关于一个flask的服务接口实战(flask-migrate,flask-script,SQLAlchemy)
前言
最近接到一个接收前端请求的需求,需要使用python编写,之前没有写过python,很多技术没有用过,在这里做一个学习记录,如有错误,请不了赐教。
Flask Api文档管理
使用Falsk Api可以实现 文档是代码生成的,而不是靠人工维护,如果代码有任何改动,文档也能自动更新。这是一件非常优雅的事,但是对很多文档来说这并不现实,但是对于Api文档来说,实现成本并不高。
Falsk-RestPlus
对于Api来说,Flask-RestPlus是一个优秀的Api文档生成工具,这个包将会替换Flask路由层的编写方式,通过自己的语法来规定Api细节,并生成Api文档。
安装
pip install flask-restplus
这是一个demo
使用Flask-RestPlus时,需要按照这个库的方式编写Api层,包括request的参数解析,以及response的返回格式,一个hello world级的demo:
- from flask import Flask
- from flask_restplus import Resource,Api
- app = Flask(__name__)
- api = Api(app,prefix="/v1",title="Users",description="Users curd api.")
- @api.route("/users")
- class UserApi(Source):
- def get(self):
- return ("user":"")
- if __name__=="__main__":
- app.run()
效果图
实践
这里完成一个小小项目来实践和介绍Flask-RestPlus这个库,我们实现一个简单的图书馆订单系统,实现用户、图书和订单的CURD
Model
model可以理解为java中的实体类,大概就是用来描述一个实体的,里面定义了关于这个实体的一些信息。
这里的model和SQLAlchemy的model是不同的概念,这里是一种
用户model,包括id和username。而SQLAlchemy中的model则是用来描述数据库结构的。
- from flask import Flask, Blueprint
- from flask_restplus import Api, Resource, Namespace, fields
- import uuid
- import time
- class User(object):
- user_id = None
- username = None
- def __init__(self, username):
- self.user_id = str(uuid.uuid4())
- self.username = username
- class Book(object):
- book_id = None
- book_name = None
- price = None
- def __init__(self, book_name, book_price):
- self.book_id = str(uuid.uuid4())
- self.book_name = book_name
- self.price = book_price
- class Order(object):
- order_id = None
- user_id = None
- book_id = None
- created_at = None
- def __init__(self, user_id, book_id):
- self.order_id = str(uuid.uuid4())
- self.user_id = user_id
- self.book_id = book_id
- self.created_at = int(time.time())
- # 蓝图实例
- api_blueprint = Blueprint("api", __name__,url_prefix="/pages")
- #api实例
- api = Api(api_blueprint, version="1.0", description="THe Open Api Service")
- # namespace实例
- ns = Namespace("users", description="Users CURD api")
- ns2 = Namespace("Order",description="Order CURD api")
- # 将api实例添加到名字名字空间中
- api.add_namespace(ns)
- api.add_namespace(ns2)
- app = Flask(__name__)
- # 一定是最后app再向蓝图注册,不然会404
