CPU与GPU,我们应该使用哪个?
CPU与GPU,我们应该使用哪个?
CPU与GPU
CPU即中央处理器,GPU即图形处理器。
两者的相同之处:两者都有总线和外界联系,有自己的缓存体系,以及数字和逻辑运算单元
两者的区别之处:在于存在于片内的缓存体系和数字逻辑运算单元的结构差异:CPU虽然有多核,但总数没有超过两位数,每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并辅助有很多加速分支判断甚至更复杂的逻辑判断的硬件;GPU的核数远超CPU,被称为众核(NVIDIA Fermi有512个核)。每个核拥有的缓存大小相对小,数字逻辑运算单元也少而简单(GPU初始时在浮点计算上一直弱于CPU)。从结果上导致CPU擅长处理具有复杂计算步骤和复杂数据依赖的计算任务,如分布式计算,数据压缩,人工智能,物理模拟,以及其他很多很多计算任务等。GPU由于历史原因,是为了视频游戏而产生的(至今其主要驱动力还是不断增长的视频游戏市场),在三维游戏中常常出现的一类操作是对海量数据进行相同的操作,如:对每一个顶点进行同样的坐标变换,对每一个顶点按照同样的光照模型计算颜色值。GPU的众核架构非常适合把同样的指令流并行发送到众核上,采用不同的输入数据执行。在2003-2004年左右,图形学之外的领域专家开始注意到GPU与众不同的计算能力,开始尝试把GPU用于通用计算(即GPGPU)。之后NVIDIA发布了CUDA,AMD和Apple等公司也发布了OpenCL,GPU开始在通用计算领域得到广泛应用,包括:数值分析,海量数据处理(排序,Map-Reduce等),金融分析等等。
简而言之,当程序员为CPU编写程序时,他们倾向于利用复杂的逻辑结构优化算法从而减少计算任务的运行时间,即Latency。当程序员为GPU编写程序时,则利用其处理海量数据的优势,通过提高总的数据吞吐量(Throughput)来掩盖Lantency。目前,CPU和GPU的区别正在逐渐缩小,因为GPU也在处理不规则任务和线程间通信方面有了长足的进步。另外,功耗问题对于GPU比CPU更严重。
以下转载:http://www.cnblogs.com/biglucky/p/4223565.html
CPU与GPU的设计区别
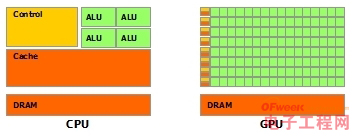
图片来自nVidia CUDA文档。其中绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。而CPU不仅被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分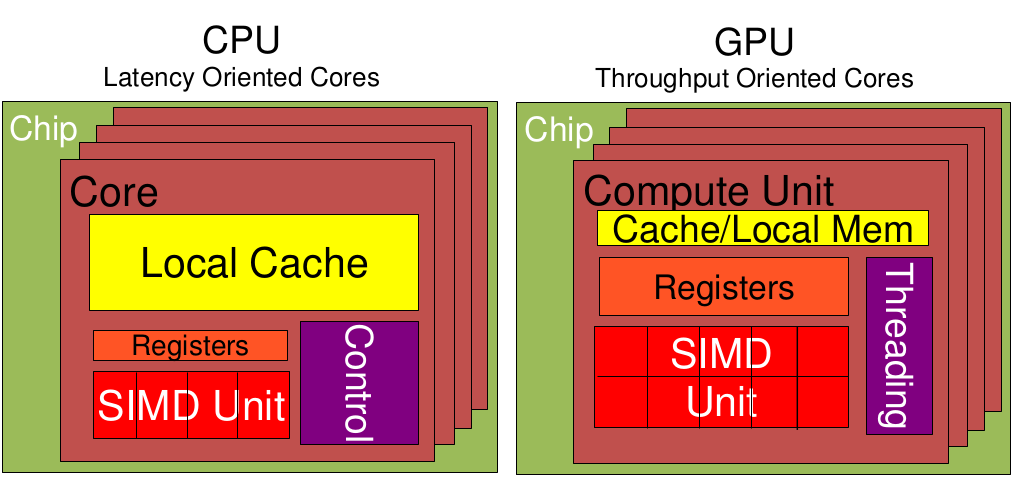
从上图可以看出:
Cache, local memory: CPU > GPU
Threads(线程数): GPU > CPU
Registers: GPU > CPU 多寄存器可以支持非常多的Thread,thread需要用到register,thread数目大,register也必须得跟着很大才行。
SIMD Unit(单指令多数据流,以同步方式,在同一时间内执行同一条指令): GPU > CPU。
CPU 基于低延时的设计:

CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算。
当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期。
CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方).
