spark 笔记 8: Stage
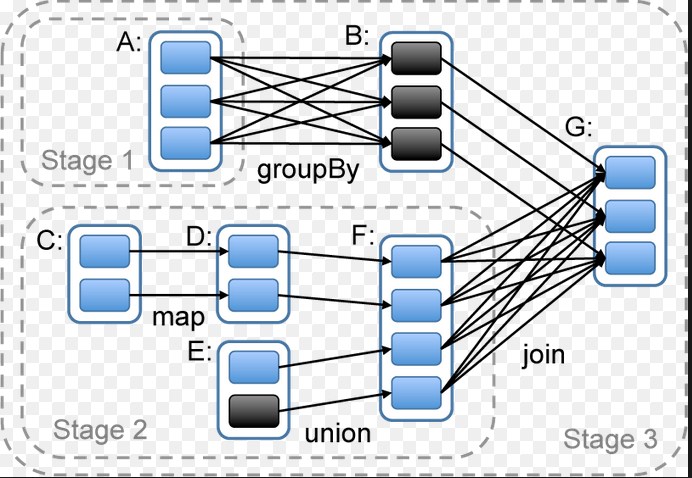
/**
* A stage is a set of independent tasks all computing the same function that need to run as part
* of a Spark job, where all the tasks have the same shuffle dependencies. Each DAG of tasks run
* by the scheduler is split up into stages at the boundaries where shuffle occurs, and then the
* DAGScheduler runs these stages in topological order.
*
* Each Stage can either be a shuffle map stage, in which case its tasks' results are input for
* another stage, or a result stage, in which case its tasks directly compute the action that
* initiated a job (e.g. count(), save(), etc). For shuffle map stages, we also track the nodes
* that each output partition is on.
*
* Each Stage also has a jobId, identifying the job that first submitted the stage. When FIFO
* scheduling is used, this allows Stages from earlier jobs to be computed first or recovered
* faster on failure.
*
* The callSite provides a location in user code which relates to the stage. For a shuffle map
* stage, the callSite gives the user code that created the RDD being shuffled. For a result
* stage, the callSite gives the user code that executes the associated action (e.g. count()).
*
* A single stage can consist of multiple attempts. In that case, the latestInfo field will
* be updated for each attempt.
*
*/
private[spark] class Stage(
val id: Int,
val rdd: RDD[_],
val numTasks: Int,
val shuffleDep: Option[ShuffleDependency[_, _, _]], // Output shuffle if stage is a map stage
val parents: List[Stage],
val jobId: Int,
val callSite: CallSite)
extends Logging {
val isShuffleMap = shuffleDep.isDefined
val numPartitions = rdd.partitions.size
val outputLocs = Array.fill[List[MapStatus]](numPartitions)(Nil)
var numAvailableOutputs = 0
/** Set of jobs that this stage belongs to. */
val jobIds = new HashSet[Int]
/** For stages that are the final (consists of only ResultTasks), link to the ActiveJob. */
var resultOfJob: Option[ActiveJob] = None
var pendingTasks = new HashSet[Task[_]]
def addOutputLoc(partition: Int, status: MapStatus) {
/**
* Result returned by a ShuffleMapTask to a scheduler. Includes the block manager address that the
* task ran on as well as the sizes of outputs for each reducer, for passing on to the reduce tasks.
* The map output sizes are compressed using MapOutputTracker.compressSize.
*/
private[spark] class MapStatus(var location: BlockManagerId, var compressedSizes: Array[Byte])
spark 笔记 8: Stage的更多相关文章
- spark笔记 环境配置
spark笔记 spark简介 saprk 有六个核心组件: SparkCore.SparkSQL.SparkStreaming.StructedStreaming.MLlib,Graphx Spar ...
- Spark 资源调度包 stage 类解析
spark 资源调度包 Stage(阶段) 类解析 Stage 概念 Spark 任务会根据 RDD 之间的依赖关系, 形成一个DAG有向无环图, DAG会被提交给DAGScheduler, DAGS ...
- spark 笔记 15: ShuffleManager,shuffle map两端的stage/task的桥梁
无论是Hadoop还是spark,shuffle操作都是决定其性能的重要因素.在不能减少shuffle的情况下,使用一个好的shuffle管理器也是优化性能的重要手段. ShuffleManager的 ...
- spark 笔记 13: 再看DAGScheduler,stage状态更新流程
当某个task完成后,某个shuffle Stage X可能已完成,那么就可能会一些仅依赖Stage X的Stage现在可以执行了,所以要有响应task完成的状态更新流程. ============= ...
- 大数据学习——spark笔记
变量的定义 val a: Int = 1 var b = 2 方法和函数 区别:函数可以作为参数传递给方法 方法: def test(arg: Int): Int=>Int ={ 方法体 } v ...
- spark 笔记 16: BlockManager
先看一下原理性的文章:http://jerryshao.me/architecture/2013/10/08/spark-storage-module-analysis/ ,http://jerrys ...
- spark 笔记 9: Task/TaskContext
DAGScheduler最终创建了task set,并提交给了taskScheduler.那先得看看task是怎么定义和执行的. Task是execution执行的一个单元. Task: execut ...
- spark 笔记 7: DAGScheduler
在前面的sparkContex和RDD都可以看到,真正的计算工作都是同过调用DAGScheduler的runjob方法来实现的.这是一个很重要的类.在看这个类实现之前,需要对actor模式有一点了解: ...
- spark 笔记 2: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf ucb关于spark的论文,对spark中核心组件RDD最原始.本质的理解, ...
随机推荐
- Tomcat error: failed to start connector [connector[HTTP/1.1-8080]]
出现这个问题多半是因为8080端口被占用了.换一个端口试试
- 03 python3常见内置函数
数学相关 abs(a) : 求取绝对值.abs(-1) max(list) : 求取list最大值.max([1,2,3]) min(list) : 求取list最小值.min([1,2,3]) su ...
- 为什么选择器:last-child有时没有起作用?
想要有.list样式的最后一个不要下划线.为什么:last-child没有起作用? el:last-child 的匹配规则是:第一步,查找 el 选择器匹配元素的所有同级元素(siblings):第二 ...
- 转载:ubuntu 下添加简单的开机自启动脚本
转自:https://www.cnblogs.com/downey-blog/p/10473939.html linux下添加简单的开机自启动脚本 在linux的使用过程中,我们经常会碰到需要将某个自 ...
- echarts图表自适应盒子的大小(盒子的大小是动态改变的),大到需要全屏展示
项目中用到了echarts,并且页面是自适应的,且页面中有一个[放大.缩小]功能,因此图表还需要根据盒子的大小来变化. 即:两个需求,如下: ① 图表根据窗口的大小自适应 ② 图表根据所在盒子的大小自 ...
- NativeScript —— 初级入门(跨平台的手机APP应用)《二》
NativeScript项目结构 根文件夹 package.json —— 这是适用于整个应用程序的NativeScript主项目配置文件. 它基本概述了项目的基本信息和所有平台要求. 当您添加和删除 ...
- IIS7发布asp.net mvc提示404
之前服务器用的都是2003Server的服务器,发布mvc项目都没问题,今天换了一台机器,系统为Windows Server2008 R2 64位的发布mvc项目后就提示: 百度看到好多人说在web ...
- xorm:golang的orm(只写了一小部分)
xorm xorm是一个简单而强大的Go语言ORM库. 通过它可以使数据库操作非常简便.这个库是国人开发的,是基于原版 xorm:https://github.com/go-xorm/xorm 的定制 ...
- maven中使用jetty插件
<plugin> <groupId>org.mortbay.jetty</groupId> <artifactId>jetty-maven-plugin ...
- log4net 报错
之前在网上学习了一种log4net的日志监控,这种方式我觉得很不错,至少我个人认为很好,但是最紧缺发现一个为题,就是再session过期的时候页面跳转时候 会报错,这个搞了很久没搞明白,我直接用例子讲 ...