- app.register_blueprint(api_blueprint)
- # 定义model
- user_model = ns.model("UserModel", {
- "user_id": fields.String(readOnly=True, description="The user unique identifier"),
- "username": fields.String(required=True, description="The user nickname")
- })
- user_list_model = ns.model("UserListModel", {
- "users": fields.List(fields.Nested(user_model)),
- "total": fields.Integer
- })
- order_model = ns2.model("OrderModel", {
- "order_id": fields.String(readOnly=True,description="The oder unique identifier")
- })
- order_list_model = ns2.model("OrderListModel",{
- "order": fields.List(fields.Nested(order_model)),
- "total": fields.Integer
- })
- @ns.route("/")
- class UserListApi(Resource):
- users = [User("HanMeiMei"), User("LiLei")]
- @ns.doc("get_user_list")
- @ns.marshal_with(user_list_model)
- def get(self):
- return{
- "users": self.users
- }
- @ns2.route("/")
- class OrderApi(Resource):
- orders = [Order(1111,22222),Order(33333,4444)]
- @ns2.doc("get_order_list")
- @ns2.marshal_with(order_list_model)
- def get(self):
- return{
- "order":self.orders
- }
- if __name__ == "__main__":
- app.run(debug=True)
效果图
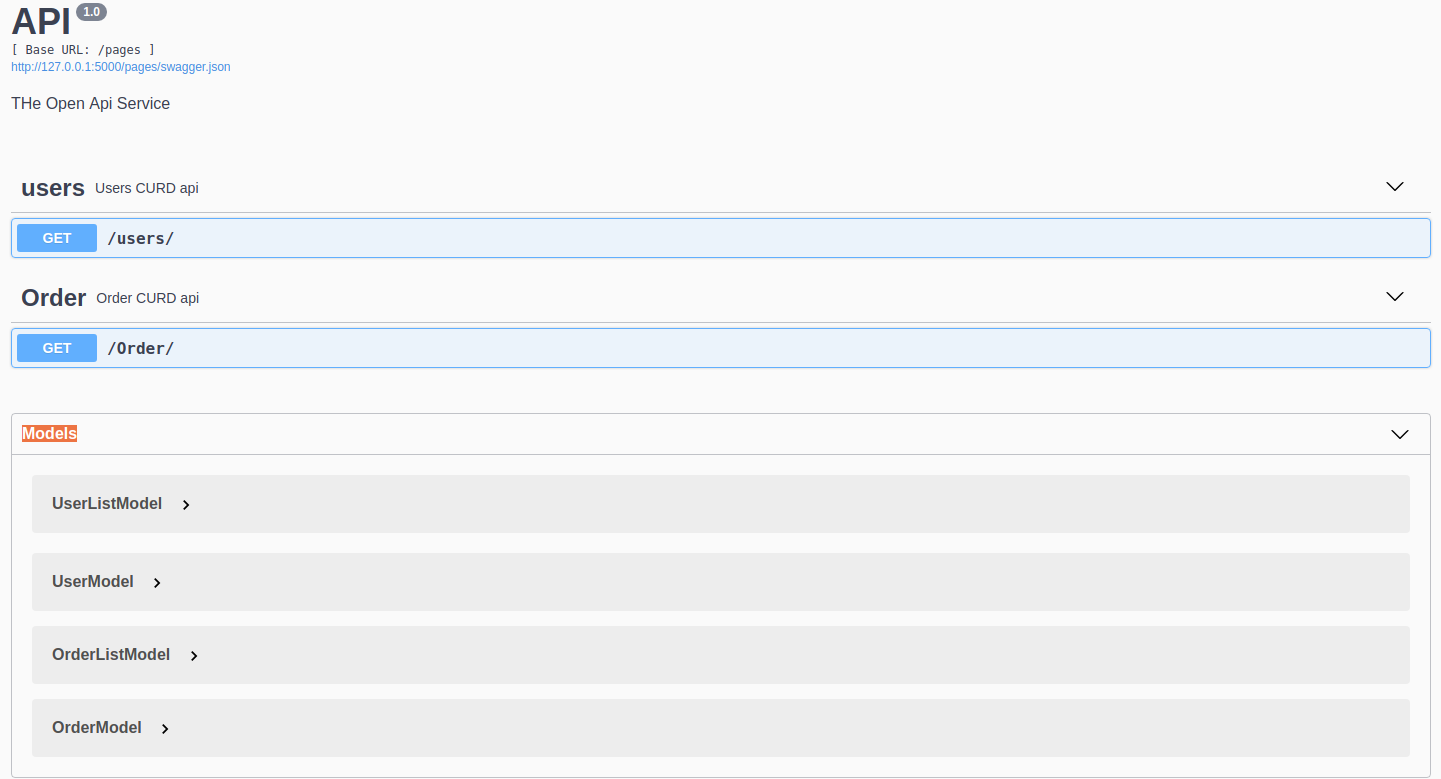
关于API,BluePrint,Namespace的关系:
整个这个界面就是Blueprint,在new Blueprint实例的时候可以指定一个prefix前缀,就是访问地址后面的加的东西,比如默认是127.0.0.1/prefix,prefix就是你自己定义的。这个不同的蓝图就是不同的url地址,生成不同的访问界面。
在这个界面中有一个Api实例,这个实例里可以定义一些model和Namespce,model比较简单,就是数据模型,用来形容数据格式的;namespce可以理解成不同的模块,比如spark中的SpakSQL和SparkStreaming就是不同的模块,那他们的api就要分开写。所以namespace里面就是不同模块下的api
注意点:通过上面对关系的理解,先编写的时候就要先生成Blueprint实例,然后向在生成api实例,同时生成api实例时,要告诉api实例,你要被放到哪个蓝图中去。在很大的项目中,可能会有很多蓝图。在生成api以后就是可以new Namespace实例了,给你的api划分不同的模块,生成的namespace肯定要和api实例建立联系,这时候就需要把namespace添加进api中,这样api就有了一个model,模块可以有很多个,置于多少完全根据你的心情来决定。最后,就需要向蓝图注册app实例,app是开启flask服务的关键。只有向蓝图注册了app,app.run的时候才会启动你设置好的url的视图,不然你访问api视图时,会出现404,这个在我刚学习的时候困扰了很久。
关于app.route("/"),app.route("/<string:username>")和app.route("/post/<username>")
第1个路由:捕获到 “/”,就进入函数进行处理,里面的函数叫做视图函数。URL从左到右第一个“/”为止一般 是首页,因此第1一个路由是处理首页。
第2个路由:捕获到 “/<username>” ,其中尖括号<....> 这一部分是动态可变的部分,其中不可以带有斜杠的。而且这个动态部分当做参数传递给了视图函数。
