Flink Batch SQL 1.10 实践
Flink作为流批统一的计算框架,在1.10中完成了大量batch相关的增强与改进。1.10可以说是第一个成熟的生产可用的Flink Batch SQL版本,它一扫之前Dataset的羸弱,从功能和性能上都有大幅改进,以下我从架构、外部系统集成、实践三个方面进行阐述。
架构
Stack

首先来看下stack,在新的Blink planner中,batch也是架设在Transformation上的,这就意味着我们和Dataset完全没有关系了:
- 我们可以尽可能的和streaming复用组件,复用代码,有同一套行为。
- 如果想要Table/SQL的toDataset或者fromDataset,那就完全没戏了。尽可能的在Table的层面来处理吧。
- 后续我们正在考虑在DataStream上构建BoundedStream,给DataStream带来批处理的功能。
网络模型
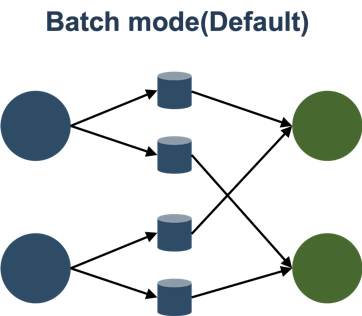
Batch模式就是在中间结果落盘,这个模式和典型的Batch处理是一致的,比如MapReduce/Spark/Tez。
Flink以前的网络模型也分为Batch和Pipeline两种,但是Batch模式只是支持上下游隔断执行,也就是说资源用量可以不用同时满足上下游共同的并发。但是另外一个关键点是Failover没有对接好,1.9和1.10在这方面进行了改进,支持了单点的Failover。
建议在Batch时打开:
jobmanager.execution.failover-strategy = region
为了避免重启过于频繁导致JobMaster太忙了,可以把重启间隔提高:
restart-strategy.fixed-delay.delay = 30 s
Batch模式的好处有:
- 容错好,可以单点恢复
- 调度好,不管多少资源都可以运行
- 性能差,中间数据需要落盘,强烈建议开启压缩
taskmanager.network.blocking-shuffle.compression.enabled = true
Batch模式比较稳,适合传统Batch作业,大作业。

Pipeline模式是Flink的传统模式,它完全和Streaming作业用的是同一套代码,其实社区里Impala和Presto也是类似的模式,纯走网络,需要处理反压,不落盘,它主要的优缺点是:
- 容错差,只能全局重来
- 调度差,你得保证有足够的资源
- 性能好,Pipeline执行,完全复用Stream,复用流控反压等功能。
有条件可以考虑开启Pipeline模式。
调度模型
Flink on Yarn支持两种模式,Session模式和Per job模式,现在已经在调度层次高度统一了。
- Session模式没有最大进程限制,当有Job需要资源时,它就会去Yarn申请新资源,当Session有空闲资源时,它就会给Job复用,所以它的模型和PerJob是基本一样的。
- 唯一的不同只是:Session模式可以跨作业复用进程。
另外,如果想要更好的复用进程,可以考虑加大TaskManager的超时释放:
resourcemanager.taskmanager-timeout = 900000
资源模型
先说说并发:
- 对Source来说:目前Hive的table是根据InputSplit来定需要多少并发的,它之后能Chain起来的Operators自然都是和source相同的并发。
- 对下游网络传输过后的Operators(Tasks)来说:除了一定需要单并发的Task来说,其它Task全部统一并发,由table.exec.resource.default-parallelism统一控制。
我们在Blink内部实现了基于统计信息来推断并发的功能,但是其实以上的策略在大部分场景就够用了。
Manage内存
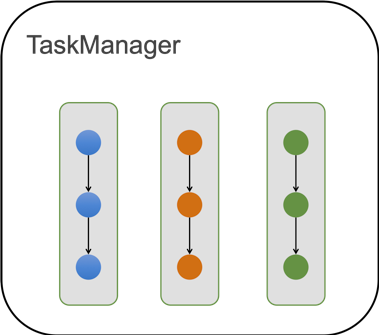
目前一个TaskManager里面含有多个Slot,在Batch作业中,一个Slot里只能运行一个Task (关闭SlotShare)。
对内存来说,单个TM会把Manage内存切分成Slot粒度,如果1个TM中有n个Slot,也就是Task能拿到1/n的manage内存。
我们在1.10做了重大的一个改进就是:Task中chain起来的各个operators按照比例来瓜分内存,所以现在配置的算子内存都是一个比例值,实际拿到的还要根据Slot的内存来瓜分。
这样做的一个重要好处是:
- 不管当前Slot有多少内存,作业能都run起来,这大大提高了开箱即用。
- 不管当前Slot有多少内存,Operators都会把内存瓜分干净,不会存在浪费的可能。
当然,为了运行的效率,我们一般建议单个Slot的manage内存应该大于500MB。
另一个事情,在1.10后,我们去除了OnHeap的manage内存,所以只有off-heap的manage内存。
外部系统集成
Hive
强烈推荐Hive Catalog + Hive,这也是目前批处理最成熟的架构。在1.10中,除了对以前功能的完善以外,其它做了几件事:
- 多版本支持,支持Hive 1.X 2.X 3.X
- 完善了分区的支持,包括分区读,动态/静态分区写,分区统计信息的支持。
- 集成Hive内置函数,可以通过以下方式来load:
a)TableEnvironment.loadModule("hiveModule",new HiveModule("hiveVersion")) - 优化了ORC的性能读,使用向量化的读取方式,但是目前只支持Hive 2+版本,且要求列没有复杂类型。有没有进行过优化差距在5倍量级。
兼容Streaming Connectors
得益于流批统一的架构,目前的流Connectors也能在batch上使用,比如HBase的Lookup和Sink、JDBC的Lookup和Sink、Elasticsearch的Sink,都可以在Batch无缝对接使用起来。
实践
SQL-CLI
在1.10中,SQL-CLI也做了大量的改动,比如把SQL-CLI做了stateful,里面也支持了DDL,还支持了大量的DDL命令,给SQL-CLI暴露了很多TableEnvironment的能力,这让用户可以方便得多。后续,我们也需要对接JDBC的客户端,让用户可以更好的对接外部工具。但是SQL-CLI仍然待继续改进,比如目前仍然只支持Session模式,不支持Per Job模式。
编程方式