大的缓存也可以降低延时。保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。
复杂的逻辑控制单元。当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。这些动作需要很多的对比电路单元和转发电路单元。
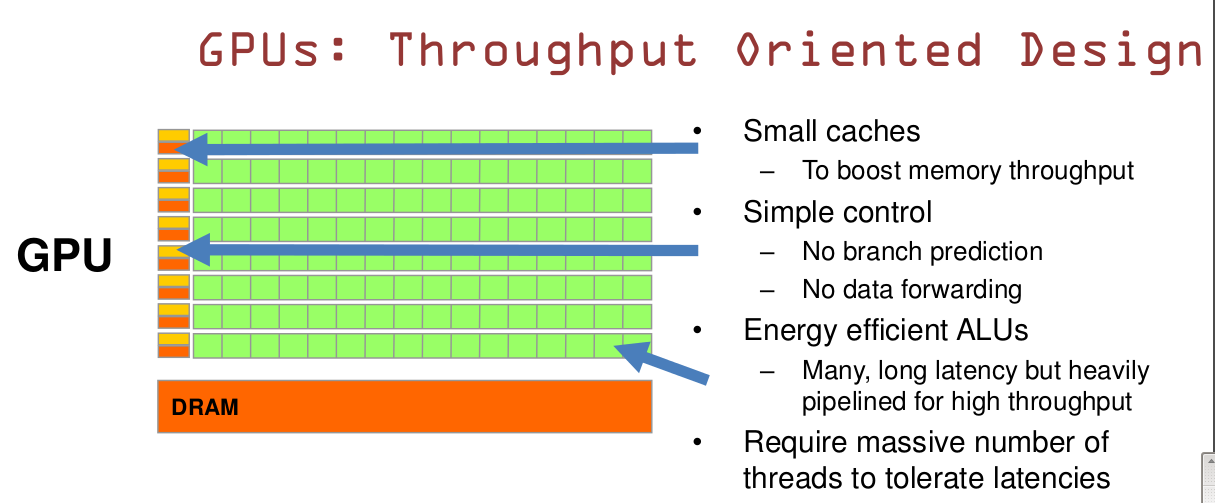
GPU是基于大的吞吐量设计。
GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多的thread. 为啦平衡内存延时的问题,我们可以中充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的Threads.通常来看GPU ALU会有非常重的pipeline就是因为这样。
所以与CPU擅长逻辑控制,串行的运算。和通用类型数据运算不同,GPU擅长的是大规模并发计算,这也正是密码破解等所需要的。所以GPU除了图像处理,也越来越多的参与到计算当中来。
GPU的工作大部分就是这样,计算量大,但没什么技术含量,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已。而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个?GPU就是这样,用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。很多涉及到大量计算的问题基本都有这种特性,比如你说的破解密码,挖矿和很多图形学的计算。这些计算可以分解为多个相同的简单小任务,每个任务就可以分给一个小学生去做。但还有一些任务涉及到“流”的问题。比如你去相亲,双方看着顺眼才能继续发展。总不能你这边还没见面呢,那边找人把证都给领了。这种比较复杂的问题都是CPU来做的。
总而言之,CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别。而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了。GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
什么类型的程序适合在GPU上运行?
