elk+kafka+zookeeper+filebeat安装
ElasticSearch6.0
ElasticSearch6.0安装
#依赖jdk8
rpm -ivh elasticsearch-6.0..rpm
vim /etc/elasticsearch/elasticsearch.yml #配置如下
node.name: es1
node.master: true
node.data: true
path.data: /home/es/data
path.logs: /home/es/logs
network.host: 192.168.55.215
http.port:
bootstrap.memory_lock: false #centos6需要
bootstrap.system_call_filter: false #centos6需要
##以下两项是head插件访问es需要配置
http.cors.enabled: true
http.cors.allow-origin: "*"
# 设置索引的分片数,默认为5
#index.number_of_shards:
# 设置索引的副本数,默认为1:
#index.number_of_replicas:
mkdir -p /home/es/{data,logs}
chown -R elasticsearch.elasticsearch /home/es
vim /etc/security/limits.conf #添加或修改以下内容
* hard nproc
* soft nproc
* hard nofile
* soft nofile
/etc/elasticsearch/jvm.options #更改启动内存,测试环境512M就可以了
-Xms1g
-Xmx1g
/etc/sysconfig/elasticsearch #启动脚本的一些环境变量例如 JAVA_HOME=/opt/java /etc/init.d/elasticsearch start #启动es
ElasticSearch配置文件详解
https://blog.csdn.net/zxf_668899/article/details/54582849
ElasticSearch6.0-head插件安装(界面查看es索引)
#网址:http://www.cnblogs.com/Onlywjy/p/Elasticsearch.html
#包D:\share\src\elk\elk6.\elasticsearch-head插件
.安装node
tar -C /opt/ -zxvf node-v4.4.7-linux-x64.tar.gz vim /etc/profile.d/node.sh #配置node环境变量
export NODE_HOME=/opt/node-v4.4.7-linux-x64
export PATH=$PATH:$NODE_HOME/bin
export NODE_PATH=$NODE_HOME/lib/node_modules
source /etc/profile.d/node.sh .安装grunt
unzip elasticsearch-head-master.zip
cd elasticsearch-head-master
npm install -g grunt-cli //执行后会生成node_modules文件夹 grunt -version #检查是否安装成功 修改head插件源码
修改服务器监听地址:Gruntfile.js #93行,默认端口号库9100
修改连接地址:_site/app.js #4354行,修改es连接地址,注意这个地址只能是外网地址,相对于访问head的机子 .运行head
在elasticsearch-head-master目录下
npm install #(安装下载下来的包,如果出错再执行一遍)
grunt server & #后台启动、netstat -lnp | grep
.访问http://xxx:9100 5.head使用(添加索引,往索引里写数据,修改索引数据,删除索引)
https://www.cnblogs.com/yanan7890/p/6640289.html
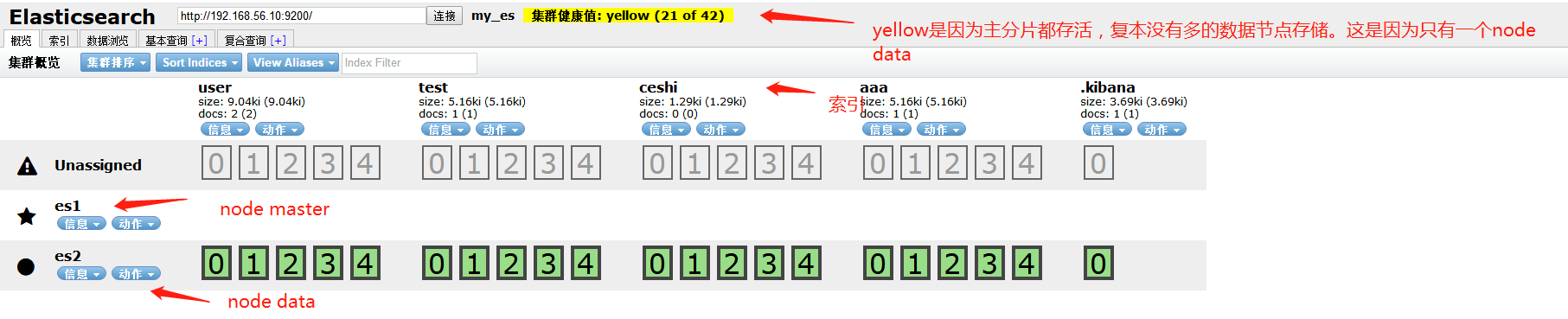
ElasticSearch6.0索引清理
curl -XGET 'http://192.168.55.219:9200/_cat/indices/?v' #查询索引
curl -XDELETE 'http://127.0.0.1:9200/logstash-2016-07-*' #api删除索引 脚本加api删除(推荐)
vim /opt/sh/es-index-clear.sh #/bin/bash #指定日期(7天前)
