Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译)
- 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如:
- 加cookie,身份验证UserAgent
- 图形验证,还有很难破解的滑动验证
- js签名验证,对传输数据进行加密处理
- 对于js加密
- 经过加密传输的就是密文,但是加密函数或者过程一定是在浏览器完成,
也就是一定会把js代码暴露给使用者 - 通过阅读加密算法,就可以模拟出加密过程,从而达到破解
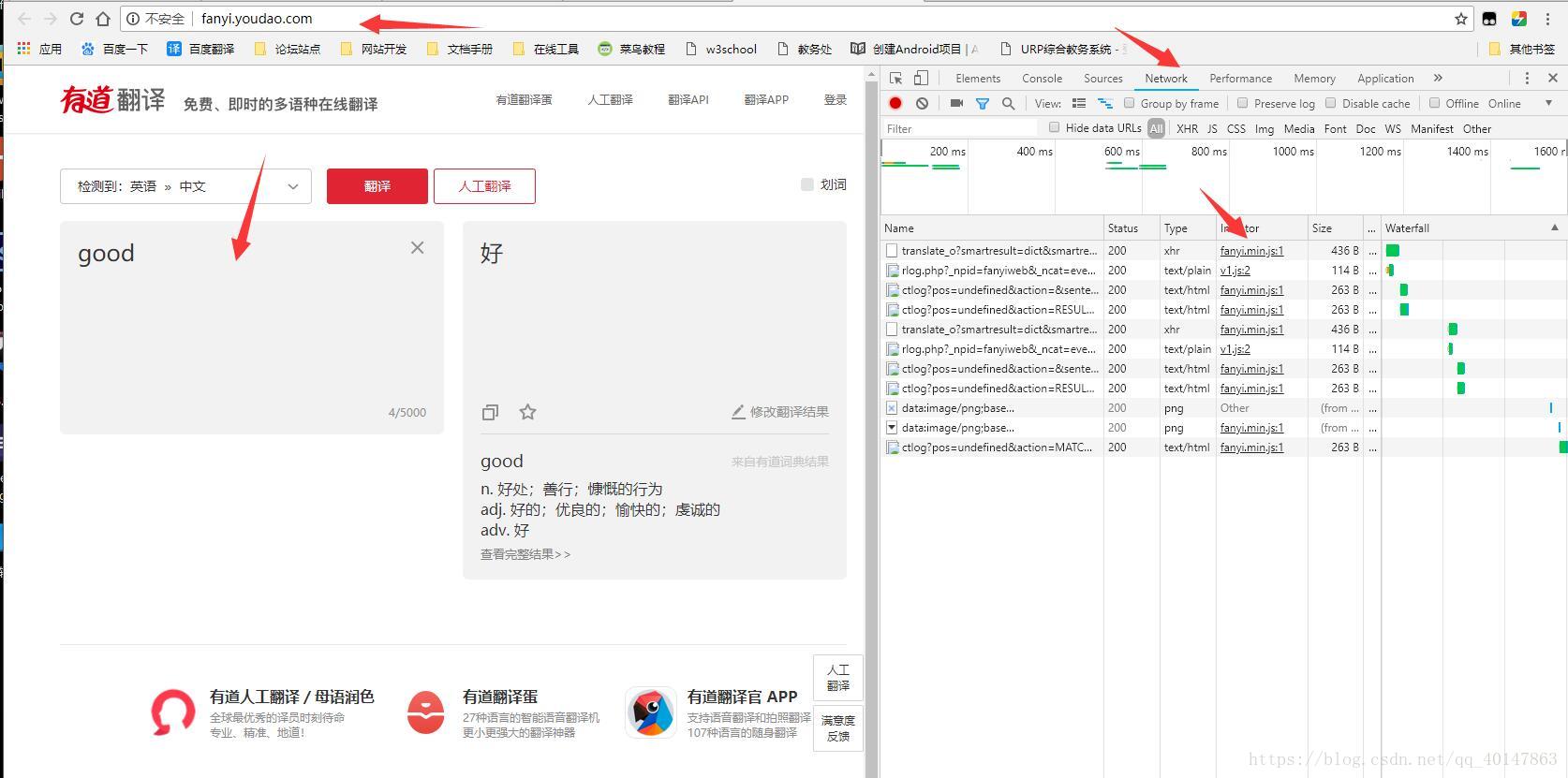
- 怎样判断网站有没有使用js加密,很简单,例如有道在线翻译
1.打开【有道在线翻译】网页:http://fanyi.youdao.com/
2.【右键检查】,选中【Network】
3.【输入单词】
4.在请求中,找到关于翻译内容的Form Data,可以看到有下面两项说明js加密
"salt": "1523100789519",
"sign": "b8a55a436686cd8973fa46514ccedbe",
- 经过加密传输的就是密文,但是加密函数或者过程一定是在浏览器完成,
分析js
- 一定要按照下面的顺序,不然的话会有很多无用的东西干扰
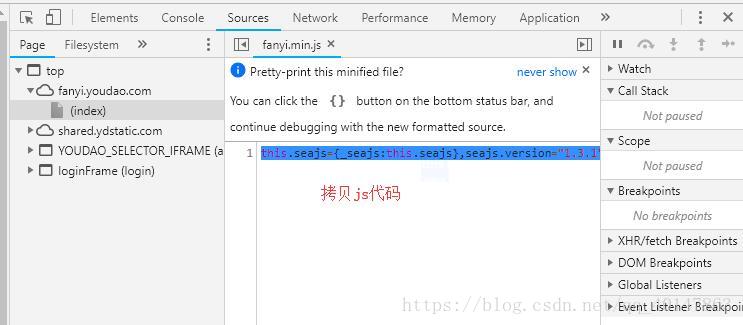
- 1.打开【有道在线翻译】网页:http://fanyi.youdao.com/
- 2.【右键检查】,选中【Network】
- 3.【输入单词】,【抓取js代码】
- 操作截图:
- 我们得到的js代码是一行代码,是压缩后的min代码,我们需要进行格式转换
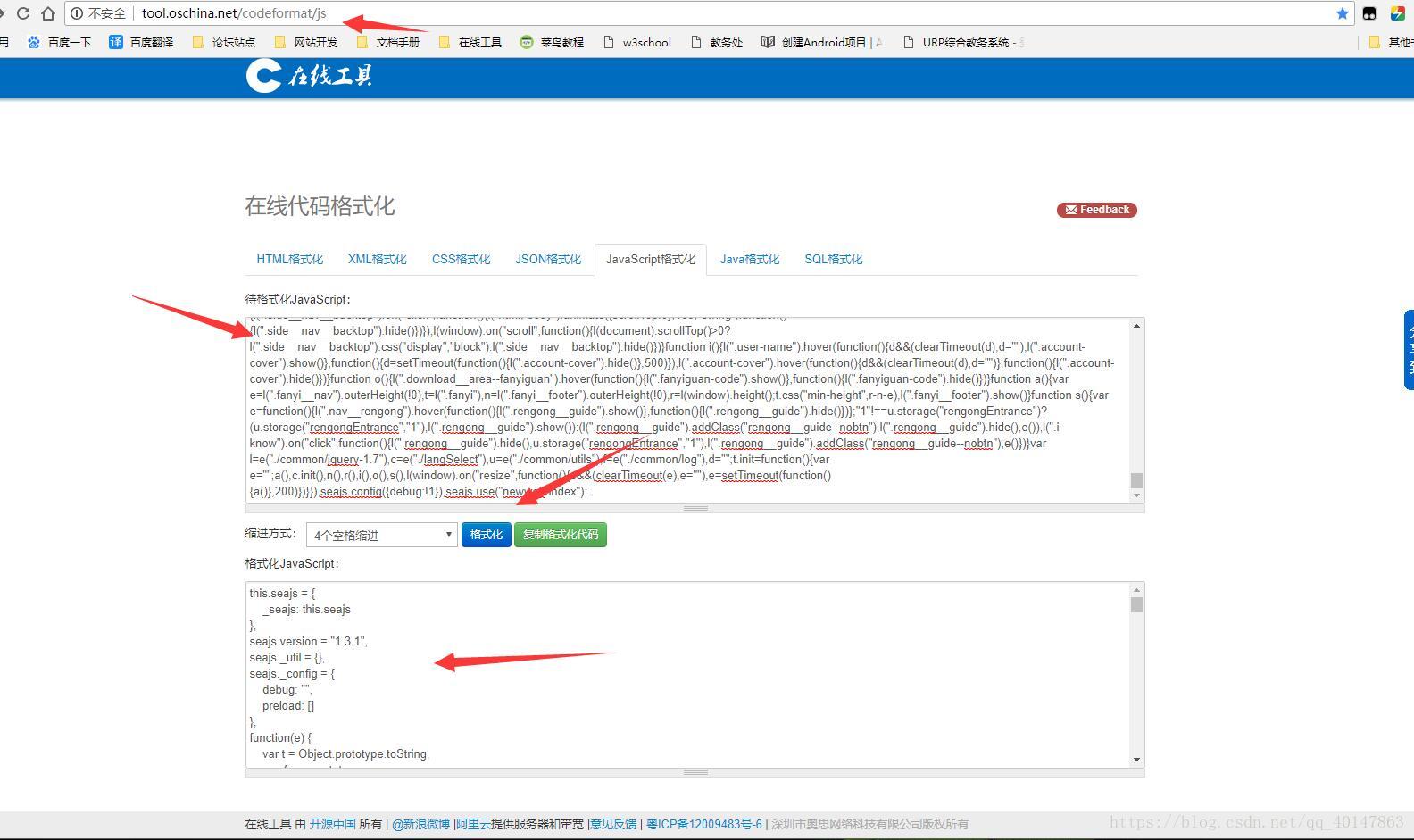
- 4.打开在线代码格式化网站:http://tool.oschina.net/codeformat/js
- 5.将拷贝的一行格式的js代码,粘贴在表单中,点击【格式化】
- 操作截图:
- 然后将格式化后的js代码,拷贝到一个可以搜索的代码编码器,备用
- 编写第2个版本
- 案例v18文件:https://xpwi.github.io/py/py爬虫/py18js2.py
