Hive(3)-meta store和hdfs详解,以及JDBC连接Hive
一. Meta Store
使用mysql客户端登录hadoop100的mysql,可以看到库中多了一个metastore
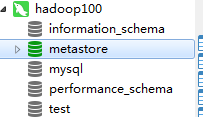
现在尤其要关注这三个表

DBS表,存储的是Hive的数据库

TBLS表,存储的是Hive中的表,使用DB_ID和DBS表关联

COLUMNS_V2存储的是每个表中的字段信息

Meta Store并不存储真实的数据,只是存储数据库的元数据信息,数据是存储在HDFS上的
二. HDFS
浏览器打开 http://hadoop100:50070/explorer.html#/ 在/目录下多了一个user目录

点进去

再点进去

再点进去

我们创建的表就出来了,难道没有人疑问default库哪里去了么?使用客户端,创建一个数据库~
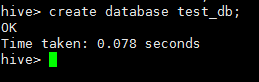
再刷新一下

所以,如果使用默认的default数据库,数据表将会放在hive/warehouse目录下.使用自定义的数据库,也会放在hive/warehouse目录下,再建表的话,会存到下一级目录下
其实这个目录,也是可以改的,修改conf/hive-stie.xml
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
三. JDBC连接Hive
1. 启动hiveserver2服务
bin/hiveserver2

阻塞是正常的,不要以为没起来...不想阻塞的话,可以使用后台守护的方式启动,bin/hiveserver2 & 加一个&符号
2.新开一个ssh窗口,启动beeline
bin/beeline

3. 连接hiveserver2
!connect jdbc:hive2://hadoop102:10000

4.爱之初体验
show databases;

5.Hive常用交互命令,新开一个ssh客户端,在不使用jdbc连接的情况下操作
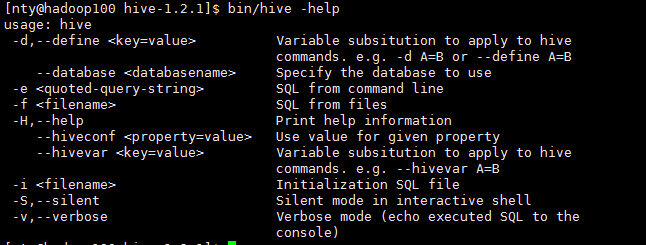
重点关注-e和-f参数,-e参数后面可以跟sql语句,-f参数后面可以跟一个sql文件

在opt/datas目录下新建一个sql文件,随便写条sql语句进去
select name from namelist;

6. 其他的一些操作
使用bin/hive连接,查看hdfs下的目录
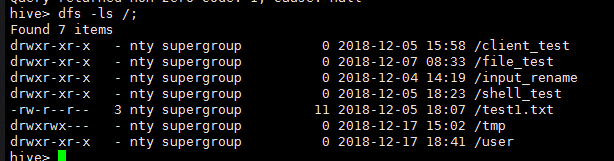
查看本地文件目录
四. 参数配置方式及优先级
1. 查看当前所有的配置信息
hive>set;
2. 参数的配置三种方式
1). 配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
2). 命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
例如:
bin/hive -hiveconf mapred.reduce.tasks=;
注意:仅对本次hive启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;
3). 参数声明方式
可以在HQL中使用SET关键字设定参数
例如:
hive (default)> set mapred.reduce.tasks=;
注意:仅对本次hive启动有效。
查看参数设置
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增,即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了
Hive(3)-meta store和hdfs详解,以及JDBC连接Hive的更多相关文章
- HDFS详解
HDFS详解大纲 Hadoop HDFS 分布式文件系统DFS简介 HDFS的系统组成介绍 HDFS的组成部分详解 副本存放策略及路由规则 命令行接口 Java接口 客户端与HDFS的数据流讲解 目标 ...
- Python API 操作Hadoop hdfs详解
1:安装 由于是windows环境(linux其实也一样),只要有pip或者setup_install安装起来都是很方便的 >pip install hdfs 2:Client——创建集群连接 ...
- OkHttp3源码详解(五) okhttp连接池复用机制
1.概述 提高网络性能优化,很重要的一点就是降低延迟和提升响应速度. 通常我们在浏览器中发起请求的时候header部分往往是这样的 keep-alive 就是浏览器和服务端之间保持长连接,这个连接是可 ...
- 通过JDBC连接hive
hive是大数据技术簇中进行数据仓库应用的基础组件,是其它类似数据仓库应用的对比基准.基础的数据操作我们可以通过脚本方式以hive-client进行处理.若需要开发应用程序,则需要使用hive的jdb ...
- 大数据学习day28-----hive03------1. null值处理,子串,拼接,类型转换 2.行转列,列转行 3. 窗口函数(over,lead,lag等函数) 4.rank(行号函数)5. json解析函数 6.jdbc连接hive,企业级调优
1. null值处理,子串,拼接,类型转换 (1) 空字段赋值(null值处理) 当表中的某个字段为null时,比如奖金,当你要统计一个人的总工资时,字段为null的值就无法处理,这个时候就可以使用N ...
- Hive metastore整体代码分析及详解
从上一篇对Hive metastore表结构的简要分析中,我再根据数据设计的实体对象,再进行整个代码结构的总结.那么我们先打开metadata的目录,其目录结构: 可以看到,整个hivemeta的目录 ...
- 【转】Hive配置文件中配置项的含义详解(收藏版)
http://www.aboutyun.com/thread-7548-1-1.html 这里面列出了hive几乎所有的配置项,下面问题只是说出了几种配置项目的作用.更多内容,可以查看内容问题导读:1 ...
- HTML中Meta属性http-equiv="X-UA-Compatible"详解
HTML下head中的http-equiv="X-UA-Compatible"详解: X-UA-Compatible是针对IE8新加的一个设置,对于IE8之外的浏览器是不识别的,这 ...
- Hive配置文件中配置项的含义详解(收藏版)
这里面列出了hive几乎所有的配置项,下面问题只是说出了几种配置项目的作用.更多内容,可以查看内容 问题导读: 1.hive输出格式的配置项是哪个? 2.hive被各种语言调用如何配置? 3.hive ...
随机推荐
- LearnHowToThink
一.BubbleSort and XListview 1.BubbleSort (1)analysis traverse.compare.exchange.cycle.optimize strateg ...
- Best Time to Buy and Sell Stock II--疑惑
https://oj.leetcode.com/problems/best-time-to-buy-and-sell-stock-ii/ 代码如下时能AC class Solution { publi ...
- svn merge error must be ancestrally related to,trunk merge branch报错
trunk merge branch的时候报错 xxx must be ancestrally related to xxx,这个报错的意思是两者不关联,所以需要去建立关联. [回顾背景] ...
- Oracle案例07——ORA-28000: the account is locked
遇到这个错误,一般我们想到的是数据库用户被锁,只需要执行用户解锁即可恢复,但这里之所以写出来是因为比较奇葩的一个问题. 昨天下午接同事信息,说一个用户连接报被锁,经过沟通发现其实连接一个ADG的备库作 ...
- springMVC+mybatis事务管理总结
1.spring,mybatis事务管理配置与@Transactional注解使用: 概述事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性.Spring Framewo ...
- Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本课主题 Spark Executor 工作原理图 ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕 Executor 具体是如何工作的 Spark Executor 工作 ...
- zt C++ list 类学习笔记
C++ list 类学习笔记 分类: C++ 2011-09-29 00:12 7819人阅读 评论(0) 收藏 举报 listc++iteratorvectorcconstructor 双向循环链表 ...
- 如何玩转Android远控(androrat)
关于WebView中接口隐患与手机挂马利用的引深 看我是怎样改造Android远程控制工具AndroRat 1.修改布局界面 2.配置默认远程ip和端口 3.LauncherActivity修改为运行 ...
- css3实现渐变
chrome,苹果浏览器:—webkit- firebox浏览器:-moz- Opera浏览器:-o- 渐变分为:线性渐变(Linear Gradients)向下/向上/向左/向右/对角方向 径向渐变 ...
- 一个几百行代码实现的http服务器tinyhttpd
/* J. David's webserver */ /* This is a simple webserver. * Created November 1999 by J. David Blacks ...