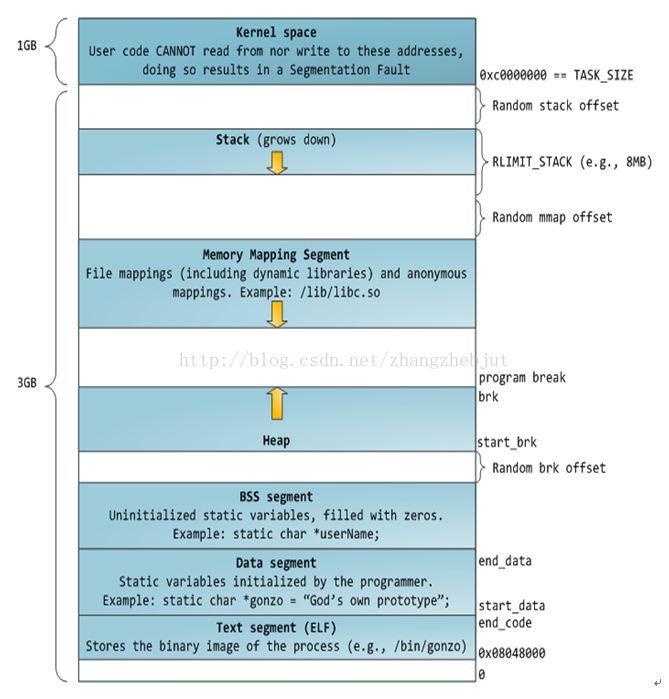
进程地址空间中最顶部的段是栈,大多数编程语言将之用于存储函数参数和局部变量。调用一个方法或函数会将一个新的栈帧(stack frame)压入到栈中,这个栈帧会在函数返回时被清理掉。由于栈中数据严格的遵守FIFO的顺序,这个简单的设计意味着不必使用复杂的数据结构来追踪栈中的内容,只需要一个简单的指针指向栈的顶端即可,因此压栈(pushing)和退栈(popping)过程非常迅速、准确。进程中的每一个线程都有属于自己的栈。
通过不断向栈中压入数据,超出其容量就会耗尽栈所对应的内存区域,这将触发一个页故障(page fault),而被Linux的expand_stack()处理,它会调用acct_stack_growth()来检查是否还有合适的地方用于栈的增长。如果栈的大小低于RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情。这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会栈溢出(stack overflow),程序收到一个段错误(segmentation fault)。

你可以通过阅读文件/proc/pid_of_process/maps来检验一个Linux进程中的内存区域。记住:一个段可能包含许多区域。比如,每个内存映射文件在mmap段中都有属于自己的区域,动态库拥有类似BSS和数据段的额外区域。有时人们提到“数据段”,指的是全部的数据段+BSS+堆。
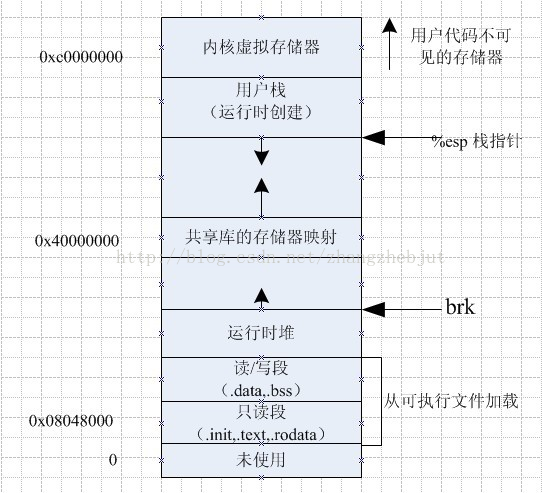
你还可以通过nm和objdump命令来察看二进制镜像,打印其中的符号,它们的地址,段等信息。最后需要指出的是,前文描述的虚拟地址布局在linux中是一种“灵活布局”,而且作为默认方式已经有些年头了,它假设我们有值RLIMT_STACK。但是,当没有该值得限制时,Linux退回到“经典布局”,如下图所示:
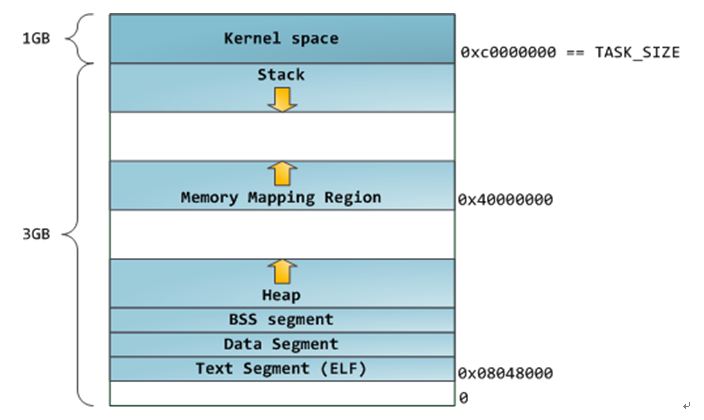
进程内存分布
之前一直在分析栈,栈这个东西的作用也介绍得差不多了,但是栈在哪儿还没有搞清楚,以及堆、代码、全局变量它们在哪儿,这都牵涉到进程的内存分布。
linux 0.01 的进程内存分布
内存分布随着操作系统的更新换代,越来越科学合理,也越来越复杂,所以我们还是先了解一下早期操作系统的典型 linux 0.01 的进程的内存分布:
linux 0.01 的一个进程固定拥有64MB的线性内存空间(ACM竞赛中单个程序的最大内存占用限制为64MB,这肯定有猫腻O(∩_∩)O~),各个进程挨个放置在一张页目录表中,一个页目录表可管理4G的线性空间,因此 linux0.01 最多有 64个进程。每个进程的内存分布如下:

- .text 里存的是机器码序列
- .rodata 里存的是源字符串等只读内容
- .data 里存的是初始化的全局变量
- .bss 上一篇介绍过了,存的是未初始化的全局变量
- 堆、栈就不用介绍了吧!
- 【注意】static 变量未初始化默认赋值为0或者空格。未初始化变量和初始化为0,都分配在.bss段。
.text .rodata .data .bss 是常驻内存的,也就是说进程从开始运行到进程僵死它们一直蹲在那里,所以访问它们用的是常量地址;而栈是不断的加帧(函数调用)、减帧(函数返回)的,帧内的局部变量只能用相对于当前 esp(指向栈顶)或 ebp(指向当前帧)的相对地址来访问。
栈被放置在高地址也是有原因的: 调用函数(加帧)是减 esp 的,函数返回(减帧)是加 esp 的,调用在前,所以栈是向低地址扩展的,放在高地址再合适不过了。
现代操作系统的进程内存分布
认识了 linux 0.01 的内存分布后,再看看现代操作系统的内存分布发生了什么变化:
首先,linux 0.01 进程的64MB内存限制太过时了,现在的程序都有潜力使用到 2GB、3GB 的内存空间(每个进程一张页目录表),当然,机器有硬伤的话也没办法,我的电脑就只有 2GB 的内存,想用 3GB 的内存是没指望了。但也不是有4GB内存就可以用4GB(32位),因为操作系统还要占个坑呢!现代 linux 中 0xC0000000 以上的 1GB 空间是操作系统专用的,而 linux 0.01 中第1个 64MB 是操作系统的坑,所以别的进程完全占有它们的 64MB,也不用跟操作系统客气。
其次,linux 0.01只有进程没有线程,但是现代 linux 有多线程了(linux 的线程其实是个轻量级的进程),一个进程的多个线程之间共享全局变量、堆、打开的文件…… 但栈是不能共享的:栈中各层函数帧代表着一条执行线索,一个线程是一条执行线索,所以每个线程独占一个栈,而这些栈又都必须在所属进程的内存空间中。
根据以上两点,进程的内存分布就变成了下面这个样子:

再者,如果把动态装载的动态链接库也考虑进去的话,上面的分布图将会更加"破碎"。
如果我们的程序没有采用多线程的话,一般可以简单地认为它的内存分布模型是 linux 0.01 的那种。
Linux进程地址空间 && 进程内存布局[转]的更多相关文章
- [内存管理]linux X86_64处理器的内存布局图
linux X86 64位内存布局图
- 把握linux内核设计思想(十三):内存管理之进程地址空间
[版权声明:尊重原创,转载请保留出处:blog.csdn.net/shallnet.文章仅供学习交流,请勿用于商业用途] 进程地址空间由进程可寻址的虚拟内存组成,Linux 的虚拟地址空间为0~4G字 ...