# 破解js加密,版本2
'''
通过在js文件中查找salt或者sign,可以找到
1.可以找到这个计算salt的公式
r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10))
2.sign:n.md5("fanyideskweb" + t + r + "ebSeFb%=XZ%T[KZ)c(sy!");
md5 一共需要四个参数,第一个和第四个都是固定值得字符串,第三个是所谓的salt,
第二个参数是输入的需要翻译的单词
'''
from urllib import request, parse
def getSalt():
'''
salt的公式r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10))
把它翻译成python代码
'''
import time, random
salt = int(time.time()*1000) + random.randint(0, 10)
return salt
def getMD5(v):
import hashlib
md5 = hashlib.md5()
md5.update(v.encode('utf-8'))
sign = md5.hexdigest()
return sign
def getSign(key, salt):
sign = "fanyideskweb" + key + str(salt) + "ebSeFb%=XZ%T[KZ)c(sy!"
sign = getMD5(sign)
return sign
def youdao(key):
# url从http://fanyi.youdao.com输入词汇右键检查得到
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=true"
salt = getSalt()
# data从右键检查FormData得到
data = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": str(salt),
"sign": getSign(key, salt),
"doctype": "json",
"version": "2.1",
"keyform": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false"
}
print(data)
# 对data进行编码,因为参数data需要bytes格式
data = parse.urlencode(data).encode()
# headers从右键检查Request Headers得到
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": len(data),
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "OUTFOX_SEARCH_USER_ID=685021846@10.168.8.76; OUTFOX_SEARCH_USER_ID_NCOO=366356259.5731474; _ntes_nnid=1f61e8bddac5e72660c6d06445559ffb,1535033370622; JSESSIONID=aaaVeQTI9KXfqfVBNsXvw; ___rl__test__cookies=1535204044230",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
req = request.Request(url=url, data=data, headers=headers)
rsp = request.urlopen(req)
html = rsp.read().decode()
print(html)
if __name__ == '__main__':
youdao("girl")
运行结果
返回翻译后的值,才算是成功
注意
按照步骤,熟悉流程最重要
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-16-破解js加密实例(有道在线翻译)的更多相关文章
- python爬虫_从零开始破解js加密(一)
除了一些类似字体反爬之类的奇淫技巧,js加密应该是反爬相当常见的一部分了,这也是一个分水岭,我能解决基本js加密的才能算入阶. 最近正好遇到一个比较简单的js,跟大家分享一下迅雷网盘搜索_838888 ...
- Python破解js加密实例(有道在线翻译)
在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签名验证,对传输数据进行加密处理 对于js加密经过加密传输的就是 ...
- Python爬虫教程(16行代码爬百度)
最近在学习python,不过有一个正则表达式一直搞不懂,自己直接使用最笨的方法写出了一个百度爬虫,只有短短16行代码.首先安装必背包: pip3 install bs4 pip3 install re ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫—破解JS加密的Cookie
前言 在GitHub上维护了一个代理池的项目,代理来源是抓取一些免费的代理发布网站.上午有个小哥告诉我说有个代理抓取接口不能用了,返回状态521.抱着帮人解决问题的心态去跑了一遍代码.发现果真是这样. ...
- python爬虫之快速对js内容进行破解
python爬虫之快速对js内容进行破解 今天介绍下数据被js加密后的破解方法.距离上次发文已经过去半个多月了,我写文章的主要目的是把从其它地方学到的东西做个记录顺便分享给大家,我承认自己是个懒猪.不 ...
- 爬虫破解js加密(一) 有道词典js加密参数 sign破解
在爬虫过程中,经常给服务器造成压力(比如耗尽CPU,内存,带宽等),为了减少不必要的访问(比如爬虫),网页开发者就发明了反爬虫技术. 常见的反爬虫技术有封ip,user_agent,字体库,js加密, ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
随机推荐
- Go语言包和文件
工作空间 Go语言工作空间:编译工具对源码目录有严格要求,每个工作空间 (workspace) 必须由bin.pkg.src三个目录组成. src ---- 项目源码目录,里面每一个子目录,就是一个包 ...
- 爱漂泊人生 30个php操作redis常用方法代码例子
http://www.justwinit.cn/post/8789/ 背景:redis这个新产品在sns时很火,而memcache早就存在, 但redis提供出来的功能,好多网站均把它当memcach ...
- pycharm 工具栏Tool中找不到Run manager.py Task
pycharm 工具栏Tool中找不到Run manager.py Task 在做Django项目的过程中, 无法进入pycharm提供的Run manager.py Task交互环境 出现这种问题是 ...
- cv2.FileNode has no keys
把 python-opencv 版本由3.4.1 换成 3.4.4之后,问题解决
- 010-JedisUtils工具类模板
redis.properties配置文件 redis.maxIdle=30 redis.minIdle=10 redis.maxTotal=100 redis.url=192.168.204.128 ...
- 存储器的保护(二)——《x86汇编语言:从实模式到保护模式》读书笔记19
接着上一篇博文说. 5.代码段执行时的保护 每个代码段都有自己的段界限.同栈段一个道理,有效界限和G位相关. G=0:有效界限 = 描述符中的段界限 G=1:有效界限 = 描述符中的段界限值 * 0x ...
- poj 2572 Hard to Believe, but True!
Hard to Believe, but True! Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 3537 Accep ...
- 九度oj题目1341:艾薇儿的演唱会
题目1341:艾薇儿的演唱会(40分) 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:522 解决:237 题目描述: 艾薇儿今天来到了中国,她计划两天后在哈尔滨举行一场个人的演唱会.由于 ...
- luajit+nginx+上传模块+lua模块编译安装
git clone https://github.com/fdintino/nginx-upload-module.git git clone https://github.com/openresty ...
- bzoj 4540: [Hnoi2016]序列
Description 给定长度为n的序列:a1,a2,-,an,记为a[1:n].类似地,a[l:r](1≤l≤r≤N)是指序列:al,al+1,-,ar- 1,ar.若1≤l≤s≤t≤r≤n,则称 ...