Lucene第一讲——概述与入门
一、概述
1.什么是Lucene?
Lucene是apache下的一个开源的全文检索引擎工具包。
它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现全文检索的功能。
2.能干什么?
主要运用:全文检索
3.全文检索定义
全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
二、实现流程
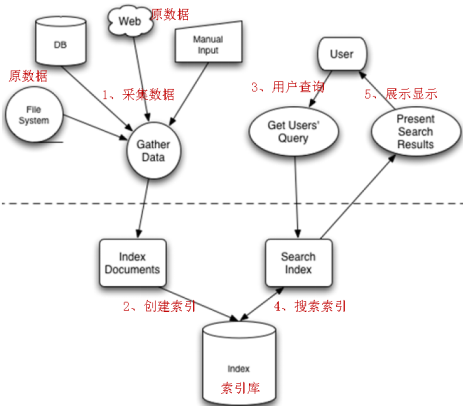
流程主要分为:索引流程 搜索流程
三、入门程序
1.准备数据(数据库)

2.引入依赖(使用maven)
<!--版本管理-->
<properties>
<lucene.version>5.3.1</lucene.version>
<junit.version>4.12</junit.version>
</properties>
<dependencies>
<!-- lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- lucene-query-parser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency> <dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
//使用数据库作为数据源请添加数据库依赖
3.其它:如JDK(7及以上),mysql等不再赘述
4.索引流程
1.为什么采集数据
全文检索搜索的内容的格式是多种多样的,比如:视频、mp3、图片、文档等等。对于这种格式不同的数据,需要先将他们采集到本地,然后统一封装到lucene的文档对象中,也就是说需要将存储的内容进行统一才能对它进行查询。
2.采集数据的方式
l 对于互联网中的数据,使用爬虫工具(http工具)将网页爬取到本地
l 对于数据库中的数据,使用jdbc程序进行数据采集
l 对于文件系统的数据,使用io流采集
常用数据采集爬虫工具(了解):
Solr(http://lucene.apache.org/solr) ,solr是apache的一个子项目,支持从关系数据库、xml文档中提取原始数据。
Nutch(http://lucene.apache.org/nutch), Nutch是apache的一个子项目,包括大规模爬虫工具,能够抓取和分辨web网站数据。
jsoup(http://jsoup.org/ ),jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
heritrix(http://sourceforge.net/projects/archive-crawler/files/),Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
3.索引文件逻辑结构
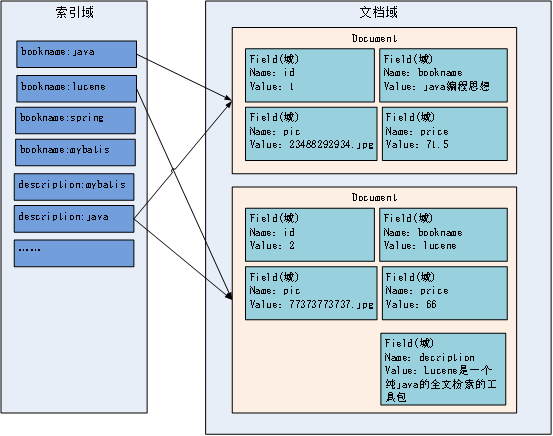
与字典的 结构类似,一边目录一边文档,目录是索引域,文档是lucene封装的统一文档格式
文档域
文档域存储的信息就是采集到的信息,通过Document对象来存储,具体说是通过Document对象中field域来存储数据。
比如:数据库中一条记录会存储一个一个Document对象,数据库中一列会存储成Document中一个field域。
文档域中,Document对象之间是没有关系的。而且每个Document中的field域也不一定一样。
索引域
索引域主要是为了搜索使用的。索引域内容是经过lucene分词之后存储的。
倒排索引表
传统方法是先找到文件,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢。
倒排索引结构是根据内容(词语)找文档,倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,找到了索引中的词汇,词汇与文档关联,从而最终找到了文档。

5.索引
1.采集数据
对应上文数据库的PO类:
package com.itheima.lucene.po; /**
*
* <p>
* Title: Book
* </p>
*
* <p>
* Description: TODO(这里用一句话描述这个类的作用)
* <p>
* <p>
* Company: www.itcast.com
* </p>
* @author 传智.关云长 @date 2015-12-27 上午10:03:11 @version 1.0
*/
public class Book {
// 图书ID
private Integer id;
// 图书名称
private String name;
// 图书价格
private Float price;
// 图书图片
private String pic;
// 图书描述
private String description;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Float getPrice() {
return price;
}
public void setPrice(Float price) {
this.price = price;
}
public String getPic() {
return pic;
}
public void setPic(String pic) {
this.pic = pic;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
} }
使用传统JDBC从数据库采集数据进行封装:
package com.itheima.lucene.dao; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List; import com.itheima.lucene.po.Book; /**
*
* <p>
* Title: BookDaoImpl
* </p>
*
* <p>
* Description: TODO(这里用一句话描述这个类的作用)
* <p>
* <p>
* Company: www.itcast.com
* </p>
* @author 传智.关云长 @date 2015-12-27 上午10:04:30 @version 1.0
*/
public class BookDaoImpl implements BookDao { @Override
public List<Book> queryBooks() {
// 数据库链接
Connection connection = null; // 预编译statement
PreparedStatement preparedStatement = null; // 结果集
ResultSet resultSet = null; // 图书列表
List<Book> list = new ArrayList<Book>(); try {
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 连接数据库
connection = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/solr", "root", "root"); // SQL语句
String sql = "SELECT * FROM book";
// 创建preparedStatement
preparedStatement = connection.prepareStatement(sql); // 获取结果集
resultSet = preparedStatement.executeQuery(); // 结果集解析
while (resultSet.next()) {
Book book = new Book();
book.setId(resultSet.getInt("id"));
book.setName(resultSet.getString("name"));
book.setPrice(resultSet.getFloat("price"));
book.setPic(resultSet.getString("pic"));
book.setDescription(resultSet.getString("description"));
list.add(book);
} } catch (Exception e) {
e.printStackTrace();
} return list;
} }
2.创建索引
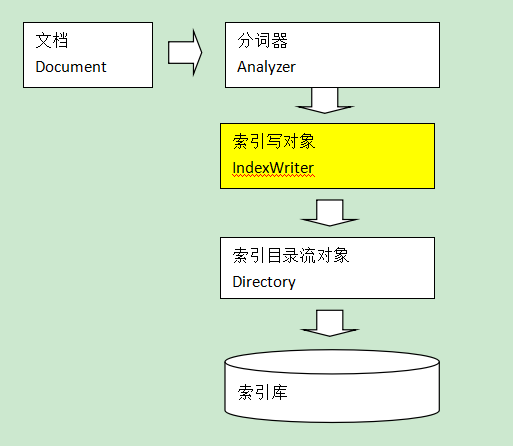
Document就是封装数据的文档对象
IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
创建索引过程:
// 采集数据 // 将采集到的数据封装到Document对象中 // 创建分词器,标准分词器 // 创建IndexWriter
// 指定索引库的地址 // 通过IndexWriter对象将Document写入到索引库中 // 关闭writer
package com.itheima.lucene.first; import java.io.File;
import java.util.ArrayList;
import java.util.List; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.FloatField;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; import com.itheima.lucene.dao.BookDao;
import com.itheima.lucene.dao.BookDaoImpl;
import com.itheima.lucene.po.Book; /**
*
* <p>
* Title: IndexManager
* </p>
*
* <p>
* Description: TODO(这里用一句话描述这个类的作用)
* <p>
* <p>
* Company: www.itcast.com
* </p>
* @author 传智.关云长 @date 2015-12-27 上午10:08:12 @version 1.0
*/
public class IndexManager { @Test
public void createIndex() throws Exception {
// 采集数据
BookDao dao = new BookDaoImpl();
List<Book> list = dao.queryBooks(); // 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<>();
Document document;
for (Book book : list) {
document = new Document();
// store:如果是yes,则说明存储到文档域中
// 图书ID
// 不分词、索引、存储 StringField
Field id = new StringField("id", book.getId().toString(), Store.YES);
// 图书名称
// 分词、索引、存储 TextField
Field name = new TextField("name", book.getName(), Store.YES);
// 图书价格
// 分词、索引、存储 但是是数字类型,所以使用FloatField
Field price = new FloatField("price", book.getPrice(), Store.YES);
// 图书图片地址
// 不分词、不索引、存储 StoredField
Field pic = new StoredField("pic", book.getPic());
// 图书描述
// 分词、索引、不存储 TextField
Field description = new TextField("description",
book.getDescription(), Store.NO); // 设置boost值
if (book.getId() == 4)
description.setBoost(100f); // 将field域设置到Document对象中
document.add(id);
document.add(name);
document.add(price);
document.add(pic);
document.add(description); docList.add(document);
} // 创建分词器,标准分词器
// Analyzer analyzer = new StandardAnalyzer();
// 使用ikanalyzer
Analyzer analyzer = new IKAnalyzer(); // 创建IndexWriter
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_4_10_3,
analyzer);
// 指定索引库的地址
File indexFile = new File("E:\\11-index\\hm19\\");
Directory directory = FSDirectory.open(indexFile);
IndexWriter writer = new IndexWriter(directory, cfg); // 通过IndexWriter对象将Document写入到索引库中
for (Document doc : docList) {
writer.addDocument(doc);
} // 关闭writer
writer.close();
} @Test
public void deleteIndex() throws Exception {
// 创建分词器,标准分词器
Analyzer analyzer = new StandardAnalyzer(); // 创建IndexWriter
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_4_10_3,
analyzer);
Directory directory = FSDirectory
.open(new File("E:\\11-index\\hm19\\"));
// 创建IndexWriter
IndexWriter writer = new IndexWriter(directory, cfg); // Terms
// writer.deleteDocuments(new Term("id", "1")); // 删除全部(慎用)
writer.deleteAll(); writer.close();
} @Test
public void updateIndex() throws Exception {
// 创建分词器,标准分词器
Analyzer analyzer = new StandardAnalyzer(); // 创建IndexWriter
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_4_10_3,
analyzer); Directory directory = FSDirectory
.open(new File("E:\\11-index\\hm19\\"));
// 创建IndexWriter
IndexWriter writer = new IndexWriter(directory, cfg); // 第一个参数:指定查询条件
// 第二个参数:修改之后的对象
// 修改时如果根据查询条件,可以查询出结果,则将以前的删掉,然后覆盖新的Document对象,如果没有查询出结果,则新增一个Document
// 修改流程即:先查询,再删除,在添加
Document doc = new Document();
doc.add(new TextField("name", "lisi", Store.YES));
writer.updateDocument(new Term("name", "zhangsan"), doc); writer.close();
}
}
模拟:
package com.itheima.lucene; import com.itheima.lucene.PO.Book;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List; /**
* Lucene的入门程序
* 作者: Administrator
* 日期: 2017/9/6
**/
public class LuceneFirst { public static void main(String[] args) throws IOException {
// 模拟采集数据
List<Book> bookList = new ArrayList<>();
Book book1 = new Book(1, "java", 100f, "pic1", "java入门书籍");
Book book2 = new Book(2, "C", 100.6f, "pic2", "C语言入门书籍");
Book book3 = new Book(3, "python", 90.7f, "pic3", "python入门书籍");
bookList.add(book1);
bookList.add(book2);
bookList.add(book3); // 封装数据到Document对象中
List<Document> docList = new ArrayList<>();
Document doc;
for (Book book : bookList) {
doc = new Document();
// 创建文档中的Field域,Store可以确定是否存储到文档域中
Field idField = new TextField("id", book.getId().toString(), Field.Store.YES);
Field nameField = new TextField("name", book.getName(), Field.Store.YES);
Field priceField = new TextField("price", book.getPrice().toString(), Field.Store.YES);
Field picField = new TextField("pic", book.getPic(), Field.Store.YES);
Field descriptionField = new TextField("description", book.getDescription(), Field.Store.YES);
// 将域放入文档中
doc.add(idField);
doc.add(nameField);
doc.add(priceField);
doc.add(picField);
doc.add(descriptionField);
// 将文档放入文档列表
docList.add(doc);
}
// 创建分词器
Analyzer analyzer = new StandardAnalyzer();
// 创建IndexWriter
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
String path = "D:\\BdiduYunDownload\\lucene\\index";
Directory dir = FSDirectory.open(Paths.get(path));
IndexWriter indexWriter = new IndexWriter(dir, conf); // 通过索引写对象将docList写入索引库
for (Document document : docList) {
indexWriter.addDocument(document);
}
// 流的关闭
indexWriter.close();
}
}
索引文件:

6.分词过程
Lucene中分词主要分为两个步骤:分词、过滤
分词:将field域中的内容一个个的分词。
过滤:将分好的词进行过滤,比如去掉标点符号、大写转小写、词的型还原(复数转单数、过去式转成现在式)、停用词过滤(没有去重过滤)
停用词:单独应用没有特殊意义的词。比如的、啊、等,英文中的this is a the等等。
分词示例讲解:
要分词的内容
Lucene is a Java full-text search engine. 分词
Lucene
is
a
Java
Full
-
text
search
engine
. 过滤 去掉标点符号
Lucene
is
a
Java
Full
text
search
engine 去掉停用词
Lucene
Java
Full
text
search
engine 大写转小写
lucene
java
full
text
search
engine
语汇单元生成过程:
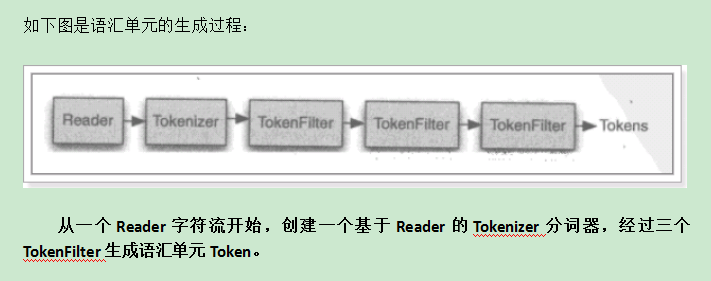
同一个域中相同的语汇单元(Token)对应同一个Term(词),它记录了语汇单元的内容及所在域的域名等,还包括来该token出现的频率及位置。
不同的域中拆分出来的相同的单词对应不同的term。
相同的域中拆分出来的相同的单词对应相同的term。
例如:图书信息里面,图书名称中的java和图书描述中的java对应不同的term
使用luke工具可以查看索引信息
7.搜索流程
1.输入查询语句
同数据库的sql一样,lucene全文检索也有固定的语法:
最基本的有比如:AND, OR, NOT 等
举个例子,用户想找一个description中包括java关键字和lucene关键字的文档。
它对应的查询语句:description:java AND lucene
2.搜索流程:

3.代码实现:
package com.itheima.lucene.first; import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test; /**
*
* <p>
* Title: IndexSearch
* </p>
*
* <p>
* Description: TODO(这里用一句话描述这个类的作用)
* <p>
* <p>
* Company: www.itcast.com
* </p>
* @author 传智.关云长 @date 2015-12-27 上午11:05:35 @version 1.0
*/
public class IndexSearch { private void doSearch(Query query) {
// 创建IndexSearcher
// 指定索引库的地址
try {
File indexFile = new File("E:\\11-index\\hm19\\");
Directory directory = FSDirectory.open(indexFile);
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = searcher.search(query, 10); // 根据查询条件匹配出的记录总数
int count = topDocs.totalHits;
System.out.println("匹配出的记录总数:" + count);
// 根据查询条件匹配出的记录
ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档的ID
int docId = scoreDoc.doc; // 通过ID获取文档
Document doc = searcher.doc(docId);
System.out.println("商品ID:" + doc.get("id"));
System.out.println("商品名称:" + doc.get("name"));
System.out.println("商品价格:" + doc.get("price"));
System.out.println("商品图片地址:" + doc.get("pic"));
System.out.println("==========================");
// System.out.println("商品描述:" + doc.get("description"));
}
// 关闭资源
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
} @Test
public void indexSearch() throws Exception {
// 创建query对象
// 使用QueryParser搜索时,需要指定分词器,搜索时的分词器要和索引时的分词器一致
// 第一个参数:默认搜索的域的名称
QueryParser parser = new QueryParser("description",
new StandardAnalyzer()); // 通过queryparser来创建query对象
// 参数:输入的lucene的查询语句(关键字一定要大写)
Query query = parser.parse("description:java AND lucene"); doSearch(query); } @Test
public void termQuery() {
// 创建TermQuery对象
Query query = new TermQuery(new Term("description", "java")); doSearch(query);
} @Test
public void numericRangeQuery() { // 创建NumericRangeQuery对象
// 参数:域的名称、最小值、最大值、是否包含最小值、是否包含最大值
Query query = NumericRangeQuery.newFloatRange("price", 55f, 60f, true,
false); doSearch(query);
} @Test
public void booleanQuery() {
// 创建BooleanQuery
BooleanQuery query = new BooleanQuery();
// 创建TermQuery对象
Query q1 = new TermQuery(new Term("description", "lucene"));
// 创建NumericRangeQuery对象
// 参数:域的名称、最小值、最大值、是否包含最小值、是否包含最大值
Query q2 = NumericRangeQuery.newFloatRange("price", 55f, 60f, true,
false); // 组合关系代表的意思如下:
// 1、MUST和MUST表示“与”的关系,即“交集”。
// 2、MUST和MUST_NOT前者包含后者不包含。
// 3、MUST_NOT和MUST_NOT没意义
// 4、SHOULD与MUST表示MUST,SHOULD失去意义;
// 5、SHOUlD与MUST_NOT相当于MUST与MUST_NOT。
// 6、SHOULD与SHOULD表示“或”的概念。 query.add(q1, Occur.MUST_NOT);
query.add(q2, Occur.MUST_NOT); doSearch(query);
} @Test
public void multiFieldQueryParser() throws Exception {
// 创建7.3.2 MultiFieldQueryParser
// 默认搜索的多个域的域名
String[] fields = { "name", "description" };
Analyzer analyzer = new StandardAnalyzer();
Map<String, Float> boosts = new HashMap<String, Float>();
boosts.put("name", 200f);
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields,
analyzer, boosts); // Query query = parser.parse("name:lucene OR description:lucene");
Query query = parser.parse("java"); System.out.println(query); doSearch(query);
}
}
QueryParser实现:
package com.itheima.lucene; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; import java.io.IOException;
import java.nio.file.Paths; /**
* Lucene的搜索功能
* 作者: Administrator
* 日期: 2017/9/6
**/
public class LuceneSearch {
public static void main(String[] args) throws ParseException, IOException {
// 使用QueryParser 参数分别为默认搜索域与分词器
String f = "description";
Analyzer a = new StandardAnalyzer();
QueryParser parser = new QueryParser(f, a);
// 通过parser创建Query对象
String q = "description:java"; // 查询语句(Luncene语法)
Query query = parser.parse(q);
// 创建IndexSearcher
String path = "D:\\BdiduYunDownload\\lucene\\index";
Directory dir = FSDirectory.open(Paths.get(path));
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
// 通过searcher搜索,分别为查询对象和需要显示的条数
TopDocs topDocs = searcher.search(query, 10);
// 结果处理
int totalHits = topDocs.totalHits; // 总记录数
System.out.println("总记录数:"+totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs; // 经过打分的文档
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取doc的ID
int docID = scoreDoc.doc;
// 根据docID获取文档(类似数据库的一条记录)
Document doc = searcher.doc(docID);
System.out.println("ID为:"+doc.get("id"));
System.out.println("name为:"+doc.get("name"));
System.out.println("price为:"+doc.get("price"));
System.out.println("pic为:"+doc.get("pic"));
System.out.println("description为:"+doc.get("description"));
}
// 关闭reader
reader.close();
}
}
结果:

关于Lucene的更多详细介绍,请参见 xingoo 的随笔:http://www.cnblogs.com/xing901022/p/3933675.html
Lucene第一讲——概述与入门的更多相关文章
- jquery实战第一讲---概述及其入门实例
就在5月28号周四下午五点的时候,接到xxx姐姐的电话,您是xxx吗?准备一下,周五上午八点半去远洋面试,一路风尘仆仆,颠颠簸簸,由于小编晕车,带着晕晕乎乎的脑子,小编就稀里糊涂的去面试了,温馨提醒, ...
- Solr第一讲——概述与入门
一.solr介绍 1.什么是solr Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr可以独立运行在Jetty.Tomcat等这些Serv ...
- WebService第一天——概述与入门操作
一.概述 1.是什么 Web service是一个平台独立的,低耦合的,自包含的.基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准来描述.发布.发现.协调和配置这些 ...