- 【转载】linux内核笔记之进程地址空间
原文:linux内核笔记之进程地址空间 进程的地址空间由允许进程使用的全部线性地址组成,在32位系统中为0~3GB,每个进程看到的线性地址集合是不同的. 内核通过线性区的资源(数据结构)来表示线性地址 ...
- Linux进程地址空间与虚拟内存
http://blog.csdn.net/xu3737284/article/details/12710217 32位机器上linux操作系统中的进程的地址空间大小是4G,其中0-3G是用户空间,3G ...
- linux 内存布局以及tlb更新的一些理解
问题: 1.内核线程是否有vma线性区? 2.单线程的一个进程,它修改了自己的页表,是否需要发送ipi来通知其他核更新tlb? 3.普通进程,在32位和64位,对应的线性区的最大地址能到多少? 在64 ...
- Windows进程通信 -- 共享内存(1)
共享内存的方式原理就是将一份物理内存映射到不同进程各自的虚拟地址空间上,这样每个进程都可以读取同一份数据,从而实现进程通信.因为是通过内存操作实现通信,因此是一种最高效的数据交换方法. 共享内存在 W ...
- linux作业六——进程的描述和进程的创建
进程的描述和进程的创建 一.进程描述符task_struct 为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息. 代码关键点: 1.Struct list_hea ...
- Windows进程通信 -- 共享内存
享内存的方式原理就是将一份物理内存映射到不同进程各自的虚拟地址空间上,这样每个进程都可以读取同一份数据,从而实现进程通信.因为是通过内存操作实现通信,因此是一种最高效的数据交换方法. 共享内存在 Wi ...
- Linux性能优化之内存优化(二)
前言 不知道大家看完前面一章关于CPU优化,是否受到相应的启发呢?如果遇到任何问题,可以留言和一起探讨这方面的问题.接下来我们介绍一些关于内存方面的知识.内存管理软件包括虚拟内存系统.地址转换.交换. ...
随机推荐
- sqlite 时间函数及时间处理
SQLite分页显示:Select * From news order by id desc Limit 10 Offset 10这篇文章是根据 SQLite 官方 WIKI 里的内容翻译,如果有什么 ...
- webpack2-webpack.config.js配置
写在前面: 了解更多:https://github.com/miaowwwww/webpack-learn 贴一个webpack.ocnfig.js 的配置属性表 一.代码分割: 1.插件 Comm ...
- nlinfit非线性回归拟合
% % 使用指定函数对下述两变量进行曲线拟合 % % y=a+k1*exp(m*t)+k2*exp(-m*t); % % 离散点: t=[0,4,8,40], % % y=[20.09,64.5 ...
- Linux的inode的理解 ZZ
文件名 -> inode -> device block 转自:http://www.ruanyifeng.com/blog/2011/12/inode.htmlhttp://blog.s ...
- Studying TCP's Throughput and Goodput using NS
Studying TCP's Throughput and Goodput using NS What is Throughput Throughput is the amount of data r ...
- X11/Xlib.h:没有该文件或目录
编译程序时出现的错误,在安装日志上发现一句:x11/xlib.h nosuch file or directory 在网上查阅了资料,原来是x11M没有装. 解决方案:先安装X11,命令为 su ...
- viirtualBox显示不了Ip并且无法上网的解决方式
首先描述下我自己遇到的问题:就是在virtualBox下的ubuntu系统下,输入ifconfig,没有显示出ip,显示出了eth3,lo的相关信息.在网上也找了相关信息还是无法解决,终于在老大的 ...
- Log4j的配置文件
附:Log4j比较全面的配置 Log4j配置文件实现了输出到控制台.文件.回滚文件.发送日志邮件.输出到数据库日志表.自定义标签等全套功能. log4j.rootLogger=DEBUG,consol ...
- Myeclipes连接Mysql数据库配置
相信大家在网站上也找到了许多关于myeclipes如何连接mysql数据库的解决方案,虽然每一步都按照他的步骤来,可到最后还是提示连接失败,有的方案可能应个人设备而异,配置环境不同导致.经过个人多方探 ...
- 杜比(dolby)自动关闭,windows10声音自动变小
电脑问题描述:2018.01.21 win10更新后,看视频电脑声音自动变小,重开机电脑声音正常,一会又会变小.找了很多网上的东西,实践后发现是杜比(dolby)自动关闭导致的,自动关闭的原因是因为切 ...