Node大文件处理
之前有个需求要将文件解析再处理,当时直接将整个文件内容读到内存中然后解析,也是没有考虑到大文件的问题,那么要如何解析大文件呢?
输入:文件的内容是多个json,按顺序排列
输出:解析后的json数据
代码:
let fs = require('fs');
let log = (str) => { console.log(`${new Date().toLocaleString()} ${str}`); };
let readStream = fs.createReadStream('./input.txt', {encoding: 'utf-8'});
let chunkTotal = '',
res = [],
reg = /(}\s*{)/g;
console.time('parse');
readStream.on('readable', () => {
log('readable triggerd');
let chunk;
while ((chunk = readStream.read()) !== null) {
log(`read triggerd, chunk length ${chunk.length}, current res length ${res.length}`);
chunkTotal += chunk;
let regRes, matchedIndex = 0, srcIndex = 0;
while ((regRes = reg.exec(chunkTotal))) {
matchedIndex = regRes.index;
let json = chunkTotal.slice(srcIndex, matchedIndex + 1);
try {
res.push(JSON.parse(json.trim()));
} catch (e) {
console.log(json);
}
srcIndex = matchedIndex + 1;
}
chunkTotal = chunkTotal.slice(matchedIndex + 1).trim();
}
let json;
try {
json = JSON.parse(chunkTotal.trim());
res.push(json);
chunkTotal = '';
} catch (e) {}
});
readStream.on('end', () => {
log(`总共编译得到数据:${res.length}个`);
console.timeEnd('parse');
});
实际运行过程中发现程序越跑越慢:
当解析到100多w条json数据时,慢的不能忍
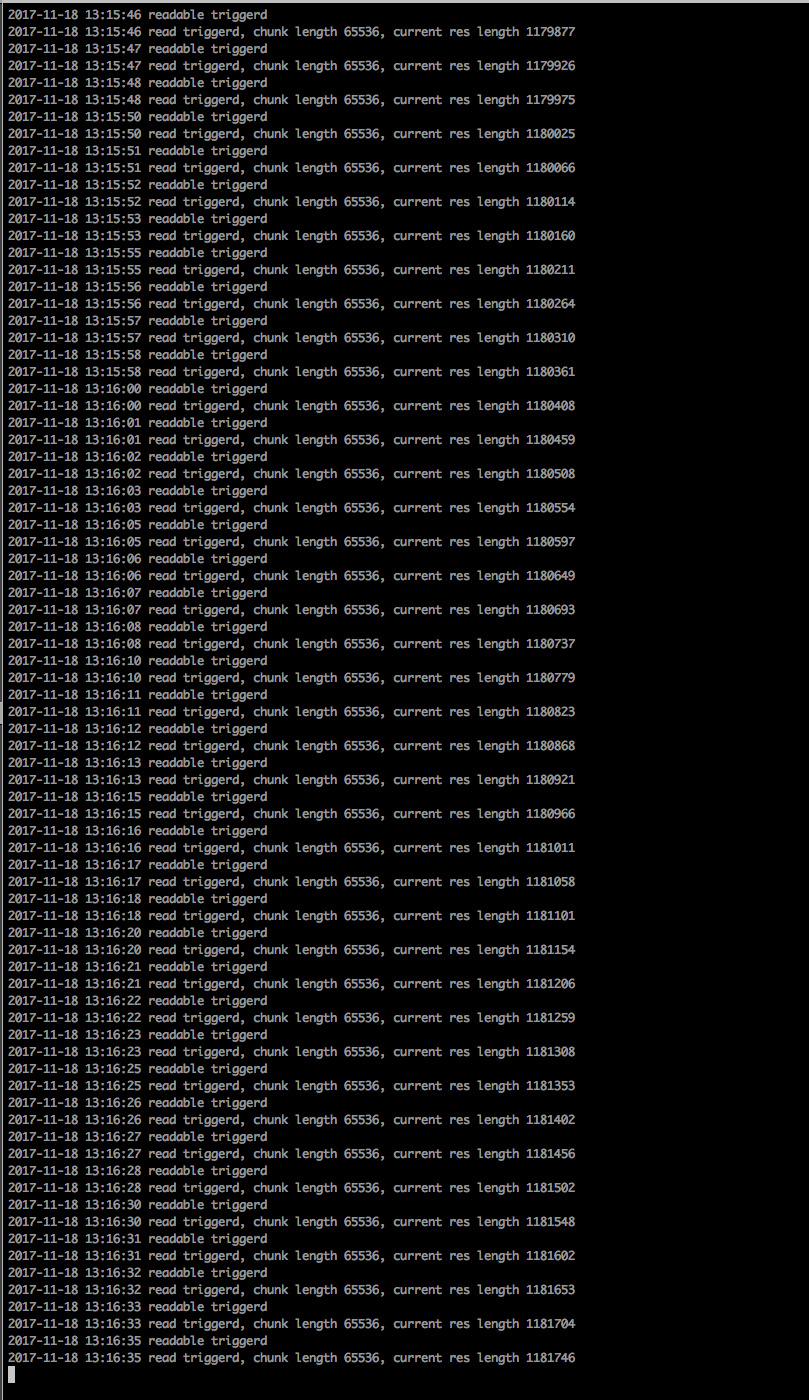
当把代码改成只统计能解析得到的json数量,不保存json数据后,代码就嗖嗖的跑完了。
难道是因为占用内存过高,影响垃圾回收速度?
