爬虫 (5)- Scrapy 框架简介与入门
Scrapy 框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Windows 安装方式
- Python 2 / 3
- 升级pip版本:
pip install --upgrade pip - 通过pip 安装 Scrapy 框架
pip install Scrapy
入门案例
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
一. 新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider
- 其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
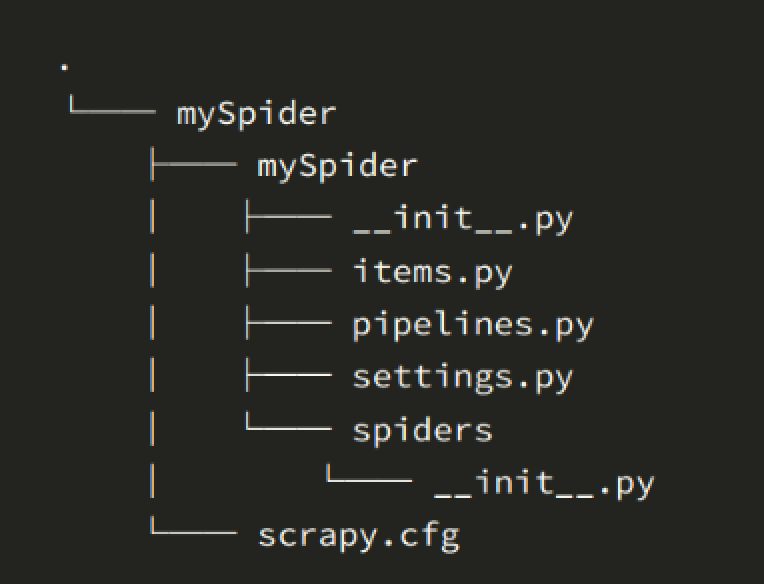
下面来简单介绍一下各个主要文件的作用:
- scrapy.cfg :项目的配置文件
- mySpider/ :项目的Python模块,将会从这里引用代码
- mySpider/items.py :项目的目标文件
- mySpider/pipelines.py :项目的管道文件
- mySpider/settings.py :项目的设置文件
- mySpider/spiders/ :存储爬虫代码目录
二、明确目标(mySpider/items.py)
我们打算抓取:http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息。
打开mySpider目录下的items.py
Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。
接下来,创建一个ItcastItem 类,和构建item模型(model)。
import scrapy class ItcastItem(scrapy.Item):
name = scrapy.Field()
level = scrapy.Field()
info = scrapy.Field()
三、制作爬虫 (spiders/itcastSpider.py)
爬虫功能要分两步:
1. 爬数据
- 在当前目录下输入命令,将在
mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
- 打开 mySpider/spider目录里的 itcast.py,默认增加了下列代码:
import scrapy class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
) def parse(self, response):
pass
其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
将start_urls的值修改为需要爬取的第一个url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改parse()方法
def parse(self, response):
filename = "teacher.html"
open(filename, 'w').write(response.body)
然后运行一下看看,在mySpider目录下执行:
scrapy crawl itcast
2. 取数据
- 爬取整个网页完毕,接下来的就是的取过程了,首先观察页面源码:

<div class="li_txt">
<h3> xxx </h3>
<h4> xxxxx </h4>
<p> xxxxxxxx </p>
是不是一目了然?直接上XPath开始提取数据吧。
- 我们之前在mySpider/items.py 里定义了一个ItcastItem类。 这里引入进来
from mySpider.items import ItcastItem
- 然后将我们得到的数据封装到一个
ItcastItem对象中,可以保存每个老师的属性:
from mySpider.items import ItcastItem def parse(self, response):
#open("teacher.html","wb").write(response.body).close() # 存放老师信息的集合
items = [] for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是unicode字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract() #xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0] items.append(item) # 直接返回最后数据
return items
保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json # json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl # csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv # xml格式
scrapy crawl itcast -o teachers.xml
爬虫 (5)- Scrapy 框架简介与入门的更多相关文章
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- 5、爬虫之scrapy框架
一 scrapy框架简介 1 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Sc ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- 爬虫(九)scrapy框架简介和基础应用
概要 scrapy框架介绍 环境安装 基础使用 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能 ...
随机推荐
- Mapreduce报错:java.lang.ClassNotFoundException: Class Mapper not found
mapreduce找不到mapper类 解决方法: 开始自己用的是mapreduce自己打包的一种方法: job.setJarByClass(StandardJob.class); 但这样一直在报错: ...
- ExportAsFixedFormat Visio文件另存为其他几种格式的处理
Visio文件另存为其他几种格式的处理,以及另存为Web文件等相关操作. 1.Visio导出为PDF格式 在一般情况下,PDF格式是较为常用的内容格式,因此Visio文档(Vsd格式)导出为PDF也是 ...
- ActiveRecord::StatementInvalid (Mysql2::Error: Incorrect string value:
今天碰到一个相当棘手的问题,那就是ActiveRecord::StatementInvalid (Mysql2::Error: Incorrect string value . 本来在本地测试是没有任 ...
- atitit.微信支付的教程文档 attilax总结
atitit.微信支付的教程文档 attilax总结 1. 支付流程概览 1 2. 设置支付起始文件夹 host/app/paydir/ 1 3. 设置oauth验证域名 1 4. 測试文件夹 能 ...
- 算法笔记_114:等额本金(Java)
1 等额本金 标题:等额本金 小明从银行贷款3万元.约定分24个月,以等额本金方式还款. 这种还款方式就是把贷款额度等分到24个月.每个月除了要还固定的本金外,还要还贷款余额在一个月 中产生的利息. ...
- chromedriver Capabilities & ChromeOptions
Capabilities are options that you can use to customize and configure a ChromeDriver session. This pa ...
- Java 中equals和==差别
java中的数据类型,可分为两类: 1.基本数据类型.也称原始数据类型.byte,short,char,int,long,float,double,boolean 他们之间的比較,应用双等号( ...
- Spring3.0官网文档学习笔记(四)--3.1~3.2.3
3.1 Spring IoC容器与Beans简单介绍 BeanFactory接口提供对随意对象的配置: ApplicationContext是BeanFactory的子接口.整合了Sp ...
- 分享一下自己ios开发笔记
// ********************** 推断数组元素是否为空 ********************** NSString *element = [array objectAtIndex ...
- 转载 :sql server分区 http://blog.itpub.net/27099995/viewspace-1081158/
转载:http://blog.itpub.net/27099995/viewspace-1081158/ 在 sql server 2005 之前不提供分区表,但可以用其他方式建立“分区表”,sql ...