老的BatchTableEnv因为绑定了Dataset,而且区分Java和Scala,是不干净的设计方式,所以Blink planner只支持新的TableEnv。
TableEnv注册的source, sink, connector, functions,都是temporary的,重启之后即失效了。如果需要持久化的object,考虑使用HiveCatalog。

可以通过tEnv.sqlQuery来执行DML,这样可以获得一个Table,我们也通过collect来获得小量的数据:

可以通过tEnv.sqlUpdate来执行DDL,但是目前并不支持创建hive的table,只能创建Flink类型的table:

可以通过tEnv.sqlUpdate来执行insert语句,Insert到临时表或者Catalog表中,比如insert到上面创建的临时JDBC表中:

当结果表是Hive表时,可以使用Overwrite语法,也可以使用静态Partition的语法,这需要打开Hive的方言:

结语
目前Flink batch SQL仍然在高速发展中,但是1.10已经是一个可用的版本了,它在功能上、性能上都有很大的提升,后续还有很多有意思的features,等待着大家一起去挖掘。
本文作者:李劲松(之信)
本文为阿里云内容,未经允许不得转载。
Flink Batch SQL 1.10 实践的更多相关文章
- Flink系列之1.10版流式SQL应用
随着Flink 1.10的发布,对SQL的支持也非常强大.Flink 还提供了 MySql, Hive,ES, Kafka等连接器Connector,所以使用起来非常方便. 接下来咱们针对构建流式SQ ...
- 使用flink Table &Sql api来构建批量和流式应用(2)Table API概述
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- SQL Server - 最佳实践 - 参数嗅探问题 转。
文章来自:https://yq.aliyun.com/articles/61767 先说我的问题,最近某个存储过程,暂定名字:sp_a 总是执行超时,sp_a带有一个参数,暂定名为 para1 var ...
- 使用flink Table &Sql api来构建批量和流式应用(1)Table的基本概念
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- 史上最全存储引擎、索引使用及SQL优化的实践
史上最全存储引擎.索引使用及SQL优化的实践 1 MySQL的体系结构概述 2. 存储引擎 2.1 存储引擎概述 2.2 各种存储引擎特性 2.2.1 InnoDB 2.2.2 MyISAM 3. 优 ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
- sql 第 10条 到20条
sql 第 10条 到20条 select * from( select *,ROW_NUMBER () over (order by @@servername) as rownum from tb_ ...
- Red Gate系列之一 SQL Compare 10.4.8.87 Edition 数据库比较工具 完全破解+使用教程
原文:Red Gate系列之一 SQL Compare 10.4.8.87 Edition 数据库比较工具 完全破解+使用教程 Red Gate系列之一 SQL Compare 10.4.8.87 E ...
随机推荐
- 【MM系列】SAP MM模块-配置PO的创建时间
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP MM模块-配置PO的创建时间 ...
- JS图片宽度自适应移动端
$(function(){ $("#d-intro").find("img").each(function () { $(this ...
- Zend Framework MVC的结构
The Zend Framework MVC Architecture 一.概述: In this chapter, we will cover the following topics:1. Zen ...
- ^A '\001' 分隔符
^A 分隔符符号\001,使用组合按键“ctrl+V+A”获得
- C++中的字符串类
1,本文分析 C++ 中的字符串,C 语言中的字符串利用的是 C 语言中的字符数组, 在 C 语言中没有真正意义上的字符串,利用了字符数组表示了字符串,最初设 计 C 语言仅仅是为了开发 Unix ...
- 在centos6.4下安装python3.5
1.安装依赖包 ./configure --prefix=/usr/local/python3.5 --enable-shared make && make install yum g ...
- 02.AutoMapper 之扁平化(Flattening)
https://www.jianshu.com/p/65099590c930 扁平化(Flattening) 对象映射器的常见用法是将一个复杂对象模型扁平化为一个简单模型.例如您有一个以下复杂模型 ...
- webdriver 的使用 java 和python 两个版本
在使用webdriver前要先做下准备,1.下载相应的支持包,可以pom.xml文件引入 2.下载版本对应的浏览器驱动(我这里用的是chromedriver.exe),很多问题都是由于浏览器驱动引起的 ...
- .net 敏捷开发框架7.0.3 旗舰版
联系QQ:1516462411 索取
- Spring基础17——使用注解来配置Bean
1.组件扫描 组件扫描(component scanning):Spring能够从classpath下自动扫描,侦测和实例化具有特定的注解的组件. 特定组件包括: —@Component:基本注解,标 ...