K-means聚类算法与EM算法
K-means聚类算法
K-means聚类算法也是聚类算法中最简单的一种了,但是里面包含的思想却不一般。
聚类属于无监督学习。在聚类问题中,给我们的训练样本是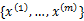 ,每个
,每个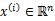 ,没有了y。
,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
1、 随机选取k个聚类质心点(cluster centroids)为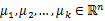 。
。
2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类
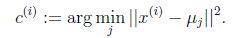
对于每一个类j,重新计算该类的质心
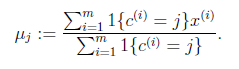
}
K是我们事先给定的聚类数, 代表样例i与k个类中距离最近的那个类,
代表样例i与k个类中距离最近的那个类, 的值是1到k中的一个。质心
的值是1到k中的一个。质心 代表我们对属于同一个类的样本中心点的猜测,重复迭代第一步和第二步直到质心不变或者变化很小。
代表我们对属于同一个类的样本中心点的猜测,重复迭代第一步和第二步直到质心不变或者变化很小。
K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:

J函数表示每个样本点到其质心的距离平方和。
K-means是要将J调整到最小。
假设当前J没有达到最小值,那么首先可以固定每个类的质心 ,调整每个样例的所属的类别
,调整每个样例的所属的类别 来让J函数减少,同样,固定
来让J函数减少,同样,固定 ,调整每个类的质心
,调整每个类的质心 也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,
也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时, 和c也同时收敛。
和c也同时收敛。
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的 和c输出。
和c输出。
下面累述一下K-means与EM的关系:
首先回到初始问题,我们目的是将样本分成K个类,其实说白了就是求一个样本例的隐含类别y,然后利用隐含类别将x归类。由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎样评价假定的好不好呢?
我们使用样本的极大似然估计来度量,这里就是x和y的联合分布P(x,y)了。如果找到的y能够使P(x,y)最大,那么我们找到的y就是样例x的最佳类别了,x顺手就聚类了。但是我们第一次指定的y不一定会让P(x,y)最大,而且P(x,y)还依赖于其他未知参数,当然在给定y的情况下,我们可以调整其他参数让P(x,y)最大。但是调整完参数后,我们发现有更好的y可以指定,那么我们重新指定y,然后再计算P(x,y)最大时的参数,反复迭代直至没有更好的y可以指定。
这个过程有几个难点:
第一怎么假定y?是每个样例硬指派一个y还是不同的y有不同的概率,概率如何度量。
第二如何估计P(x,y),P(x,y)还可能依赖很多其他参数,如何调整里面的参数让P(x,y)最大。
EM算法的思想:E步就是估计隐含类别y的期望值,M步调整其他参数使得在给定类别y的情况下,极大似然估计P(x,y)能够达到极大值。然后在其他参数确定的情况下,重新估计y,周而复始,直至收敛。
从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量 ,M步更新其他参数
,M步更新其他参数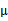 来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
EM算法就是这样,假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM的意思是“Expectation Maximization”
http://blog.csdn.net/zouxy09/article/details/8537620
K-means聚类算法与EM算法的更多相关文章
- MM 算法与 EM算法概述
1.MM 算法: MM算法是一种迭代优化方法,利用函数的凸性来寻找它们的最大值或最小值. MM表示 “majorize-minimize MM 算法” 或“minorize maximize MM 算 ...
- 机器学习优化算法之EM算法
EM算法简介 EM算法其实是一类算法的总称.EM算法分为E-Step和M-Step两步.EM算法的应用范围很广,基本机器学习需要迭代优化参数的模型在优化时都可以使用EM算法. EM算法的思想和过程 E ...
- 【机器学习】K-means聚类算法与EM算法
初始目的 将样本分成K个类,其实说白了就是求一个样本例的隐含类别y,然后利用隐含类别将x归类.由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎样评价假定 ...
- Python实现机器学习算法:EM算法
''' 数据集:伪造数据集(两个高斯分布混合) 数据集长度:1000 ------------------------------ 运行结果: ---------------------------- ...
- 机器学习十大算法之EM算法
此文已由作者赵斌授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 由于目前论坛的Markdown不支持Mathjax,数学公式没法正常识别,文章只能用截图上传了... ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- EM 算法-对鸢尾花数据进行聚类
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍过K 均值算法,它是一种聚类算法.今天介绍EM 算法,它也是聚类算法,但比K 均值算法更加灵活强大. ...
- EM算法(1):K-means 算法
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(1) : K-means算法 1. 简介 K-mean ...
- 极大似然估计、贝叶斯估计、EM算法
参考文献:http://blog.csdn.net/zouxy09/article/details/8537620 极大似然估计 已知样本满足某种概率分布,但是其中具体的参数不清楚,极大似然估计估计就 ...
随机推荐
- MongoDB入门---聚合操作&管道操作符&索引的使用
经过前段时间的学习呢,我们对MongoDB有了一个大概的了解,接下来就要开始使用稍稍深入一点的东西了,首先呢,就是MongoDB中的聚合函数,跟mysql中的count等函数差不多.话不多说哈,我们先 ...
- vue-router核心概念
vue用来实现SPA的插件 使用vue-router 1. 创建路由器: router/index.js new VueRouter({ routes: [ { // 一般路由 path: '/abo ...
- 20154327 Exp3 免杀原理与实践
实践内容 基础问题回答 (1)杀软是如何检测出恶意代码的? 杀毒软件主要靠特征码进行查杀,匹配到即为病毒. 还有通过云查杀,查看云端库中该文件是否属于恶意代码. 跟踪该程序运行起来是否存在恶意行为,来 ...
- 20145209 2016-2017-2 《Java程序设计》第2周学习总结
20145209 2016-2017-2 <Java程序设计>第2周学习总结 教材学习内容总结 git log 命令来查看 :提交历史 查看当前所处位置: pwd git 版本控制 tou ...
- MapWinGIS使用
.net语言中使用MapWinGIS.ocx http://www.cnblogs.com/kekec/archive/2011/03/30/1999709.html 基于MapWinGis的开发探索 ...
- Dinic算法最大流入门
例题传送门 Dinic算法是网络流最大流的优化算法之一,每一步对原图进行分层,然后用DFS求增广路.时间复杂度是O(n^2*m),Dinic算法最多被分为n个阶段,每个阶段包括建层次网络和寻找增广路两 ...
- 成都Uber优步司机奖励政策(3月21日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 【SQLSERVER】从数据库文件mdf中拆分ndf的方法和利弊
一.数据文件格式 SQLSERVER中,数据库的文件后缀有3种:mdf.ndf.ldf. 如下图所示,DW_TEST.mdf.DW_TEST_HIS.ndf.DW_TEST.ldf 属于同一个数据库T ...
- Qt-QML-Slider-滑块-Style-后继
首先了,先把我上篇文章的demo准备好,不过我上次写的被我删除了,这次就重新写了一个,上代码 import QtQuick 2.5 import QtQuick.Controls 1.4 import ...
- ReadyAPI 教程和示例(二)
声明:如果你想转载,请标明本篇博客的链接,请多多尊重原创,谢谢! 本篇使用的 ReadyAPI版本是2.5.0 接上一篇: 4.修改SoapUI测试 本节将演示如何为测试用例添加测试步骤以及更改请求参 ...