HBASE学习笔记(二)
一、HBASE内部原理
1.hbase系统架构
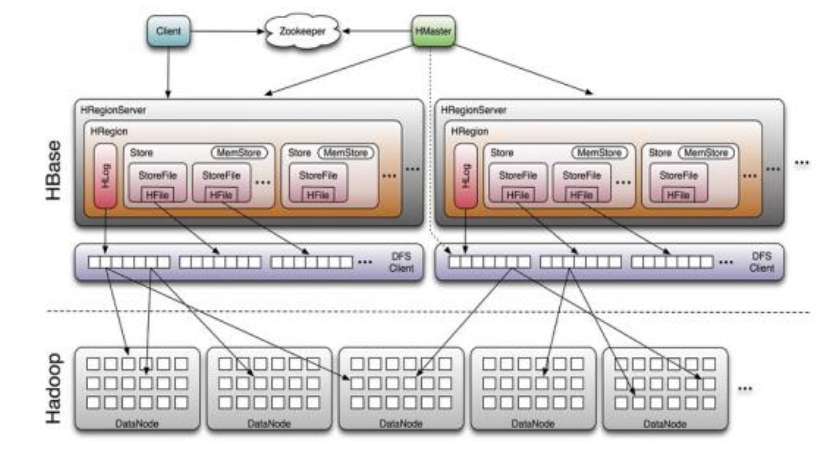
上图组件介绍;
1):Client 包含访问 hbase 的接口, client 维护着一些 cache 来加快对 hbase 的访问,比如 region 的位置信息。
2):Zookeeper
1 保证任何时候,集群中只有一个 master
2 存贮所有 Region 的寻址入口----root 表在哪台服务器上。
3 实时监控 Region Server 的状态,将 Region server 的上线和下线信息实时通知给 Master
4 存储 Hbase 的 schema,包括有哪些 table,每个 table 有哪些 column family
3):Master 职责
1.为 Region server 分配 region
2.负责 region server 的负载均衡
3.发现失效的 region server 并重新分配其上的 region
4.HDFS 上的垃圾文件回收
5.处理 schema 更新请求
4):Region Server 职责
1.Region server 维护 Master 分配给它的 region,处理对这些 region 的 IO 请求
2.Region server 负责切分在运行过程中变得过大的 region可以看到, client 访问 hbase 上数据的过程并不需要 master 参与(寻址访问 zookeeper 和region server,数据读写访问 regione server), master 仅仅维护着
table 和 region 的元数据信息,负载很低。
client端交互的过程:
0).hbase集群启动时,master负责分配区域region到指定的区域服务器hregionserver
1).联系zk,找出meta表所在的rs(regionserver),即: /hbase/meta-region-server
2)定位rowkey,找到对应的regionserver
3)缓存信息在本地
4)联系regionserver
5)regionserver负责open Hregion对象,为每个列族创建store对象,store又包含多个storeFile,他们是对HFile的轻量级的封装,每个store还对应一个MemStore,用于内存存储数据
WAL目录结构构成:
hdfs://s201:8020/hbase/WALs/{区域服务器名称,主机名,端口号}
2.hbase整体架构
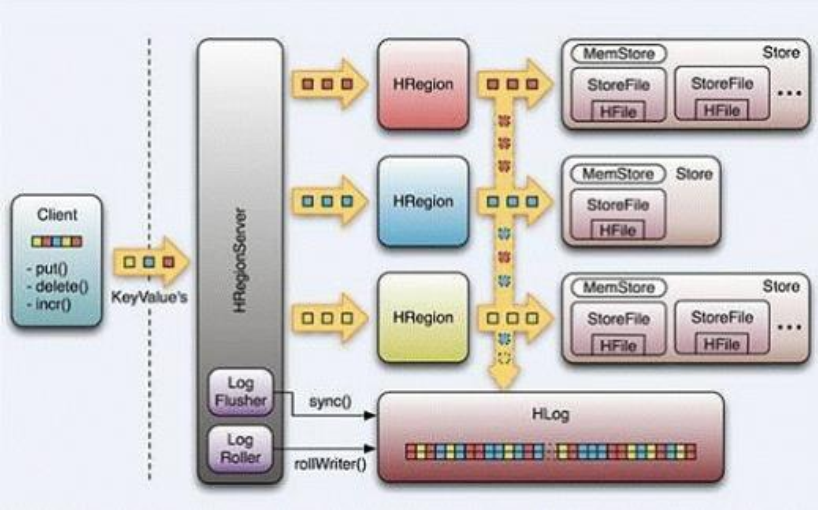
1 Table 中的所有行都按照 row key 的字典序排列。
2 Table 在行的方向上分割为多个 Hregion。
3 region 按大小分割的(默认 10G),每个表一开始只有一个 region,随着数据不断插入表,region 不断增大,当增大到一个阀值的时候, Hregion 就会等分会两个新的 Hregion。当 table中的行不断增多,就会有越来越多的 Hregion。
4 Hregion 是 Hbase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的 Hregion可以分布在不同的 HRegion server 上。但一个 Hregion 是不会拆分到多个 regionserver 上的。HRegion 虽然是负载均衡的最小单元,但并不是物理存储的最小单元。事实上, HRegion 由一个或者多个 Store 组成, 每个 store 保存一个 column family。每个 Strore 又由一个 memStore 和 0 至多个 StoreFile 组成。如上图
5.Hbase里面一定要指定rowkey,我们在查询的具体的存储信息的时候可以查询meta表:$hbase>scan 'hbase:meta'