3个路由:捕获到 “/post/<int:post_id>” 其中 “/post/”是静态部分,“<int:post_id>”是动态部分,但是这个动态部分必须是个int类型的整数,同样其中不可以带有斜杠。同样这个动态部分也成为参数传入了视图函数show_post。这个rule是 <converter:name>的形式,而converter除了有int,还有float,path,string。
还有一个疑问:为什么写controller要继承Resource???
常用装饰器:
@ns.doc来标记这个 api 的作用@ns.marshal_with来标记如何渲染返回的 json@ns.expect来标记我们预期什么样子的 request@ns.response用来标记可能出现的 Response Status Code 并渲染在文档中@ns.param用来标记 URL 参数
以上就是关于Flask-restplus的介绍,没涉及什么原理和理论,仅仅限于使用的。
SQLAlchemy使用
先写一个小的demo:
- from flask_sqlalchemy import SQLAlchemy
- db = SQLAlchemy()
- class Address(db.Model):
- __tablename__ = "address"
- id = db.Column(db.Integer, primary_key=True)
- email_address = db.Column(db.String, nullable=False)
- user_id = db.Column(db.Integer, db.ForeignKey("users.id"))
- user = db.relationship("Users", db.backref("address", order_by=id))
Address是一个基类,用来维系类和数据库关系的目录,有些文章中Address的父类会用Base,Base=declarative_base()方法的返回值,实际上SQLAlchemy类中的Model属性就是通过这个方法构建的,所以本质上是Base和db.Model是一个东西。
primary_key,nullable这些就比较简单了,就是和定义传统数据库一样定义一个表而已。
ForeignKey表示,Address.user_id列的值应该等于users.id列中的值,即等于users的主键
relationship()方法,它告诉ORM,Address类本身应该使用属性Address.user链接到Users类,
relationship()参数中有一个backref()的realtionship()的子函数,是反向提供详细的信息,什么意思呢?如果没有设置backref这个属性,那么通过Address可以访问Users,即Address.user,这样就列出了有哪些地址对应一个用户,即多对一,但是不能通过Users.address来访问Address,不同反向的链接,如果设置了backref属性,就可以实现反向链接,即在User中添加User对应的Address对象的集合,保存在User.address中。
关于其他的一个查询操作大家可以看这篇文章:
Flask-Migrate实现数据库迁移
在开发过程中,你会发现有时需要修改数据库模型,而是修改之后还需要更新数据库,仅当数据库表不存在时,Flask-SQLAlichemy才会根据模型进行创建。因为,更新表的唯一方式就是先删除旧表,不过这样做会丢失数据库中的所有数据,更新表的更好方式是使用数据库迁移框架。源代码版本控制工具可以跟踪源码文件的变化,类似地,数据库迁移框架能跟踪数据库模型的变化,然后增量式的把变化应用到数据库中。
SQLAlchemy 的主力开发人员编写了一个迁移框架,称为Alembic(https://alembic.readthedocs.org/en/latest/index.html)。除了直接使用Alembic 之外,Flask 程序还可使用Flask-Migrate(http://flask-migrate.readthedocs.org/en/latest/)扩展。这个扩展对Alembic 做了轻量级包装,并集成到Flask-Script 中,所有操作都通过Flask-Script 命令完成。
一. 创建迁移仓库
首先,我们需要安装Flask-Migrate:
- pip install flask-migrate
Flask-Migrate的初始化方法如下:
- from flask-migrate import Migrate,MigrateCommand
- migrate = Migrate(app,db)
- //使用db作为MigrateCommand的命令启动
- manager.add_command('db',MigrateCommand)
为了导出数据库迁移命令,Flask-Migrate提供了一个MigrateCommand类,可以附加到Flask-Script的manager对象上,在这个例子中,MigrateCommand类使用db命令附加
在维护数据库迁移之前,要使用init子命令来创建迁移数据库:
- python hello.py db init
- Creating directory /home/flask/flask1/migrations ... done
- Creating directory /home/flask/flask1/migrations/versions ... done
- Generating /home/flask/flask1/migrations/env.pyc ... done
- Generating /home/flask/flask1/migrations/alembic.ini ... done
- Generating /home/flask/flask1/migrations/README ... done
- Generating /home/flask/flask1/migrations/script.py.mako ... done
- Generating /home/flask/flask1/migrations/env.py ... done
- Please edit configuration/connection/logging settings in
- '/home/flask/flask1/migrations/alembic.ini' before proceeding.
这个命令会创建migrations文件夹,所有迁移脚本都存放其中,数据库迁移仓库中的文件要和程序的其他文件一起纳入版本控制。
二.创建迁移脚本
在Alembic中,数据库迁移用迁移脚本表示,脚本中有两个函数,分别是upgrade()和downgrade().upgrade()函数把迁移中的改动应用到数据库中,downgrade()函数则是将改动删除,Alembic具有添加和删除改动的能力,因此数据库可以重设到历史的任意一点。
我们可以使用version命令收到创建Alembic迁移,也可使用migrate命令自动创建。手动创建的迁移只是一个骨架,upgrade()和downgrade()函数都是空的,开发者要使用Alembic提供的Operation对象指令实现具体操作。自动创建的迁移会根据模型定义和数据库当前状态之间的差异生成upgrade()和downgrade()函数的内容。自动创建的迁移不一定总是正确的,有可能会漏掉一些细节。自动生成迁移脚本后一定要进行检查。
migrate子命令用来自动创建迁移脚本:
- python hello.py db migrate -m "initial migration"
- INFO [alembic.runtime.migration] Context impl MySQLImpl.
- INFO [alembic.runtime.migration] Will assume non-transactional DDL.
- INFO [alembic.autogenerate.compare] Detected removed table u'sys_user'
- INFO [alembic.autogenerate.compare] Detected removed table u'sys_role_privilege'
- INFO [alembic.autogenerate.compare] Detected removed table u'sys_role'
- INFO [alembic.autogenerate.compare] Detected removed table u'sys_privilege'
- INFO [alembic.autogenerate.compare] Detected removed table u'sys_dict'
- INFO [alembic.autogenerate.compare] Detected removed table u'user info'
- INFO [alembic.autogenerate.compare] Detected removed table u'country'
- INFO [alembic.autogenerate.compare] Detected removed table u'sys_user_role'
- Generating
- /home/flask/flask1/migrations/versions/f52784fdd592_initial_migration.py ... done
三.更新数据库
检查并修改好迁移脚本之后,我们就可以使用db upgrade命令把迁移应用到数据库中;
- python hello.py db upgrade
- INFO [alembic.runtime.migration] Context impl MySQLImpl.
- INFO [alembic.runtime.migration] Will assume non-transactional DDL.