DATA=`date -d "1 week ago" +%Y.%m.%d` #当前日期
time=`date` #删除7天前的日志
curl -XDELETE http://127.0.0.1:9200/*-${DATA} if [ $? -eq ];then
echo $time"-->del $DATA log success.." >> /tmp/es-index-clear.log
else
echo $time"-->del $DATA log fail.." >> /tmp/es-index-clear.log
fi
添加到任务计划
crontab -e
* * * sh /tmp/es-index-clear.sh > /dev/null >&
elasticSearch常用命令
原网址:https://zhaoyanblog.com/archives/732.html
curl 'localhost:9200/_cluster/health?pretty' 健康检查
curl 'localhost:9200/_cluster/state?pretty' 集群详细信息
curl -XPUT http://localhost:9200/user #添加索引
curl -H "Content-Type:application/json" -XPUT http://192.168.56.10:9200/user/ceshi/1/ -d '{"id":2,"name":"ceshi2","age":222}' #索引里写文档,user是索引,ceshi是索引类型,1是索引id
curl -XGET http://localhost:9200/user #查看索引内容
curl -XDELETE http://localhost:9200/user #删除索引,支持通配符
elasticsearch集群
集群配置文件
#node-master
cluster.name: my_es
node.name: es1
node.master: true
node.data: false
path.data: /home/es/data
path.logs: /home/es/logs
network.host: 0.0.0.0
http.port:
http.cors.enabled: true #head连接需要(head连接到主)
http.cors.allow-origin: "*" #head连接需要(head连接到主)
discovery.zen.ping.unicast.hosts: ["192.168.56.10","192.168.56.11:9200","192.168.56.12:9200"] #node-data1
cluster.name: my_es
node.name: es2
node.master: false
node.data: true
path.data: /home/es/data
path.logs: /home/es/logs
network.host: 0.0.0.0
http.port:
discovery.zen.ping.unicast.hosts: ["192.168.56.10","192.168.56.11:9200","192.168.56.12:9200"] #node-data2
cluster.name: my_es
node.name: es3
node.master: false
node.data: true
path.data: /home/es/data
path.logs: /home/es/logs
network.host: 0.0.0.0
http.port:
discovery.zen.ping.unicast.hosts: ["192.168.56.10","192.168.56.11:9200","192.168.56.12:9200"] ##说明
页面登入head 带星的节点为master
安装kibana和使用
kibana安装
rpm -ivh kibana-6.0.-x86_64.rpm
vim /etc/kibana/kibana.yml
server.port:
server.host: 0.0.0.0
elasticsearch.url: "http://192.168.56.10:9200" #连接到主
logging.dest: /var/log/kibana/kibana.log
/etc/init.d/kibana start #默认端口5601 kibana6.0官方文档
https://www.elastic.co/guide/en/kibana/6.0/index.html
kibana添加索引
http://192.168.56.10:5601
1.
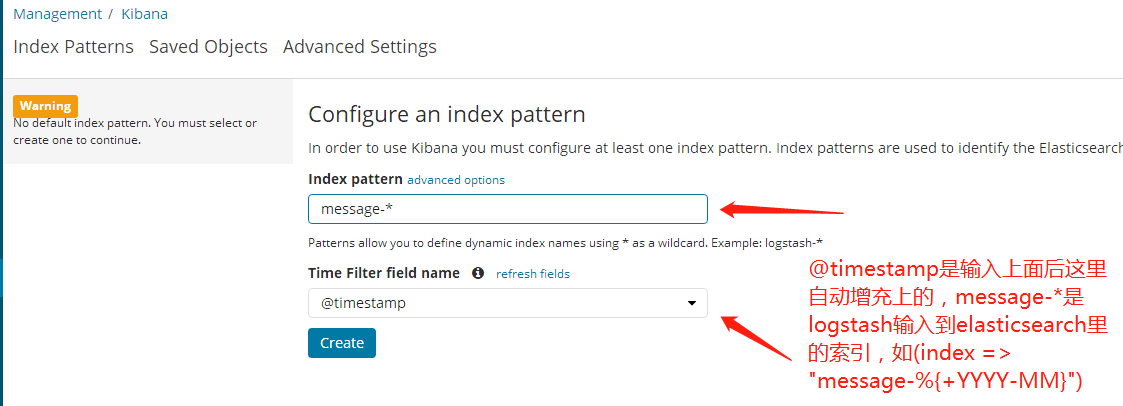
2.