- C语言_第一讲_C语言入门
一.C语言的简介 1.C语言是一个标准,而执行标准的时候产生的自动化程序则是编译器2.了解:1983年美国国家标准化歇会(ANSI)制定了C语言标准.C语言的特点:3.代码的可移植性(理想状态是代码可 ...
- c#委托事件入门--第一讲:委托入门
说起委托,有些刚刚入门c#的人感觉很高大上,没有接触过,但是其实很多人都用过Lambda表达式,实际上Lambda表达式就是一个委托. 关于委托入门有个大神写的很详细:张子阳的博客 C#中的委托和事 ...
- c#委托事件入门--第二讲:事件入门
上文 c#委托事件入门--第一讲:委托入门 中和大家介绍了委托,学习委托必不可少的就要说下事件.以下思明仍然从事件是什么.为什么用事件.怎么实现事件和总结介绍一下事件 1.事件是什么:. 1.1 NE ...
- CS193P - 2016年秋 第一讲 课程简介
Stanford 的 CS193P 课程可能是最好的 ios 入门开发视频了.iOS 更新很快,这个课程的最新内容也通常是一年以内发布的. 最新的课程发布于2016年春季.目前可以通过 iTunes ...
- [EntLib]微软企业库5.0 学习之路——第一步、基本入门
话说在大学的时候帮老师做项目的时候就已经接触过企业库了但是当初一直没明白为什么要用这个,只觉得好麻烦啊,竟然有那么多的乱七八糟的配置(原来我不知道有配置工具可以进行配置,请原谅我的小白). 直到去年在 ...
- [信息检索] 第一讲 布尔检索Boolean Retrieval
第一讲 布尔检索Boolean Retrieval 主要内容: 信息检索概述 倒排记录表 布尔查询处理 一.信息检索概述 什么是信息检索? Information Retrieval (IR) is ...
随机推荐
- June 24th 2017 Week 25th Saturday
Who is able to be egotistical needs to be strong too. 有本事任性的人,也要有本事坚强. What is egotistical? Is it th ...
- 如何理解 Learning to rank
转:http://hi.baidu.com/christole/item/23215e364d8418f896f88deb What is Rank? rank就是排序.IR中需要排序的问题很多,最常 ...
- 薄弱的交互页面之新浪微博到博客的储存型xss漏洞
首先分享一片博文到微博,然后 在微博评论xss code 最后回到博客点击举报就触发xss了 点击举报 Xss之2 首先还是分享一片博文到微博,然后评论xsscode 回到我的博客个人中心,查看评论 ...
- Sql去重一些技巧
下午的时候遇到点问题,Sql去重,简单的去重可以用 DISTINCT 关键字去重,不过,很多情况下用这个解决不了问题.重复的数据千变万化,例如:类似于qq.微信的最近联系人功能,读取这些数据肯定要和消 ...
- mac环境下安装posgreSQL,postGIS,pgrouting方法
费了九牛二虎之力,终于安装成功...都是mac的坑,好好的window环境多好,非要换mac环境,导致软件配置极其的麻烦,window的环境下配置会少很多事,自己惹的祸自己担着吧还是.换mac要慎重, ...
- crm动态载入js库
function load_script(url) { var xmlHTTPRequest; if (window.ActiveXObject) { xmlHTTPR ...
- C++ 全局变量不明确与 using namespace std 冲突
写了个汉诺塔,使用全局变量count来记录步数,结果Error:count不明确 #include <iostream> using namespace std; ; void hanoi ...
- 浮动产生的高度坍塌解决方法以及使用siblings()方法获取同级元素
高度坍塌:如果一个没有设置高度div里的元素都是浮动元素,这个时候就可能产生高度坍塌,因为div的高度都是普通元素撑起来的,div里的元素浮动之后,元素就会脱离文档流,所以父级的div高度就可能为零, ...
- 【2017年最新】 iOS面试题及答案
设计模式是什么? 你知道哪些设计模式,并简要叙述? 设计模式是一种编码经验,就是用比较成熟的逻辑去处理某一种类型的事情. 1). MVC模式:Model View Control,把模型 视图 控制器 ...
- RCF的简单使用教程以及什么是回调函数
RCF的使用教程 RCF(Remote Call Framework)是一个使用C++编写的RPC框架,在底层RCF支持多种传输实现方式(transport implementations). 包括T ...