jieba结巴分词
pip install jieba
安装jieba模块 如果网速比较慢,
可以使用豆瓣的Python源:
pip install -i https://pypi.douban.com/simple/ jieba 一、分词:
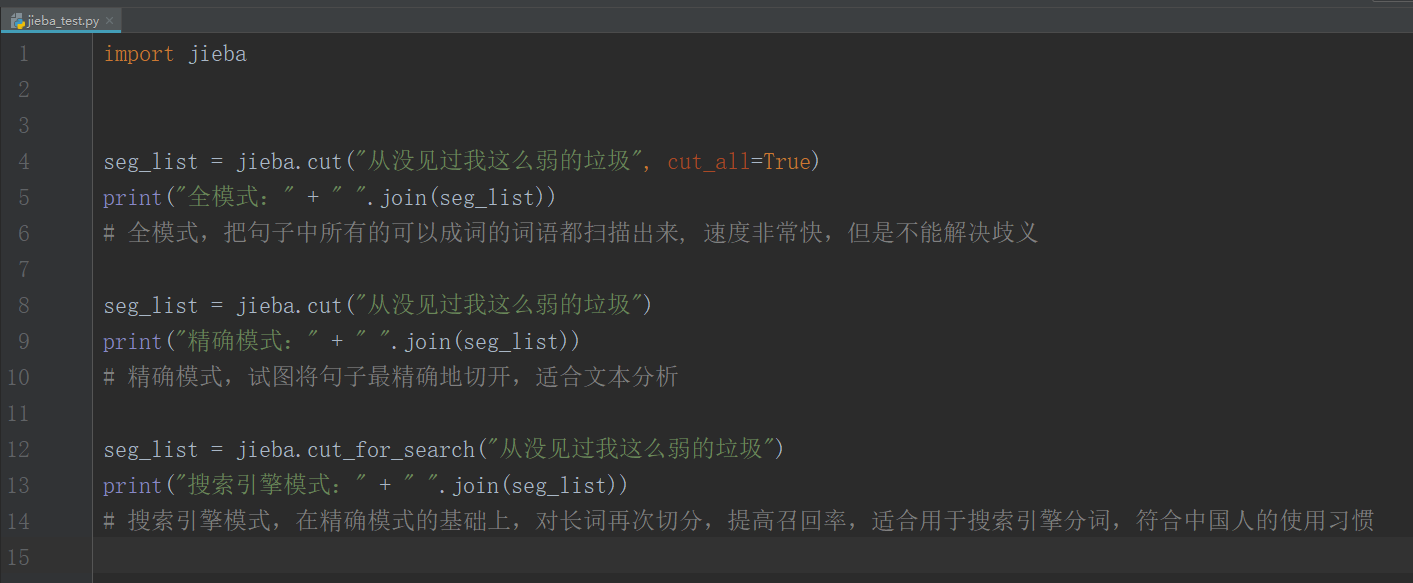
import jieba
seg_list = jieba.cut("从没见过我这么弱的垃圾", cut_all=True)
print("全模式:" + " ".join(seg_list))
# 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
seg_list = jieba.cut("从没见过我这么弱的垃圾")
print("精确模式:" + " ".join(seg_list))
# 精确模式,试图将句子最精确地切开,适合文本分析
seg_list = jieba.cut_for_search("从没见过我这么弱的垃圾")
print("搜索引擎模式:" + " ".join(seg_list))
# 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,符合中国人的使用习惯
打印结果:
全模式:从没 没见 过 我 这么 弱 的 垃圾
精确模式:从没 见 过 我 这么 弱 的 垃圾
搜索引擎模式:从没 见 过 我 这么 弱 的 垃圾
也可以这样写:
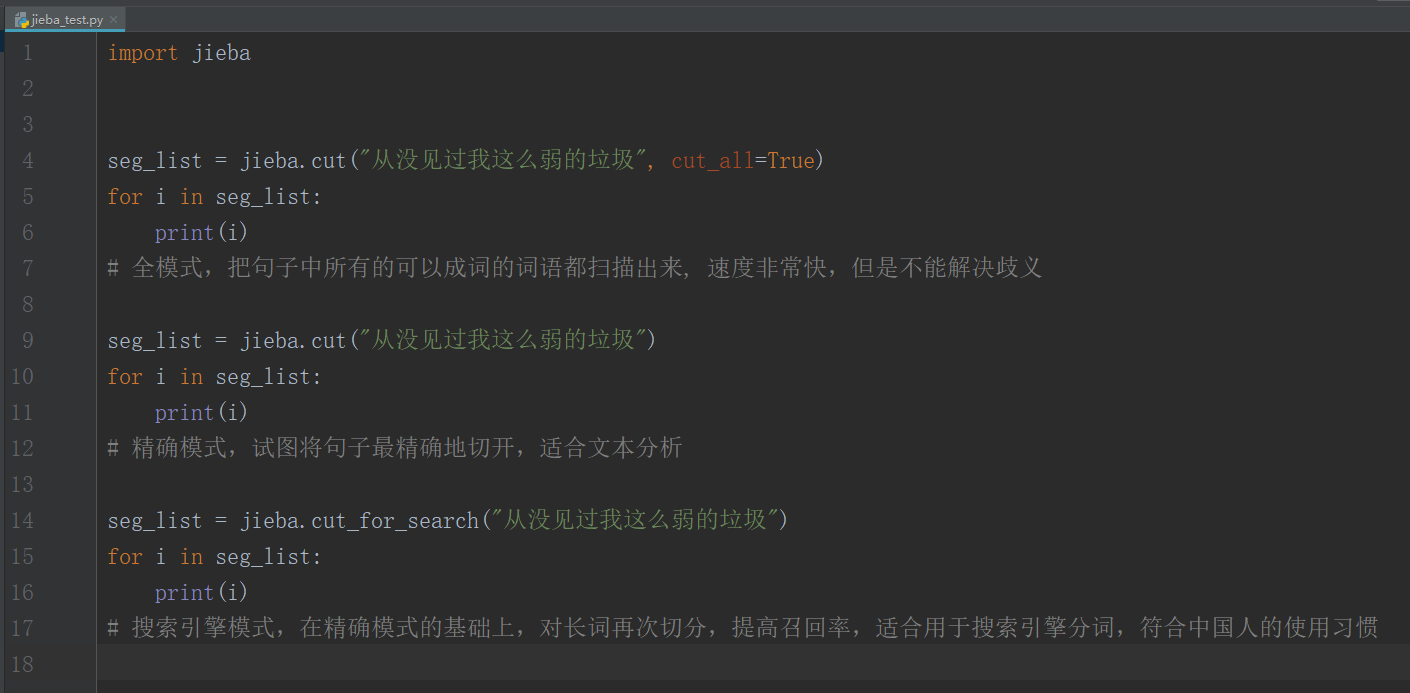
import jieba
seg_list = jieba.cut("从没见过我这么弱的垃圾", cut_all=True)
for i in seg_list:
print(i)
# 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
seg_list = jieba.cut("从没见过我这么弱的垃圾")
for i in seg_list:
print(i)
# 精确模式,试图将句子最精确地切开,适合文本分析
seg_list = jieba.cut_for_search("从没见过我这么弱的垃圾")
for i in seg_list:
print(i)
# 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,符合中国人的使用习惯
打印结果:
从没
没见
过
我
这么
弱
的
垃圾
从没
见
过
我
这么
弱
的
垃圾
从没
见
过
我
这么
弱
的
垃圾
jieba.cut 方法接受三个输入参数:
1、需要分词的字符串;
2、cut_all 参数用来控制模式,
cut_all=True or False,
默认为False(精确模式);
3、HMM 参数用来控制是否使用HMM模型,
HMM=True or False,
默认为True(新词识别)。
jieba.cut_for_search 方法接受两个参数:
1、需要分词的字符串;
2、是否使用 HMM 模型。
该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的generator,
可以使用 for 循环来获得分词后得到的每一个词语(unicode),
或者用
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
二、添加自定义的词典:
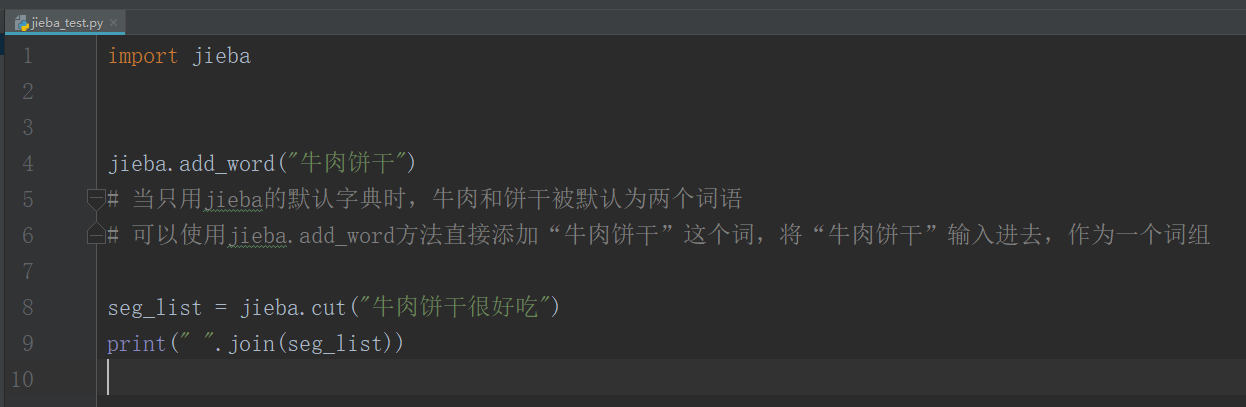
import jieba
jieba.add_word("牛肉饼干")
# 当只用jieba的默认字典时,牛肉和饼干被默认为两个词语
# 可以使用jieba.add_word方法直接添加“牛肉饼干”这个词,将“牛肉饼干”输入进去,作为一个词组
seg_list = jieba.cut("牛肉饼干很好吃")
print(" ".join(seg_list))
打印结果:
牛肉饼干 很 好吃
还可以这样写:
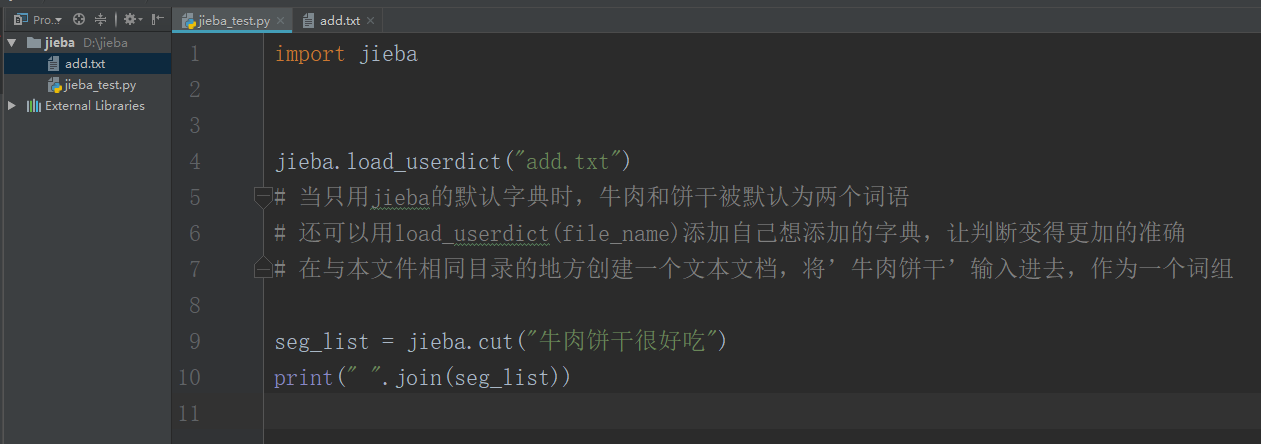
import jieba
jieba.load_userdict("add.txt")
# 当只用jieba的默认字典时,牛肉和饼干被默认为两个词语
# 还可以用load_userdict(file_name)添加自己想添加的字典,让判断变得更加的准确
# 在与本文件相同目录的地方创建一个文本文档,将’牛肉饼干’输入进去,作为一个词组
seg_list = jieba.cut("牛肉饼干很好吃")
print(" ".join(seg_list))
打印结果:
牛肉饼干 很 好吃
三、调整词典:
import jieba
jieba.suggest_freq(("垃", "圾"), tune=True)
# 使用suggest_freq(segment, tune=True)可调节单个词语的词频
# 使其能(或不能)被分出来,默认为False
# “垃圾”原为一个词,这样可以可以拆分为"垃"、"圾"两个词
seg_list = jieba.cut("从没见过我这么弱的垃圾", HMM=False)
# 注意:自动计算的词频在使用HMM新词发现功能时可能无效
print(" ".join(seg_list))
打印结果:
从没 见 过 我 这么 弱 的 垃 圾 补充:
1、文件名不可命令为jieba.py
否则会报错:
AttributeError: module 'jieba' has no attribute 'cut' 2、join()方法:
连接字符串数组,
将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
jieba结巴分词的更多相关文章
- Python3.7+jieba(结巴分词)配合Wordcloud2.js来构造网站标签云(关键词集合)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_138 其实很早以前就想搞一套完备的标签云架构了,迫于没有时间(其实就是懒),一直就没有弄出来完整的代码,说到底标签对于网站来说还是 ...