能不能利用多进程来处理一个大文件?
原因是正则的问题导致效率下降,按行读取还是用readline比较好
Node大文件处理的更多相关文章
- Node + js实现大文件分片上传基本原理及实践(一)
_ 阅读目录 一:什么是分片上传? 二:理解Blob对象中的slice方法对文件进行分割及其他知识点 三. 使用 spark-md5 生成 md5文件 四. 使用koa+js实现大文件分片上传实践 回 ...
- node压缩文件夹
前几天遇到一个需求,将一个10G的文件夹打包压缩,并去除黑名单上的文件. node自带的只能压缩文件.网上看了集中方案要么对大文件操作不行,要么只能直接操作文件夹,无法对文件夹遍历筛选. 后来确定使用 ...
- 算法初级面试题05——哈希函数/表、生成多个哈希函数、哈希扩容、利用哈希分流找出大文件的重复内容、设计RandomPool结构、布隆过滤器、一致性哈希、并查集、岛问题
今天主要讨论:哈希函数.哈希表.布隆过滤器.一致性哈希.并查集的介绍和应用. 题目一 认识哈希函数和哈希表 1.输入无限大 2.输出有限的S集合 3.输入什么就输出什么 4.会发生哈希碰撞 5.会均匀 ...
- XMLREADER/DOM/SIMPLEXML 解析大文件
DOM和simplexml处理xml非常的灵活方便,它们的内存组织结构与xml文件格式很相近.但是同时它们也有一个缺点,对于大文件处理起来力不从心,太耗内存了. 还好有xmlreader,基于流的解析 ...
- nodeJs + js 大文件分片上传
简单的文件上传 一.准备文件上传的条件: 1.安装nodejs环境 2.安装vue环境 3.验证环境是否安装成功 二.实现上传步骤 1.前端部分使用 vue-cli 脚手架,搭建一个 demo 版本, ...
- 大文件上传FTP
需求 将本地大文件通过浏览器上传到FTP服务器. 原有方法 将本地文件整个上传到浏览器,然后发送到node服务器,最后由node发送到FTP服务器. 存在问题 浏览器缓存有限且上传速率受网速影响,当文 ...
- 用Node处理文件上传
前言 在Web开发中,文件上传是一个非常常见.非常重要的功能.本文将介绍如何用Node处理上传的文件. 需求分析 由于现在前后端分离很流行,那么本文也直接采用前后端分离的做法.前端界面如下: 用户从浏 ...
- PHP搭建大文件切割分块上传功能
背景 在网站开发中,文件上传是很常见的一个功能.相信很多人都会遇到这种情况,想传一个文件上去,然后网页提示"该文件过大".因为一般情况下,我们都需要对上传的文件大小做限制,防止出现 ...
- Java中使用IO流实现大文件的分裂与合并
文件分割应该算一个比较实用的功能,举例子说明吧比如说:你有一个3G的文件要从一台电脑Copy到另一台电脑, 但是你的存储设备(比如SD卡)只有1G ,这个时候就可以把这个文件切割成3个1G的文件 ,分 ...
随机推荐
- SQL SERVER常见等待——解决会话等待产生的系统问题
SQL SERVER——解决会话等待产生的系统问题 转自: https://blog.csdn.net/z_cloud_for_SQL/article/details/55051215 版权声明:SQ ...
- DBA学习参考绝佳资料
原文来自:pursuer.chen 原文地址:https://www.cnblogs.com/chenmh/default.aspx?page=1 [置顶]MongoDB 文章目录 2018-02-0 ...
- 吴超老师课程--Pig的介绍和安装
1.Pig是基于hadoop的一个数据处理的框架. MapReduce是使用java进行开发的,Pig有一套自己的数据处理语言,Pig的数据处理过程要转化为MR来运行. 2.Pig的数据处理语言是数 ...
- iOS学习之二维码扫描
这几天刚好将本人高仿新浪微博的事情进行一个阶段性的tag,在此也将这个项目在实现二维码扫描这个功能来做一个简要的记录.关于高仿新浪微博的源代码,本人已经将全部代码托管到github,地址在这里.欢迎大 ...
- bootstrap圆角
圆角问题 这里为圆角, .;} 原因是我是用li 标签的line-height给他撑开的,所以会出现圆角,所以我没有定义side的background-color加上就好了 ...
- day9 文件的读取
文件操作 一.打开文件 f = open('歌词.txt','w',encoding='utf-8') # f:文件操作符 文件句柄 文件操作对象 open打开文件是依赖了操作系统提供的途径 操作系统 ...
- javascript DOM dindow.docunment对象
一.找到元素: docunment.getElementById("id"):根据id找,最多找一个: var a =docunment.getElementById(&qu ...
- c#基础-自动内存管理
1.自动垃圾回收是什么? 在非托管环境下程序员要自已管理内存,由疏忽的原因,通常会犯两种错误,请求内存后在不使用时忘记释放,或使用已经释放了的内存.但在托管环境下,程序员不用担心这两个问题,C ...
- 最小可用 Spring MVC 配置
[最小可用 Spring MVC 配置] 1.导入有概率用到的JAR包, -> pom.xml 的更佳实践 - 1.0 <- <project xmlns="http:// ...
- Mahout 分类算法
实验简介 本次课程学习了Mahout 的 Bayes 分类算法. 一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名 shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu ...