大全Kafka Streams
本文将从以下三个方面全面介绍Kafka Streams
一. Kafka Streams 概念
二. Kafka Streams 使用
三. Kafka Streams WordCount
一. Kafka Streams 概念
1.Kafka Stream?
Kafka Streams是一套处理分析Kafka中存储数据的客户端类库,处理完的数据或者写回Kafka,或者发送给外部系统。它构建在一些重要的流处理概念之上:区分事件时间和处理时间、开窗的支持、简单有效的状态管理等。Kafka Streams入门的门槛很低:很容易编写单机的示例程序,然后通过在多台机器上运行多个实例即可水平扩展从而达到高吞吐量。Kafka Streams利用Kafka的并发模型以实现透明的负载均衡。
一些亮点:
• 设计成简单和轻量级的客户端类库,可以和现有Java应用、部署工具轻松整合。
• 除了Kafka自身外不依赖其他外部系统。利用Kafka的分区模型来实现水平扩展并保证有序处理。
• 支持容错的本地状态,这使得快速高效处理一些有状态的操作(如连接和开窗聚合)成为可能。
• 支持一次一条记录的处理方式以实现低延迟,也支持基于事件时间的开窗操作。
• 提供了两套流处理原语:高层的流DSL和低层的处理器API。
核心概念
2. Stream Processing Topology(流处理拓扑)
1)、stream是Kafka Stream最重要的抽象,它代表了一个无限持续的数据集。stream是有序的、可重放消息、对不可变数据集支持故障转移
2)、一个流处理应用程序通过一或多个“处理器拓扑(processor topology)”来定义其计算逻辑,一个processor topology就是一张以流处理器(stream processor、节点)和流[streams](边)构成的图。(实际为DAG,太熟悉了吧,多么类似spark Streaming)
3)、一个stream processor是processor topology中的一个节点,它代表一个在stream中的处理步骤:从上游processors接受数据、进行一些处理、最后发送一到多条数据到下游processors
Kafka Stream提供两种开发流处理拓扑(stream processing topology)的API
1)、high-level Stream DSL:提供通用的数据操作,如map和fileter
2)、lower-level Processor API:提供定义和连接自定义processor,同时跟state store(下文会介绍)交互
3. 时间
时间的概念在流处理中很关键,比如开窗这种操作就是根据时间边界来定义的。上面也提到过两个常见概念:
• 事件时间:事件或数据记录发生的时刻。
• 处理时间:事件或数据记录被流处理应用开始处理的时刻,比如记录开始被消费。处理时间可能比事件时间晚几毫秒到几天不等。
• 摄取时间:数据记录由KafkaBroker保存到 kafka topic对应分区的时间点。摄取时间类似事件时间,都是一个嵌入在数据记录中的时间戳字段。不同的是,摄取时间是由Kafka Broker附加在目标Topic上的,而不是附加在事件源上的。如果事件处理速度足够快,事件产生时间和写入Kafka的时间差就会非常小,这主要取决于具体的使用情况。因此,无法在摄取时间和事件时间之间进行二选一,两个语义是完全不同的。同时,数据还有可能没有摄取时间,比如旧版本的Kafka或者生产者不能直接生成时间戳(比如无法访问本地时钟。)。
事件时间和摄取时间的选择是通过在Kafka(不是KafkaStreams)上进行配置实现的。从Kafka 0.10.X起,时间戳会被自动嵌入到Kafka的Message中,可以根据配置选择事件时间或者摄取时间。配置可以在broker或者topic中指定。Kafka Streams默认提供的时间抽取器会将这些嵌入的时间戳恢复原样。
Kafka Stream 使用TimestampExtractor 接口为每个消息分配一个timestamp,具体的实现可以是从消息中的某个时间字段获取timestamp以提供event-time的语义或者返回处理时的时钟时间,从而将processing-time的语义留给开发者的处理程序。开发者甚至可以强制使用其他不同的时间概念来进行定义event-time和processing time。
注意:Kafka Streams中的摄取时间和其他流处理系统略有不同,其他流处理系统中的摄取时间指的是从数据源中获取到数据的时间,而kafka Streams中,摄取时间是指记录被追加到Kakfa topic中的时间。
4. 状态
有些stream应用不需要state,因为每条消息的处理都是独立的。然而维护stream处理的状态对于复杂的应用是非常有用的,比如可以对stream中的数据进行join、group和aggreagte,Kafka Stream DSL提供了这个功能。
Kafka Stream使用state stores(状态仓库)提供基于stream的数据存储和数据查询状态数据,每个Kafka Stream内嵌了多个state store,可以通过API存取数据,这些state store的实现可以是持久化的KV存储引擎、内存HashMap或者其他数据结构。Kafka Stream提供了local state store的故障转移和自动发现。