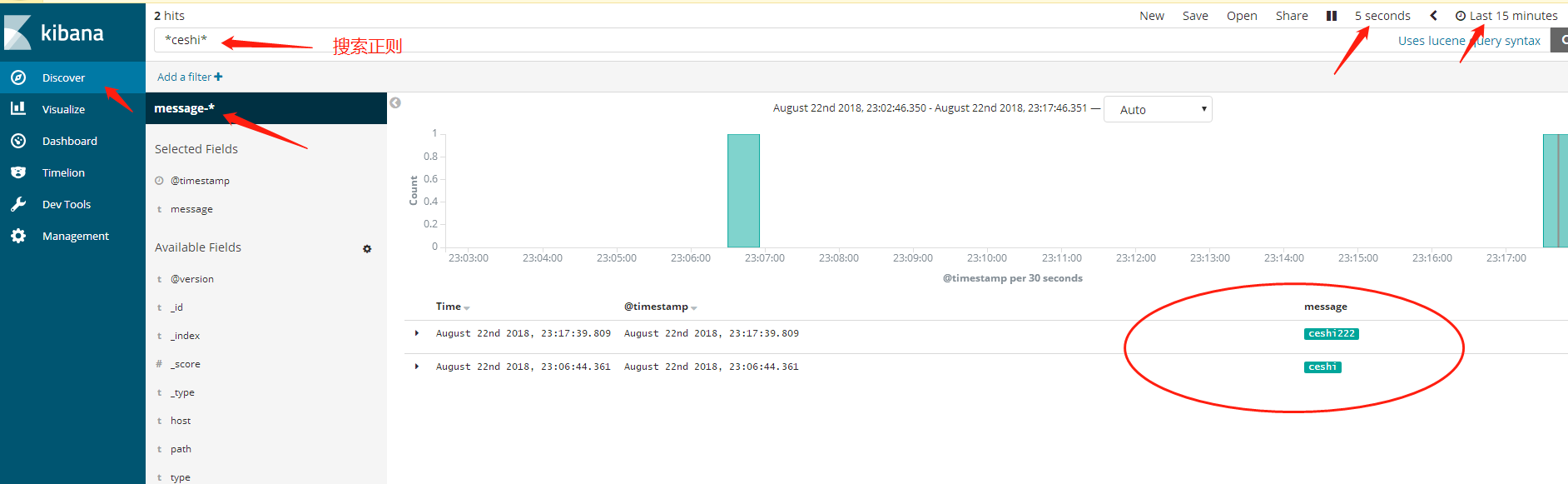
kibana对索引内容搜索
1.