6.hbase基于hdfs,相同列族的数据存放在同一个文件中,不同的列族在不同的文件中:hdfs://s201:8020/hbase/data/${名字空间}/${表名}/${区域名称}/{区域名称}/{列族名称}/{文件名}
3、STORE FILE 和HFILE 结构
StoreFile 以 HFile 格式保存在 HDFS 上。 其中HFile的文件格式如下:
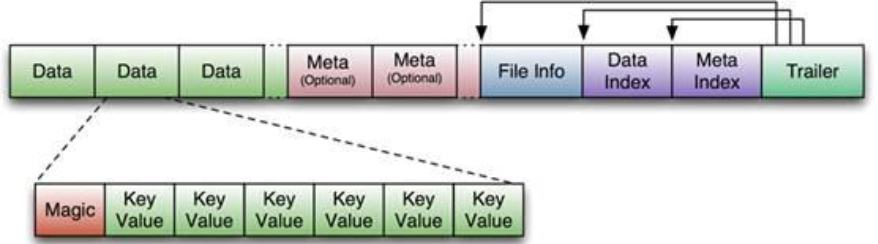
首先 HFile 文件是不定长的,长度固定的只有其中的两块: Trailer 和 FileInfo。正如图中所示的, Trailer 中有指针指向其他数据块的起始点。File Info 中记录了文件的一些 Meta 信息,例如: AVG_KEY_LEN, AVG_VALUE_LEN,LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY 等。Data Index 和 Meta Index 块记录了每个 Data 块和 Meta 块的起始点。Data Block 是 HBase I/O 的基本单元,为了提高效率, HRegionServer 中有基于 LRU 的 BlockCache 机制。每个 Data 块的大小可以在创建一个 Table 的时候通过参数指定,大号的 Block有利于顺序 Scan,小号 Block 利于随机查询。 每个 Data 块除了开头的 Magic 以外就是一个个 KeyValue 对拼接而成, Magic 内容就是一些随机数字,目的是防止数据损坏。HFile 里面的每个 KeyValue 对就是一个简单的 byte 数组。但是这个 byte 数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构

开始是两个固定长度的数值,分别表示 Key 的长度和 Value 的长度。紧接着是 Key,开始是 固定长度的数值,表示 RowKey 的长度,紧接着是 RowKey,然后是固定长度的数值,表示Family 的长度,然后是 Family,接着是 Qualifier,然后是两个固定长度的数值,表示 TimeStamp 和 Key Type(Put/Delete)。 Value 部分没有这么复杂的结构,就是纯粹的二进制数据了。HFile 分为六个部分:Data Block 段– 保存表中的数据,这部分可以被压缩Meta Block 段 (可选的)– 保存用户自定义的 kv 对,可以被压缩。File Info 段– Hfile 的元信息,不被压缩,用户也可以在这一部分添加自己的元信息Data Block Index 段– Data Block 的索引。每条索引的 key 是被索引的 block 的第一条记录的 key。Meta Block Index 段 (可选的)– Meta Block 的索引。Trailer– 这一段是定长的。保存了每一段的偏移量,读取一个 HFile 时,会首先 读取Trailer, Trailer 保存了每个段的起始位置(段的 Magic Number 用来做安全 check),然后,DataBlock Index 会被读取到内存中,这样,当检索某个 key 时,不需要扫描整个 HFile,而只需从内存中找到 key 所在的 block,通过一次磁盘 io 将整个 block 读取到内存中,再找到需要的 key。 DataBlock Index 采用 LRU 机制淘汰。HFile 的 Data Block, Meta Block 通常采用压缩方式存储,压缩之后可以大大减少网络IO 和磁盘 IO,随之而来的开销当然是需要花费 cpu 进行压缩和解压缩。目标 Hfile 的压缩支持两种方式: Gzip, Lzo。
先写到这里吧,后面有什么需要补充的再来写
HBASE学习笔记(二)的更多相关文章
- hbase 学习笔记二----shell
Hbase 是一个分布式的.面向列的开源数据库,其实现是建立在google 的bigTable 理论之上,并基于hadoop HDFS文件系统. Hbase不同于一般的关系型数据库 ...