- solr+jieba结巴分词
为什么选择结巴分词 分词效率高 词料库构建时使用的是jieba (python) 结巴分词Java版本 下载 git clone https://github.com/huaban/jieba-ana ...
- python调用jieba(结巴)分词 加入自定义词典和去停用词功能
把语料从数据库提取出来以后就要进行分词啦,我是在linux环境下做的,先把jieba安装好,然后找到内容是build jieba PKG-INFO setup.py test的那个文件夹(我这边是ji ...
- 结巴(jieba)分词
一.介绍: jieba: “结巴”中文分词:做最好的 Python 中文分词组件 “Jieba” (Chinese for “to stutter”) Chinese text segmentatio ...
- python 结巴分词(jieba)详解
文章转载:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931 jieba “结巴”中文分词:做最好的 Python 中文分词组件 ...
- jieba GitHUb 结巴分词
1.GitHub jieba-analysis 结巴分词: https://github.com/fxsjy/jieba 2.jieba-analysis 结巴分词(java版): https://g ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
- 结巴分词 java 高性能实现,是 huaban jieba 速度的 2倍
Segment Segment 是基于结巴分词词库实现的更加灵活,高性能的 java 分词实现. 变更日志 创作目的 分词是做 NLP 相关工作,非常基础的一项功能. jieba-analysis 作 ...
- 模块 jieba结巴分词库 中文分词
jieba结巴分词库 jieba(结巴)是一个强大的分词库,完美支持中文分词,本文对其基本用法做一个简要总结. 安装jieba pip install jieba 简单用法 结巴分词分为三种模式:精确 ...
随机推荐
- 4.spring:@Profile,AOP
Profile: 可以根据当前的环境,动态激活和切换一系列的组件功能 指定组件在那个环境下才能被注册到容器中,不指定任何环境下都能注册到 1.加了环境标识的bean只有环境激活的时候才能注册到容器中 ...
- jquery基础介绍-转
学习目的:理解 Ajax 及其工作原理,构建网站的一种有效方法. Ajax 是 Asynchronous JavaScript and XML(以及 DHTML 等)的缩写. 下面是 Ajax 应用程 ...
- form表单上传文件
一.formData()直接获取form表单数据 例子:获取form表单的id给formData(),然后传给后台. 要求: 传入值的name值必须与后台接受的name相对应. form表单不能嵌套, ...
- C#通过指针读取文件
// readfile.cs // 编译时使用:/unsafe // 参数:readfile.txt // C#通过指针读取文件.使用该程序读并显示文本文件. using System; using ...
- git提交项目
https://www.cnblogs.com/java-maowei/p/5950930.html
- HDU 1024 Max Sum Plus Plus(m个子段的最大子段和)
传送门:http://acm.hdu.edu.cn/showproblem.php?pid=1024 Max Sum Plus Plus Time Limit: 2000/1000 MS (Java/ ...
- Go 语言开始
尝试了LiteIDE碰到调试问题无法解决,只有换成了vscode. vscode有个问题, golang.org/x/ 这个包名下的包都下载不了,需要到 https://github.com/gola ...
- NHibernate学习过程笔记
NHbernate自动生成数据库的方法: using NHibernate; using NHibernate.Tool.hbm2ddl; namespace Test { public class ...
- js判断值是不是全是数字
if(isNaN(value)){ 不是数字 }else{ 全是数字 }
- 课时22.br标签(掌握)
br标签,如何在html中换行,可以使用br标签 1.br标签的作用:换行 2.br标签的格式:<br> 3.br标签的注意点: 3.1多个br标签可以连续使用,使用了多个br标签就会换多 ...