- INFO [alembic.runtime.migration] Running upgrade -> f52784fdd592, initial migration
对于第一个迁移来说,其作用和调用db.create_all()方法是一样的。但在后续的迁移中,upgrade命令能把改动应用到数据库中,且不影响其中保存的数据。
Flask-Script模块使用
Flask-Script扩展提供向Flask插入外部脚本的功能,包括运行一个开发用的服务器,一个定制的python shell,设置数据库的脚本,以及其他运行在web应用之外的命令行任务,是的脚本和系统分开。
Flask-Script和Flask本身工作方式类似,只需要定义和添加从命令行中被Manager实例调用的命令;
官方文档:http://flask-script.readthedocs.io/en/latest/
一.创建并运行命令
首先,创建一个python模块运行命令脚本,可以起名为manager.py
在该文件中,必须有一个manager实例,Manager类追踪所有命令行中调用的命令和处理过程的调用运行情况。
Manager只有一个参数-----Flask实例,也可以是一个函数或其他的返回Flask实例;
调用manager.run()启动Manager实例接收命令行中的命令:
- # path:/package/manager.py
- from flask import Flask
- from flask_migrate import Migrate, MigrateCommand
- from flask_script import Manager
- from flask_sqlalchemy import SQLAlchemy
- app = Flask(__name__)
- #也可以通过db.init_app(app)
- db = SQLAlchemy(app=app)
- migrate = Migrate(app=app)
- manager = Manager(app=app)
- # 添加MigrateCommand命令,使用db来代替
- manager.add_command("db", MigrateCommand)
- if __name__ == "__main__"
manager.run()
二.创建命令的方式
有三种方式创建命令,即创建Command子类、使用@command修饰符、使用@optino修饰符;
第一种-----创建Command子类
Command子类必须定义一个run方法;
举例:创建hello命令,并将hello命令加入Manager实例:
- # path:/package/manager.py
- from flask_script import Manager, Command
- from flask import Flask
- app = Flask(__name__)
- manager = Manager(app=app)
- class Hello(Command):
- "hello,world"
- def run(self):
- print("hello,world")
- # 自定义命令
- manager.add_command("hello",Hello())
- if __name__=="__main__"
- manager.run()
执行如下命令:
python manager.py hello
>hello world
第二种---使用Command实例的@command修饰符
- # path:/package/manager.py
- form flask_script import Manager
- from flask import Flask
- app = Flask(__name__)
- manager = Manager(app)
- @manager.command
- def hello():
- "hello,world"
- print("hello,world")
- if __name__== "__main__":
- manager.run()
该方法创建命令的运行方式和Command子类创建的运行方式相同;
运行方式如下:
python manager.py hello
>hello,world
第三种——使用Command实例的@option修饰符
复杂情况下,建议使用@option;
可以有多个@option选项参数;
- # path:/package/manager.py
- from flask_script import Manager
- from flask import Flask
- app = Flask(__name__)
- manager = Manager(app=app)
- # 命令既可以用-n,也可以用--name,用户输入的名字作为参数传递给了函数中的name
- @manager.option('-n','--name',dest='name',help='Your name', default='world')
- # 命令也是既可以使用-u,也可以使用--url,用户输入的url命令作为参数传递给了函数中的url
- @manager.option('-u','--url',dest='url', default='www.bokeyuan.com')
- def hello(name,url):
- 'hello world or hello <setting name>'
- print("hello",name)
- print(url)
- if __name__ == "__main__":
- manager.run()
运行方式如下:
python manager.py hello
>hello world
>www.csdn.com
python manager.py hello -n Jack -u www.jack.com
>hello Jack
>www.jack.com
python manager.py hello --name Jack --url www.jack.com
>hello Jack
>www.jack.com
关于一个flask的服务接口实战(flask-migrate,flask-script,SQLAlchemy)的更多相关文章
- 如何设计一个异步Web服务——接口部分
需求比较简单,提供一个异步Web服务供使用者调用.比如说,某应用程序需要批量地给图片加lomo效果.由于加lomo效果这个操作非常消耗CPU资源,所以我们需要把这个加lomo效果的程序逻辑放到一台单独 ...
- Python全栈工程师之从网页搭建入门到Flask全栈项目实战(3) - 入门Flask微框架
1.安装Flask 方式一:使用pip命令安装 pip install flask 方式二:源码安装 python setup.py install 验证 第一个Flask程序 程序解释 参数__na ...
- 服务接口API限流 Rate Limit
一.场景描述 很多做服务接口的人或多或少的遇到这样的场景,由于业务应用系统的负载能力有限,为了防止非预期的请求对系统压力过大而拖垮业务应用系统. 也就是面对大流量时,如何进行流量控制? 服务接口的流量 ...
- 如何设计一个异步Web服务——任务调度
接上一篇<如何设计一个异步Web服务——接口部分> Application已经将任务信息发到了Service服务器中,接下来,Service服务器改如何对自身的资源进行合理分配以满足App ...
- java 服务接口API限流 Rate Limit
一.场景描述 很多做服务接口的人或多或少的遇到这样的场景,由于业务应用系统的负载能力有限,为了防止非预期的请求对系统压力过大而拖垮业务应用系统. 也就是面对大流量时,如何进行流量控制? 服务接口的流量 ...
- docker&flask快速构建服务接口(二)
系列其他内容 docker快速创建轻量级的可移植的容器✓ docker&flask快速构建服务接口✓ docker&uwsgi高性能WSGI服务器生产部署必备 docker&g ...
- 使用Flask开发简单接口
作为测试人员,在工作或者学习的过程中,有时会没有可以调用的现成的接口,导致我们的代码没法调试跑通的情况. 这时,我们使用python中的web框架Flask就可以很方便的编写简单的接口,用于调用或调试 ...
- flask微服务框架的初步接触
测试2个关联的系统接口时,经常会遇到被测试系统或被测app的处理内部处理流程会依赖另一个系统的接口返回结果,这时,常用的做法就是写一个模拟测试桩,用作返回请求时的结果.java可以用servicele ...
- Knative 实战:三步走!基于 Knative Serverless 技术实现一个短网址服务
短网址顾名思义就是使用比较短的网址代替很长的网址.维基百科上面的解释是这样的: 短网址又称网址缩短.缩短网址.URL 缩短等,指的是一种互联网上的技术与服务,此服务可以提供一个非常短小的 URL 以代 ...
随机推荐
- 【Leetcode】【Medium】Combination Sum II
Given a collection of candidate numbers (C) and a target number (T), find all unique combinations in ...
- tree 向上查找(更新删除后页面的数据)
需求 : 根据选择的id,需要找到一整条tree,id以及id数据的子集都已被删除(向下查找-----上一篇笔记),此时需要更新页面的数据(向上查找) //知道最底层的节点的id,查找满足id的整个t ...
- 使用Jmeter进行接口测试和压力测试的配置和使用
1. Jmeter简介 Apache JMeter是Apache组织开发的基于Java的压力测试工具.用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域. JMeter 可 ...
- July 14th 2017 Week 28th Friday
A life without a dress rehearsal, every day is broadcast live. 人生没有彩排,每天都是现场直播. Every day when I pre ...
- ZT 骆家辉宣布辞职 他给中国带来什么留下什么?
骆家辉宣布辞职 他给中国带来什么留下什么? 字号|2013年11月20日 15:20 已有1933人阅读 57 导 读 美国驻华大使骆家辉20日上午发表声明,宣布辞职.骆家辉履任期间为中国 ...
- c++ nested class 嵌套类。
c++ primer 658页 嵌套类最常用于定义执行类,
- 023re模块(正则)
之前我刚学的python知识点,没有题目进行熟悉,后面的知识点会有练习题,并且慢慢补充.看到很多都是很简单的练习,碰到复杂.需要运用的再补充吧#字符串中使用到正则表达式 s='hello world' ...
- MongoDB索引管理
一.创建索引 创建索引使用db.collectionName.ensureIndex(...)方法进行创建: 语法: >db.COLLECTION_NAME.ensureIndex({KEY:1 ...
- D3——动态绑定数据
一.绑定数组元素 , , , , ]; d3.select("body") .selectAll("p") .data(dataset) .enter() .a ...
- jq实现随机显示部分图片在页面上(兼容IE5)
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...