5. KStream和KTable(流和表的双重性)
Kafka Stream定义了两种基本抽象:KStream 和 KTable,区别来自于key-value对值如何被解释,
5.1KStream:
一个纯粹的流就是所有的更新都被解释成INSERT语句(因为没有记录会替换已有的记录)的表。
在一个流中(KStream),每个key-value是一个独立的信息片断,比如,用户购买流是:alice->黄油,bob->面包,alice->奶酪面包,我们知道alice既买了黄油,又买了奶酪面包。
5.2KTable(changelog流):
KTable 一张表就是一个所有的改变都被解释成UPDATE的流(因为所有使用同样的key的已存在的行都会被覆盖)。
对于一个表table( KTable),是代表一个变化日志,如果表包含两对同样key的key-value值,后者会覆盖前面的记录,因为key值一样的,比如用户地址表:alice -> 纽约, bob -> 旧金山, alice -> 芝加哥,意味着Alice从纽约迁移到芝加哥,而不是同时居住在两个地方。
KTable 还提供了通过key查找数据值得功能,该查找功能可以用在Join等功能上。
这两个概念之间有一个二元性,一个流能被看成表,而一个表也可以看成流。
6. 低层处理器API
6.1 处理器
开发着通过实现Processor接口并实现process和punctuate方法,每条消息都会调用process方法,punctuate方法会周期性的被调用
6.2 处理器拓扑
有了在处理器API中自定义的处理器,然后就可以使用TopologyBuilder来将处理器连接到一起从而构建处理器拓扑:
6.3 本地状态仓库
处理器API不仅可以处理当前到达的记录,也可以管理本地状态仓库以使得已到达的记录都可用于有状态的处理操作中(如聚合或开窗连接)。为利用本地状态仓库的优势,可使用TopologyBuilder.addStateStore方法以便在创建处理器拓扑时创建一个相应的本地状态仓库;或将一个已创建的本地状态仓库与现有处理器节点连接,通过TopologyBuilder.connectProcessorAndStateStores方法。
7. 高层流DSL
为使用流DSL来创建处理器拓扑,可使用KStreamBuilder类,其扩展自TopologyBuilder类。Kafka的源代码中在streams/examples包中提供了一个示例。
7.1 从Kafka创建源端流
Kafka Streams为高层流定义了两种基本抽象:记录流(定义为KStream)可从一或多个Kafka topic源来创建,更新日志流(定义为KTable)可从一个Kafka topic源来创建。
KStream可以从多个kafka topic中创建,而KTable只能单个topic
KStreamBuilder builder = new KStreamBuilder();
KStream source1 = builder.stream("topic1", "topic2");
KTable source2 = builder.table("topic3");
7.2 转换一个流
KStream和KTable相应地都提供了一系列转换操作。每个操作可产生一或多个KStream和KTable对象,可被翻译成一或多个相连的处理器。所有这些转换方法连接在一起形成一个复杂的处理器拓扑。因为KStream和KTable是强类型的,这些转换操作都被定义为泛类型,使得用户可指定输入和输出数据类型。
这些转换中,filter、map、mapValues等是无状态的,可用于KStream和KTable两者,通常用户会传一个自定义函数给这些函数作为参数,例如Predicate给filter,KeyValueMapper给map等:
无状态的转换不依赖于处理的状态,因此不需要状态仓库。有状态的转换则需要存取相应状态以处理和生成结果。例如,在join和aggregate操作里,一个窗口状态用于保存当前预定义窗口中收到的记录。于是转换可以获取状态仓库中累积的记录,并执行计算。
7.3 写回到kafka(Write streams back to Kafka)
最后,开发者可以将最终的结果stream写回到kafka,通过 KStream.to and KTable.to
joined.to("topic4");
如果应用希望继续读取写回到kafka中的数据,方法之一是构造一个新的stream并读取kafka topic,Kafka Stream提供了另一种更方便的方法:through
joined.to("topic4");
materialized = builder.stream("topic4");
KStream materialized = joined.through("topic4");
8. 窗口
一个流处理器可能需要将数据划分为多个时间段,这就是流上窗口。这通常在Join或者aggregation聚合等保存本地状态的处理程序中使用。
Kafka StreamsDSL API提供了可用的窗口操作,用户可以指定数据在窗口中的保存期限。这就允许Kafka Streams在窗口中保留一段时间的旧数据以等待其它晚到的数据。如果保留期过了之后数据才到达,这条消息就不能被处理,会被丢掉。
实时的流处理系统中,数据乱序总是存在的,这主要取决于数据在有效时间内如何进行处理。对于在正处于处理期的时间内的数据,如果数据乱序,延迟到达,在语义上就可以被正常处理,如果数据到达时候,已经不在处理期,那么这种数据就不适合处理期的语义,只能被丢弃掉。
9. Join
Join操作负责在Key上对两个流的记录进行合并,并产生新流。一个基于流上的Join通常是基于窗口的,否则所有数据就都会被保存,记录就会无限增长。
KafkaStreams DSL支持不同的Join操作,比如KStram和KStream之间的Join,以及KStream和KTable之间的Join。
10. Aggregations
聚合操作需要一个输入流,并且以多个输入记录为单位组合成单个记录并产生新流。常见的聚合操作有count和sum。流上的聚合也必须基于窗口进行,否则数据和join一样都会无限制增长。
在Kafka Streams的DSL中,一个聚合输入流可以是KStream形式或者KTable形式,但是输出流永远都是KTable。这就使得Kafka Streams的输出结果会被不断更新,这样,当有数据乱序到达之后,数据也可以被及时更新,因为最终输出是KTable,新key会覆盖旧值。
配置参数
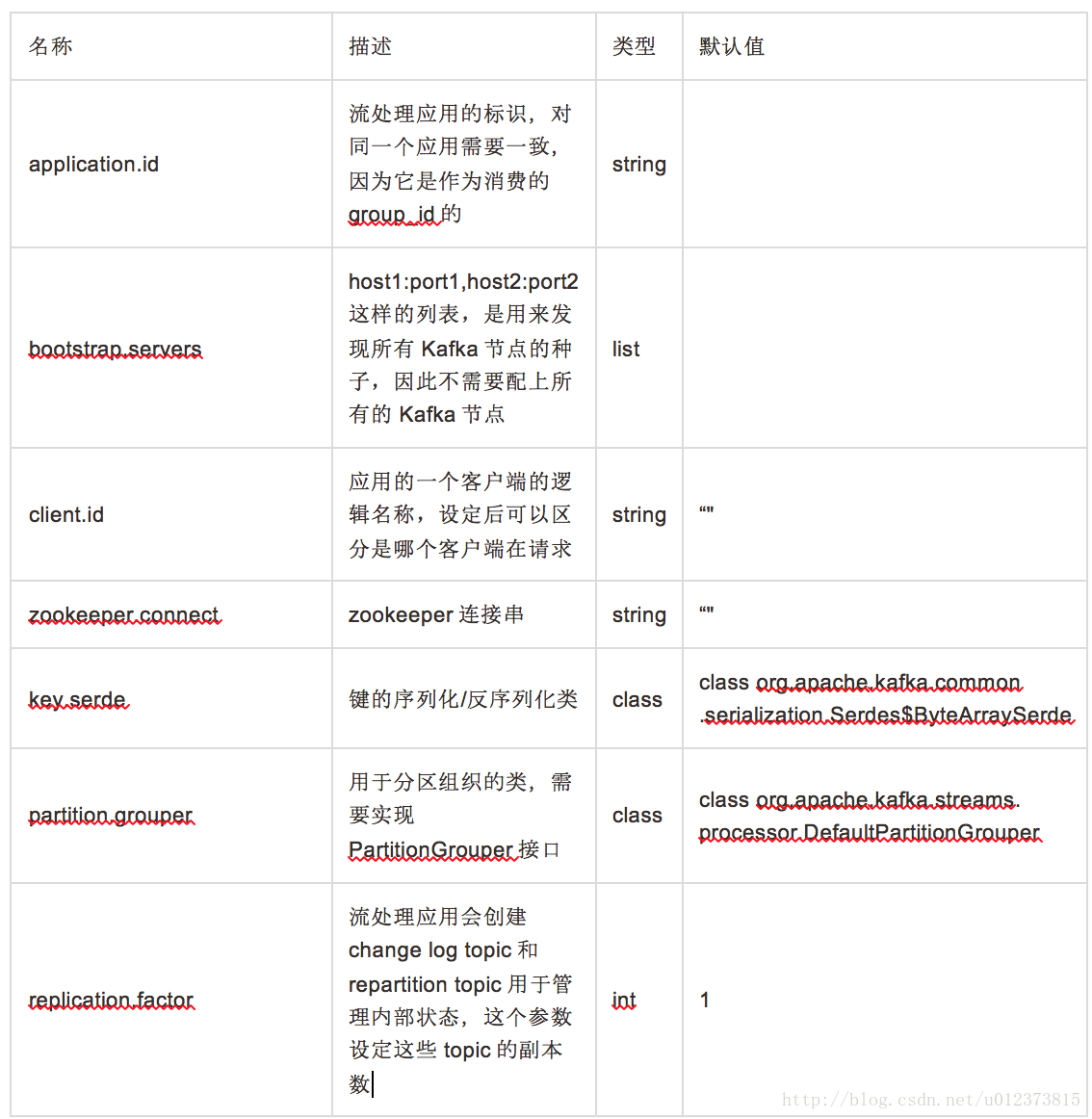
二. Kafka Streams 使用
1 概述
kafka Streams是一个客户端库(client library),用于处理和分析储存在Kafka中的数据,并把处理结果写回Kafka或发送到外部系统的最终输出点。它建立在一些很重要的概念上,比如事件时间和消息时间的准确区分,开窗支持,简单高效的应用状态管理。Kafka Streams的门槛很低:你可以快速编写一个小规模的原型运行在一台独立主机中;然后你只需要在其他主机主机上部署应用的实例,就可以完成到大规模生产环境的扩展。Kafka Streams利用Kafka的并行模型,可以透明处理同一应用的多实例负载均衡。
kafka Streams的特点:
*被设计为一个简单轻量级的客户端库,可以嵌入到Java应用,整合到已有的包、部署环境或者其他用户的流应用处理工具。
*除了Kafka自身做为内部消息层外,没有其他系统依赖。使用Kafka分区模型来水平扩展并保证绝对的顺序性。
*支持本地状态容错,可以执行非常快速有效的有状态操作,比如joins和windowed aggregations(窗口聚合)。
*采用“一次处理一条记录(one-record-at-a-time)”的方式达到低处理延迟,支持基于开窗操作的事件消息(event-time)。
*提供必要的流处理基础件,包括一个高级Streams DSL和一个底层处理API(Processor API)。
2 开发指南
2.1 核心概念
2.1.1 流处理过程拓扑图
*一个流(stream)是Kafka中最重要的抽象概念:它代表了一个无界,持续更新的数据集。一个流是一个有序,可重复读取,容错的不可变数据记录序列,一个数据记录被定义为一个键值对(key-value pair)。
*一个流处理应用,用Kafka Streams开发,定义了经过若干个处理拓扑(processor topologies)的计算逻辑,每个处理拓扑是一个通过流(线,edge)连接到流处理实例(点,node)的图。
*一个流处理实例(processor)是一个处理拓扑的节点;其含义是,通过从拓扑图中它的上游处理节点每次接收一条输入记录,执行一步流数据的变换,可能是请求操作流数据,也有可能随后生产若干条记录给到下游处理实例。
2.1.2 时间
流处理中一个临界面就是时间概念,以及它是怎么定义和整合的。比如,像开窗(windowing)这样的操作定义是基于时间边界的。
流中常用的消息概念有:
*事件时间————当事件或数据记录产生的时间点,最初被称为"at the source"(起源)。
*处理时间————当事件或数据记录被流处理应用开始处理的时间点,也就是记录开始被消费的时间。处理时间会比源事件时间晚若干毫秒、小时,甚至若干天。
*存储时间————当事件或者数据记录被Kafka broker储存到一个主题分区的时间。和事件时间不同的是,存储时间是发生在Kafka broker把记录添加到目标主题时,而不是记录创建时。和处理时间不同的是,处理时间发生在流处理应用处理记录时。比如,如果一个记录从来没被处理过,那它就没有处理时间的概念,但是它还是有存储时间。
选择事件时间还是存储时间,是通过Kafka配置文件确定的(不是Kafka Streams):在Kafka 0.10.x之前,时间戳会自动嵌入到Kafka消息中。通过Kafka的配置项,这些时间戳可以代表事件时间或存储时间。该项可以配置在broker级或单个topic。默认Kafka Streams中时间戳提取器会把嵌入的时间戳原样提取。所以,你应用中有效的时间含义依赖于Kafka中这些嵌入时间戳的配置。
Kafka Streams把每一个时间戳关联到每个数据记录通过接口TimestampExtractor。该接口的具体实现会检索或计算时间戳,数据记录确实产生内容的时间被当做嵌入时间戳时代表事件时间语义,或者用其他方法如当前时钟时间获取的处理时时间,会代表处理时间语义。开发者可以鉴于此依照业务需要使用不同时间概念。比如,单个记录(per-record)时间戳描述了按照时间访问流的进度(虽然流中的记录可能是无序的),然后被依赖于时间的操作(如joins)利用。
最后,无论何时一个Kafka Streams应用写记录到Kafka,都会给新记录关联一个时间戳。关联时间戳的方法依赖于context对象:
*当通过处理输入记录而产生新输出记录时,比如,用context.forward()触发process()方法调用,输出记录会直接继承输入记录的时间戳。
*当通过周期函数产生新输出记录时(如punctuate),输出记录的时间戳被定义为当前流任务的内部时间(通过context.timestamp())。
*为了聚合性,更新记录聚合的结果时间戳就是最新输入记录到达时触发的更新时间。
2.1.3 状态
某些流处理应用不需要状态,也就是一个消息处理过程不依赖于取他消息的处理过程。但是,可以保持状态会提供更多更复杂的流处理过程:你可以组合(join)输入流,分组并聚合数据记录。很多这种有状态的操作都可以通过Kafka Streams DSL得到。
Kafka Streams提供了所谓的状态存储(state stores),可以被流处理应用用于保存和查询数据。当实现有状态操作时,这是非常有用的功能。每个Kafka Streams任务会嵌入若干个状态存储,通过API访问存储的状态可以保存或查询处理过程需要的数据。这些状态存储可以保存为持久化键值对,一个内存哈希表,或者其他实用的数据结构。Kafka Streams提供了本地状态存储的容错和自动还原。
Kafka Streams允许直接只读查询(read-only query)状态存储,可以通过方法、线程、处理过程或和创建数据存储的应用无关的应用。这个功能被称为“交互式查询” (Interactive Query)。所有的存储都被命名,而且交互式查询底层实现只开放了读操作。
如前所述,一个Kafka Streams应用的计算逻辑被定义为一个处理拓扑。当前Kafka Streams提供了两组API用于定义处理拓扑。
2.2 底层处理API
2.2.1 Processor类
开发人员可以定制自己的业务处理逻辑,通过继承Process类。该接口提供了process和punctuate方法。process方法会在每条记录上执行;punctuate方法会被周期性调用。另外,processor接口可以保持当前ProcessorContext实例变量(在init方法中初始化),用context来设定punctuate调用周期(context().schedule),转发修改/新键值对到下游Processor实例(context().forwar),提交当前处理进度(context().commit),等等。
public class MyProcessor extends Processor {
private ProcessorContext context;
private KeyValueStore kvStore;
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
this.context = context;
this.context.schedule(1000);
this.kvStore = (KeyValueStore) context.getStateStore("Counts");
}
@Override
public void process(String dummy, String line) {
String[] words = line.toLowerCase().split(" ");
for (String word : words) {
Integer oldValue = this.kvStore.get(word);
if (oldValue == null) {
this.kvStore.put(word, 1);
} else {
this.kvStore.put(word, oldValue + 1);
}
}
}
@Override
public void punctuate(long timestamp) {
KeyValueIterator iter = this.kvStore.all();
while (iter.hasNext()) {
KeyValue entry = iter.next();
context.forward(entry.key, entry.value.toString());
}
iter.close();
context.commit();
}
@Override
public void close() {
this.kvStore.close();
}
};
上面的示例中执行了如下的操作:
*init:设定punctuate调用周期为1秒,获取本地状态存储并命名为“Counts”.
*process: 根据每条收到的记录,把输入字符串值分割为单词,把他们的计数更新到状态存储(我们在下一节讨论该功能)。
*punctuate:迭代本地状态存储,发送计数集合到下游处理器,提交当前流状态。
2.2.2 处理拓扑(Processor Topology)
实现自定义Processor的同时,开发人员可以用TopologyBuilder构建一个处理拓扑,把各个Processor过程连接在一起:
TopologyBuilder builder = new TopologyBuilder();
builder.addSource("SOURCE", "src-topic")
.addProcessor("PROCESS1", MyProcessor1::new /* the ProcessorSupplier that can generate MyProcessor1 */, "SOURCE")
.addProcessor("PROCESS2", MyProcessor2::new /* the ProcessorSupplier that can generate MyProcessor2 */, "PROCESS1")
.addProcessor("PROCESS3", MyProcessor3::new /* the ProcessorSupplier that can generate MyProcessor3 */, "PROCESS1")
.addSink("SINK1", "sink-topic1", "PROCESS1")
.addSink("SINK2", "sink-topic2", "PROCESS2")
.addSink("SINK3", "sink-topic3", "PROCESS3");
上面代码中创建拓扑有几个步骤,下面简略说明一下:
*首先,调用addSource方法将一个源节点(命名为“SOURCE”)添加到拓扑中,并和一个Kafka主题“src-topic”关联,。
*其次,调用addProcessor添加三个处理节点,在这里,第一个处理实例是“SOURCE”节点的孩子,但是是其他两个实例的父亲。
*最后,调用addSink添加三个槽(sink)节点到已经部署好的拓扑中,每一个从不同父Processor节点来的管道都写入不同的主题。
2.2.3 本地状态存储
注意,ProcessorAPI不限制应用仅仅访问当前到达的记录,也可以访问之前保存了之前到达记录的本地状态存储,用于聚合或窗口组合等有状态处理操作。为了利用本地状态的优势,开发者使用TopologyBuilder.addStateStore方法在构建处理拓扑时创建本地状态,并把它和需要访问它的处理节点关联起来;或者用TopologyBuilder.connectProcessorAndStateStores方法连接已创建的本地状态存储和已存在的处理节点。
TopologyBuilder builder = new TopologyBuilder();
builder.addSource("SOURCE", "src-topic")
.addProcessor("PROCESS1", MyProcessor1::new, "SOURCE")
// create the in-memory state store "COUNTS" associated with processor "PROCESS1"
.addStateStore(Stores.create("COUNTS").withStringKeys().withStringValues().inMemory().build(), "PROCESS1")
.addProcessor("PROCESS2", MyProcessor3::new /* the ProcessorSupplier that can generate MyProcessor3 */, "PROCESS1")
.addProcessor("PROCESS3", MyProcessor3::new /* the ProcessorSupplier that can generate MyProcessor3 */, "PROCESS1")
// connect the state store "COUNTS" with processor "PROCESS2"
.connectProcessorAndStateStores("PROCESS2", "COUNTS");
.addSink("SINK1", "sink-topic1", "PROCESS1")
.addSink("SINK2", "sink-topic2", "PROCESS2")
.addSink("SINK3", "sink-topic3", "PROCESS3");
2.3 高级Streams DSL
使用Streams DSL构建一个处理拓扑,开发者需要使用KStreamBuilder类,该类继承自TopologyBuilder类。streams/examples包内有一个简单的包含源码的示例。本节剩余部分,会通过一些实例代码来展现使用Streams DSL创建一个拓扑的关键步骤,不过我们还是建议开发者阅读完整的实例以了解所有的细节。
2.3.1 KStream类和KTable类
DSL用到了两个主要的抽象概念。一个KStream实例是一个记录流的抽象,记录流中每条数据记录代表了一个无界数据集中的一个独立数据。一个KTable实例是一个更新日志流的抽象,更新日志流中每一条数据代表了一个更新。更准确的说,数据记录中的值代表了同一个记录关键字的最新更新值,如果有相同关键字记录的话(如果关键字不存在,那么更新动作会创建一个)。为了说明KStream和KTable的区别,我们有下面两个记录发往流:("alice", 1) --> ("alice", 3)。如果这两条记录保存在KStream实例,流处理应用累加他们的值会得到结果4。如果这两条记录保存在KTable实例,得到的结果是3,因为后一个记录会被当做是前一个记录的更新。
2.3.2 从Kafka创建流数据源
无论是记录流(用KStream定义)还是更新日志流(用KTable定义),都可以被创建为一个流数据源,数据来自若干个Kafka主题(KTable只能创建单主题的数据源)。
KStreamBuilder builder = new KStreamBuilder();
KStream source1 = builder.stream("topic1", "topic2");
KTable source2 = builder.table("topic3", "stateStoreName");
2.3.3 数据流开窗
某个流处理过程可能需要把数据记录按时间分组,也就是按时间把流分为多个窗口。通过join和聚合操作会用到这个。Kafka Streams目前定义了如下几种窗口:
*Hopping time window 时间跨越窗口,基于时间间隔,模拟了大小固定、(可能)重叠的窗口。一个跨越窗口由两个属性确定:窗口大小和跨越步长(前进间隔)(即“hop”跳)。前进间隔指定了一个窗口每次相对于前一个窗口向前移动的距离。比如,你可以配置一个长度5分钟的跨越窗口,前进间隔是1分钟。跨越窗口可能覆盖了一个记录,该记录属于若干个这样的窗口。
*Tumbling time windows 是一个特殊的跨越窗口,所以也是基于时间间隔。它模拟了大小固定、不可重叠、无间隙的一类窗口。一个trumbing窗口由一个属性确定:窗口大小。投入你们 trumbing窗口是一个窗口大小等于前进步长的跨越窗口。因为它不会重叠,一条记录也仅属于唯一的窗口。
*sliding window,滑动窗口,模拟了大小固定并沿着时间轴连续滑动的窗口。这里,有两条数据记录存在于同一个窗口,他们时间戳不同但是都在窗口大小内。所以,滑动窗口没有和某个时间点对齐,而是和数据记录时间戳对齐。在Kafka流中,滑动窗口只有在join操作时才用到,可以用JoinWindows类来定义。
2.3.4 join操作
一个join(合并)操作就是合并两个数据流,基于他们数据的键,然后生成一个新流。一个记录流上的join操作通常需要基于窗口操作(即分段执行),因为用于执行join操作的记录数量可能会无限增长。Kafka Streams定义了如下几个join操作:
*KStream-to-KStream Joins:就是windowed join(窗口合并),因为用于计算join操作的内存大小和状态可能是无限增长的。这里,假设从需要和其他记录流进行join操作的流,新接收到一条记录,按照指定的窗口间隔生产一个结果,用于每个符合用户提供的ValueJoiner类要求的键值对。一个从join操作返回的新的KStream实例代表了join操作的结果。
*KTable-to-KTable Joins:这个join操作用于和关系数据库中对应记录保持一致。这里,两个更新日志流先实例化到本地状态存储中。当收到其中某个流的新记录,就把记录合并到另一个流的实例化状态存储中,然后生产一个符合用户提供的ValueJoiner类的键值对结果。join操作返回一个新的KTable实例代表了流合并的结果,它仍然是一个更新日志流。
*KSream-to-KTable Joins:允许你根据记录流(KStream)接收到的新数据,在更新日志流(KTable)中执行表查询。一种应用是可以用最新的用户资料信息(KTable)补充用户行为信息(KStream)。只有当从记录流接收到记录时才会触发join操作,然后通过ValueJoiner生产结果,反过来不成立(也就是从更新日志流接收到的记录只能用于更新实例化状态存储)。该操作返回新的KStream实例代表了流合并的结果。
根据操作对象不同,join支持如下操作:inner joins,outer joins, 和left joins。他们的语义和关系数据库中相同。
2.3.5 转换一个流
KStream和KTable各自提供了一系列转换操作。每个操作都会生成一个或多个KStream或KTable对象,可以被传入已连接的底层处理拓扑中的处理过程。所有这样转换方法可以链式组合为复杂的处理拓扑。KStream和KTable是强类型,但是所有这些转换操作都被定义为模板方法,用户可以指定输入输出的数据类型。
在这些转换中,filter、map、mapValues等等,都是无状态转换操作,都可以在KStream和KTable中调用,用户只需要传入一个自定义函数作为它们形参,比如Predicate传入到filter,KeyValueMapper传入到map,等等:
// written in Java 8+, using lambda expressions
KStream mapped = source1.mapValue(record -> record.get("category"));
无状态转换,顾名思义,就是不依赖于处理过程的状态,所以在实现时不需要关联流处理实例(stream processor)的状态存储。有状态转换,换句话说,就是处理时出现访问关联状态然后产生输出。比如,join和aggregate操作,通常需要一个窗口状态保存所有接收到的记录(在窗口范围内)。然后这些个操作访问存储中积累的记录,用他们做业务逻辑。
// written in Java 8+, using lambda expressions
KTable<Long> counts = source1.groupByKey().aggregate(
() -> 0L, // initial value
(aggKey, value, aggregate) -> aggregate + 1L, // aggregating value
TimeWindows.of("counts", 5000L).advanceBy(1000L), // intervals in milliseconds
Serdes.Long() // serde for aggregated value
); KStream joined = source1.leftJoin(source2,
(record1, record2) -> record1.get("user") + "-" + record2.get("region");
);
2.3.6 把流写回Kafka
处理完数据后,用户可以选择(持续的)把最终结果流写入一个Kafka主题,通过KStream.to和KTable.to方法。
joined.to("topic4");
如果你的应用需要持续读取并处理那些通过to方法写入到主题的记录,有一个办法是构造一个新的流从输出主题读取数据;Kafka Streams提供了一个便利的方法叫through:
// equivalent to
//
// joined.to("topic4");
// materialized = builder.stream("topic4");
KStream materialized = joined.through("topic4");
除了定义拓扑之外,开发者还要在运行拓扑前配置文件StreamsConfig。
三. Kafka Streams WordCount
本文展示了kafka Stream Wordcount 例子的两种写法
kafka Stream 版本0.10.1.0
此例子 使用了高层流DSL创建kStream 多实例(instances1,instances2为两个实例)并行计算处理了从topic1 中读取的数据。
package com.us.kafka.Stream; import java.util.Arrays; import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.KeyValueMapper;
import org.apache.kafka.streams.kstream.Predicate;
import org.apache.kafka.streams.kstream.ValueMapper;
import com.us.kafka.KafkaConfig; import java.util.Properties; import static org.apache.kafka.common.serialization.Serdes.String; /**
* 高层流DSL
*/
public class MyKstream {
public static void main(String[] args) { //tow instances
KStreamBuilder instances1 = new KStreamBuilder();
// filterWordCount(builder);
lambdaFilter(instances1);
KStreamBuilder instances2 = new KStreamBuilder();
lambdaFilter(instances2); KafkaStreams ks = new KafkaStreams(instances2, init());
ks.start();
// Runtime.getRuntime().addShutdownHook(new Thread(ks::close));
} public static Properties init() {
Properties properties = new Properties();
properties.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, "MyKstream");
properties.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaConfig.metadata_broker_list);
properties.setProperty(StreamsConfig.ZOOKEEPER_CONNECT_CONFIG, KafkaConfig.zookeeper);
properties.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, String().getClass().getName());
properties.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, String().getClass().getName());
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return properties;
} private static void filterWordCount(KStreamBuilder builder) {
KStream<String, String> source = builder.stream("topic1");
KTable<String, Long> count = source.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split(" "));
}
}).filter(new Predicate<String, String>() { @Override
public boolean test(String key, String value) {
if (value.contains("abel")) {
return true;
}
return false;
}
}).map(new KeyValueMapper<String, String, KeyValue<String, String>>() { public KeyValue<String, String> apply(String key, String value) { return new KeyValue<String, String>(value + "--read", value);
} }).groupByKey().count("us");
count.print();
// count.to("topic2");
} private static void lambdaFilter(KStreamBuilder builder) {
KStream<String, String> textLines = builder.stream("topic1"); textLines
.flatMapValues(value -> Arrays.asList(value.split(" ")))
.map((key, word) -> new KeyValue<>(word, word))
.filter((k, v) -> (!k.contains("message")))
// .through("RekeyedIntermediateTopic")
.groupByKey().count("us").print();
System.out.println("-----------2-----------"); } }
<properties>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.source>1.8</maven.compiler.source>
</properties> <dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.1.0</version>
</dependency> <dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
</dependency> <!-- kafka Stream -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.10.1.0</version>
</dependency>
</dependencies>
运行下面代码条件:
1. java 1.8+
2. kafka 0.10+
public class StreamDemo {
public static Map<String, Object> connection() {
Map<String, Object> properties = new HashMap<>();
// 指定一个应用ID,会在指定的目录下创建文件夹,里面存放.lock文件
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-stream-processing-application");
// 指定kafka集群
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "server01:9092");
// 指定一个路径创建改应用ID所属的文件
properties.put(StreamsConfig.STATE_DIR_CONFIG, "E:\\kafka-stream");
// key 序列化 / 反序列化
properties.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// value 序列化 / 反序列化
properties.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
return properties;
}
public static void main(String[] args) throws IOException {
// 创建一个StreamsConfig对象
StreamsConfig config = new StreamsConfig(StreamDemo.connection());
// KStreamBuilder builder = new KStreamBuilder();
// 创建一个TopologyBuilder对象
TopologyBuilder builder = new TopologyBuilder();
// 添加一个SOURCE,接收两个参数,param1 定义一个名称,param2 从哪一个topic读取消息
builder.addSource("SOURCE", "topic-input")
// 添加第一个PROCESSOR,param1 定义一个processor名称,param2 processor实现类,param3 指定一个父名称
.addProcessor("PROCESS1", MyProcessorA::new, "SOURCE")
// 添加第二个PROCESSOR,param1 定义一个processor名称, param2 processor实现类,param3 指定一个父名称
.addProcessor("PROCESS2", MyProcessorB::new, "PROCESS1")
// 添加第三个PROCESSOR,param1 定义一个processor名称, param2 processor实现类,param3 指定一个父名称
.addProcessor("PROCESS3", MyProcessorC::new, "PROCESS2")
// 最后添加SINK位置,param1 定义一个sink名称,param2 指定一个输出TOPIC,param3 指定接收哪一个PROCESSOR的数据
.addSink("SINK1", "topicA", "PROCESS1")
.addSink("SINK2", "topicB", "PROCESS2")
.addSink("SINK3", "topicC", "PROCESS3");
// 创建一个KafkaStreams对象,传入TopologyBuilder和StreamsConfig
KafkaStreams kafkaStreams = new KafkaStreams(builder, config);
// 启动kafkaStreams
kafkaStreams.start();
}
}
MyProcessor 实现Processor接口
/**
* 自定义处理器,实现processor接口
* 1. 在init方法中做初始化
* 2. process中接收到key / value pair,对value做处理,最后可以在里面做forward。
* 3. punctuate
*/
public class MyProcessorA implements Processor<String, String> { private ProcessorContext context; @Override
public void init(ProcessorContext processorContext) {
this.context = processorContext;
this.context.schedule(1000);
} /**
* @param key 消息的key
* @param value 消息的value
*/
@Override
public void process(String key, String value) {
String line = value + "MyProcessor A ---- "; // 将处理完成的数据转发到downstream processor,比如当前是processor1处理器,通过forward流向到processor2处理器
context.forward(key, line);
} @Override
public void punctuate(long timestamp) { } @Override
public void close() { }
}
关于Kafka深入学习视频, 如Kafka领导选举, offset管理, Streams接口, 高性能之道, 监控运维, 性能测试等,
请关注个人微信公众号: 求学之旅, 发送Kafka, 即可收获Kafka学习视频大礼包一枚。

参考文章:
http://blog.csdn.net/mayp1/article/details/51626643
http://blog.csdn.net/ransom0512/article/details/52038548
https://blog.csdn.net/blwinner/article/details/53637932
https://blog.csdn.net/u012373815/article/details/53648757
https://blog.csdn.net/u012373815/article/details/53728101
https://blog.csdn.net/lmh94604/article/details/53187935
官方网站:
http://kafka.apache.org/documentation/streams/
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams
https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Stream+Usage+Patterns
大全Kafka Streams的更多相关文章
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kafka Streams 剖析
1.概述 Kafka Streams 是一个用来处理流式数据的库,属于Java类库,它并不是一个流处理框架,和Storm,Spark Streaming这类流处理框架是明显不一样的.那这样一个库是做什 ...
- 浅谈kafka streams
随着数据时代的到来,数据的实时计算也越来越被大家重视.实时计算的一个重要方向就是实时流计算,目前关于流计算的有很多成熟的技术实现方案,比如Storm.Spark Streaming.flink等.我今 ...
- 初探kafka streams
1.启动zookeeper zkServer.cmd 2.启动kafka kafka-server-start.bat d:\soft\tool\Kafka\kafka_2.12-2.1.0\conf ...
- Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- 手把手教你写Kafka Streams程序
本文从以下四个方面手把手教你写Kafka Streams程序: 一. 设置Maven项目 二. 编写第一个Streams应用程序:Pipe 三. 编写第二个Streams应用程序:Line Split ...
- Kafka Streams演示程序
本文从以下六个方面详细介绍Kafka Streams的演示程序: Step 1: 下载代码 Step 2: 启动kafka服务 Step 3: 准备输入topic并启动Kafka生产者 Step 4: ...
- 简介Kafka Streams
本文从以下几个方面介绍Kafka Streams: 一. Kafka Streams 背景 二. Kafka Streams 架构 三. Kafka Streams 并行模型 四. Kafka Str ...
随机推荐
- Spark Streaming job的生成及数据清理总结
关于这次总结还是要从一个bug说起....... 场景描述:项目的基本处理流程为:从文件系统读取每隔一分钟上传的日志并由Spark Streaming进行计算消费,最后将结果写入InfluxDB中,然 ...
- 【Keil】Keil5的安装和破...
档案的话网上很多的,另外要看你开发的是哪种内核的芯片 如果是STC的,就安装C51 如果是STM的,就安装MDK 当然市面上有很多芯片的,我也没用过那么多种,这里也就不列举了 至于注册机,就是...恩 ...
- Python学习笔记六:集合
集合 Set,去重,关系测试:交.并.差等:无序 list_1=set(list_1), type(list_1) list_2=set([xxxxx]) 交集:list_1.intersectin( ...
- (数据科学学习手札45)Scala基础知识
一.简介 由于Spark主要是由Scala编写的,虽然Python和R也各自有对Spark的支撑包,但支持程度远不及Scala,所以要想更好的学习Spark,就必须熟练掌握Scala编程语言,Scal ...
- python--模块之random随机数模块
作用是产生随机数 import random random.random:用于生成一个0--1的随机浮点数. print(random.random())>>0.3355102133472 ...
- linux如何制作程序桌面快捷方式
1.生成通过apt或者dpkg安装的程序的桌面快捷方式 他们的快捷方式在/usr/share/applications中,比如我们要生成火狐的桌面快捷方式,执行下列命令 cp /usr/share/a ...
- PHP.47-TP框架商城应用实例-后台22-权限管理-角色和管理员的关系
角色和管理员的关系 角色功能 管理员功能 角色与管理的关联要通过管理-角色表进行{多对多} /********* 管理-角色表 *********/ drop if exists p39_admin_ ...
- HIS系统两种收费模式比较:前计费和后计费
一.药品 a.前计费:审核(临时医嘱)或者分解(长期医嘱)计费 退费处理方式,1)如果是还未发药,则护士站直接退费;2)如果药房已经发药,则护士站发出退费申请,由护士拿着药品去药房退药退费. b.后计 ...
- 最新flowable研究学习及其汉化flowable6.3中文
flowable 是activiti的分支,现在感觉比activiti要强大一些,官网是 https://flowable.org/ 下载最新的6.31版本. 放到tomcat下面,汉化需要对flow ...
- 欧陆词典PEST2词库
欧陆词典PEST2单词列表,其中大概1900+单词,可能有少数几个没有录入,但不影响使用!