- HBASE学习笔记(四)
这两天把要前几天的知识点回顾一下,接下来我会用自己对知识点的理解来写一些东西 一.知识点回顾 1.hbase集群启动:$>start-hbase.sh ===>hbase-daemon.s ...
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- JMX学习笔记(二)-Notification
Notification通知,也可理解为消息,有通知,必然有发送通知的广播,JMX这里采用了一种订阅的方式,类似于观察者模式,注册一个观察者到广播里,当有通知时,广播通过调用观察者,逐一通知. 这里写 ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
随机推荐
- spark RDD 的基本操作
好记性不如烂笔头,分享一下 Spark是一个计算框架,是对mapreduce计算框架的改进,mapreduce计算框架是基于键值对也就是map的形式,之所以使用键值对是人们发现世界上大部分计算都可以使 ...
- CoreData编辑器
如何你开发iOS使用的是CoreData数据库的话,肯定想要一个可以查看和编辑CoreData数据库的工具,今天给大家推荐一个工具Core-Data-Editor 下载地址:https://githu ...
- STS热部署方法(springboot)
sts热部署,即是在项目中修改代码不用重新启动服务,提高效率. 方法如下: 1.在pom文件中引入 devtools 依赖: <dependency> <groupId> ...
- JavaScript疑难杂症系列-事件
事件这块知识点虽然是老生长谈的,但对于我来说多多整理,多多感悟,温故知新,每次看看这块都有不同的收获.(在这里我不会长篇大论,只会挑重点;具体的小伙伴们自行查找) 什么是事件 在编程时系统内发生的动作 ...
- leetcode 17电话号码的字母组合
与子集70?类似,子集每次两个分支,本题每次k个分支,子集是第一次不push第二次push元素,本题是每次都push元素,因此,本题答案的长度都为k,子集题目为各种组合: /** res,level, ...
- UI自动化-selenium-api封装pyse框架
# coding=utf-8 import time from selenium import webdriver from selenium.webdriver.common.action_chai ...
- PyCharm给函数增加文档注释
选择函数名,左上角会出现一个小灯泡,点击小灯泡 选择第二项 选中调用的函数名 Ctrl + Q 显示注释 如何配置操作习惯 File > sitting > 搜索 'keymap' > ...
- 什么是token?你是怎么理解token?
1.Token的引入: Token是在客户端频繁向服务端请求数据,服务端频繁的去数据库查询用户名和密码并进行对比,判断用户名和密码正确与否,并作出相应提示,在这样的背景下,Token便应运而生. 2. ...
- 纯JS实现多图片上传(在layui框架中)
HTML代码 <form id="form1" class="layui-form layui-form-pane" action="{:url ...
- CentOS7 linux系统多种方式安装ClickHouse数据库
clickhouse是由俄罗斯Yandex公司开发的列式存储数据库,于2016年开源,clickhouse的定位是快速的数据分析,对于处理海量数据的情况性能非常好,在网上也有很多测试的案例,在大数据的 ...