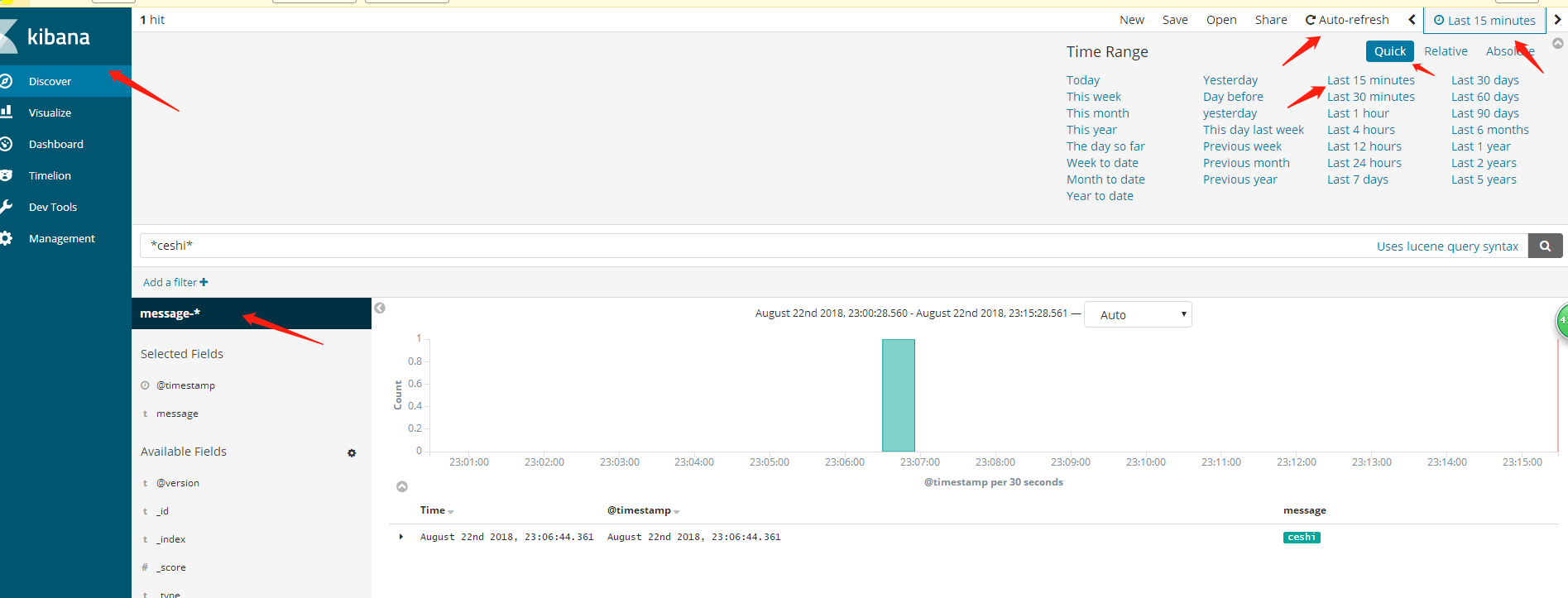
2.
logstash安装和使用例子
logstash安装
ln -sv /opt/apps/java/bin/java /usr/bin/
rpm -ivh logstash-6.0..rpm
目录结构:
/usr/share/logstash/bin
/var/lib/logstash
/var/log/logstash
注意这几个目录的用户和组必须是logstash
如果用root用户启动logstash后 需要把上面几个目录的用户和组修改下(chown -R logstash.logstash xxxx)
#生成启动脚本
、要跟startup.options文件的绝对路径,如果是rpm安装的在/etc/logstash/startup.options,如果是二进制包解压安装的则在解压目录下的config目录下面。 、必须要跟启动类型,比如CentOS6是sysv,CentOS7是systemd。(备注:sysv在centos7里也能用) 、执行脚本生成启动文件
/usr/share/logstash/bin/system-install /etc/logstash/startup.options sysv
、修改/etc/init.d/logstash
75行 >> /var/log/logstash/logstash-plain.log >> /var/log/logstash/logstash-plain.log
#更改日志目录权限
chown -R logstash.logstash /var/log/logstash #配置Logstash to elasticsearch文件
vim /etc/logstash/conf.d/log_to_es.conf
=========================================
input{
file{
path => "/var/log/messages"
start_position => "beginning"
type => "message"
}
}
output{
if [type] == "message" {
elasticsearch{
hosts => "192.168.56.10:9200"
#hosts => ["10.10.1.90:9200","10.10.1.60:9200"] #多node data 就里配置的是node data,不要配置node master
index => "message-%{+YYYY-MM}"
#index => "message-%{+YYYY-MM-dd}"
}
}
}
========================================
#更改/var/log/messages权限
chmod 644 /var/log/messages
#检查配置文件有没有错误
/usr/share/logstash/bin/logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/log_to_es.conf --config.test_and_exit
#启动
/etc/init.d/logstash start
#检查启动是否成功
netstat -lnp | grep 或查看日志 tail -f /var/log/logstash/logstash-plain.log
elk+kafka+zookeeper+filebeat安装的更多相关文章
- Kafka+Zookeeper+Filebeat+ELK 搭建日志收集系统
ELK ELK目前主流的一种日志系统,过多的就不多介绍了 Filebeat收集日志,将收集的日志输出到kafka,避免网络问题丢失信息 kafka接收到日志消息后直接消费到Logstash Logst ...
- ELK5.2+kafka+zookeeper+filebeat集群部署
架构图 考虑到日志系统的可扩展性以及目前的资源(部分功能复用),整个ELK架构如下: 架构解读 : (整个架构从左到右,总共分为5层) 第一层.数据采集层 最左边的是业务服务器集群,上面安装了file ...
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台(elk5.2+filebeat2.11)
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台 参考:http://www.tuicool.com/articles/R77fieA 我在做ELK日志平台开始之初选择为 ...
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
日志分析平台,架构图如下: 架构解读 : (整个架构从左到右,总共分为5层) 第一层.数据采集层 最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logs ...
- ELK + Kafka + Filebeat
ELK + Kafka + Filebeat学习 https://blog.csdn.net/qq_21383435/article/details/79463832 https://blog.csd ...
- ELK+KAFKA安装部署指南
一.ELK 背景 通常,日志被分散的储存不同的设备上.如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志.这样是不是感觉很繁琐和效率低下.当务之急我们使用集中化的日志管理,例如: ...
- zookeeper+kafka集群安装之二
zookeeper+kafka集群安装之二 此为上一篇文章的续篇, kafka安装需要依赖zookeeper, 本文与上一篇文章都是真正分布式安装配置, 可以直接用于生产环境. zookeeper安装 ...
- zookeeper+kafka集群安装之一
zookeeper+kafka集群安装之一 准备3台虚拟机, 系统是RHEL64服务版. 1) 每台机器配置如下: $ cat /etc/hosts ... # zookeeper hostnames ...
- ELK 架构之 Logstash 和 Filebeat 安装配置
上一篇:ELK 架构之 Elasticsearch 和 Kibana 安装配置 阅读目录: 1. 环境准备 2. 安装 Logstash 3. 配置 Logstash 4. Logstash 采集的日 ...
随机推荐
- 类TreeMap
TreeMap类 import java.util.Set; import java.util.TreeMap; public class IntegerDemo { public static vo ...
- log4j配置参数详解——按日志文件大小、日期切分日志文件
项目中尽管对log4j有基本的配置,例如按天生成日志文件以作区分,但如果系统日志文件过大,则就需要考虑以更小的单位切分或者其他切分方式.下面就总结一下log4j常用的配置参数以及切分日志的不同方式. ...
- 【SD系列】SAP 查看销售订单时,报了一个错误消息,“项目不符合计划行(程序错误)”
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[SD系列]SAP 查看销售订单时,报了一个错误 ...
- [Udemy] ES 7 and Elastic Stack - part 1
Section 1 基本概念: Index(indices) 相当于 关系型数据库的 table, document 相当于关系型数据库的 row, 还有一个type的概念(可以理解为table的s ...
- C#MessageBox 自动关闭窗口
1:MessageBox弹出的模式窗口会先阻塞掉它的父级线程.所以我们可以考虑在MessageBox前先增加一个用于"杀"掉MessageBox窗口的线程.因为需要在规定时间内&q ...
- Taro -- 微信小程序密码弹窗
记录一个类似支付密码的弹窗写法,实现是否免密功能.如图: index.js import Taro, { Component } from '@tarojs/taro' import { Vi ...
- javaweb各种框架组合案例(七):springboot+jdbcTemplete+通用dao+restful
一.介绍 1.springboot是spring项目的总结+整合 当我们搭smm,ssh,ssjdbc等组合框架时,各种配置不胜其烦,不仅是配置问题,在添加各种依赖时也是让人头疼,关键有些jar包之间 ...
- 奇虎360的开源OpenResty Windows版本
https://github.com/LomoX-Offical/nginx-openresty-windows
- python常用函数 V
vars(object) 返回对象object的属性和属性值的字典对象.不输入参数,就打印当前调用位置的属性和属性值,相当于locals()的功能. 例子:
- 实现memcpy()函数及过程总结
1.为什么会写memcpy 在之前的应聘笔试上遇到一道笔试题,题目要求实现一个my_memcpy函数.函数原型:void * my_memcpy(void *dst, const void *src, ...