(1)计算密集型的程序。所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。
(2)易于并行的程序。GPU其实是一种SIMD(Single Instruction Multiple Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。
总结:CPU是由专为串行任务优化的核心组成,而GPU是数以千计的高效并行核心组成,两者相辅相成。
CPU与GPU,我们应该使用哪个?的更多相关文章
- 浅谈CPU和GPU的区别
导读: CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景.CPU需要很强的通用性来处理各种不同的数据类型,而GPU面对的则是类型高度统一的.相互无依赖的大规模数据 ...
- CPU和GPU性能对比
计算20000次10000点的fft,分别使用CPU和GPU,得 the running time of cpu is : 2.3696s the running time of gpu is : 0 ...
- CPU和GPU实现julia
CPU和GPU实现julia 主要目的是通过对比,学习研究如何编写CUDA程序.julia的算法还是有一定难度的,但不是重点.由于GPU实现了也是做图像识别程序,所以缺省的就是和O ...
- 图像重采样(CPU和GPU)
1 前言 之前在写影像融合算法的时候,免不了要实现将多光谱影像重采样到全色大小.当时为了不影响融合算法整体开发进度,其中重采样功能用的是GDAL开源库中的Warp接口实现的. 后来发现GDAL War ...
- CPU和GPU的区别
个人认为CPU和GPU各有自己的适应领域.CPU(Central Processing Unit)计算核心较少,通常是双核.四核.八核,但是拥有大量的共享缓存.预测.乱序执行等优化,可以做逻辑非常复杂 ...
- CPU和GPU的差别
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt317 首先需要解释CPU和GPU这两个缩写分别代表什么.CPU即中央处理器, ...
- Shader 入门笔记(二) CPU和GPU之间的通信
渲染流水线的起点是CPU,即应用阶段. 1)把数据加载到显存中 2)设置渲染状态,通俗说这些状态定义了场景中的网格是怎样被渲染的. 3)调用DrawCall,一个命令,CPU通知GPU.(这个命令仅仅 ...
- Caffe源码理解2:SyncedMemory CPU和GPU间的数据同步
目录 写在前面 成员变量的含义及作用 构造与析构 内存同步管理 参考 博客:blog.shinelee.me | 博客园 | CSDN 写在前面 在Caffe源码理解1中介绍了Blob类,其中的数据成 ...
- (七) Keras 绘制网络结构和cpu,gpu切换
视频学习来源 https://www.bilibili.com/video/av40787141?from=search&seid=17003307842787199553 笔记 首先安装py ...
- Shader 入门笔记(二) CPU和GPU之间的通信,渲染流水线
渲染流水线 1)应用阶段(CPU处理) 首先,准备好场景数据(摄像机位置,视锥体,模型和光源等) 接着,做粗粒度剔除工作. 最后,设置好每个模型的渲染状态(使用的材质,纹理,shader等) 这一阶段 ...
随机推荐
- Python 写 ACM 题目的一些技巧
目录 输入输出 input() 输入 split() 用于输入 strip() 输入清理 print() 输入 sort 排序 输入输出 input() 输入 Python3 中 input() 函数 ...
- webpack前置知识1(模块化开发)
webpack前置知识1(模块化开发) 新建 模板 小书匠 在开始对模块化开发进行讲解之前,我们需要有这么一个认识,即 在没有过多第三方干扰时,成本低收益高的事物更容易获得推广和信赖. 模块化开发就 ...
- SELECT-OPTIONS对象
1. SELECT-OPTIONS基本语法及定义 SELECT-OPTIONS通常用于参照一数据库字为建立数据输入域,其定义对象命名长度不能超过8位,其产生的屏幕对象最大输入长度为18位,语法如下: ...
- springboot文件上传报错
异常信息: org.springframework.web.multipart.MultipartException: Could not parse multipart servlet reques ...
- RequestContextHolder获取request和response
RequestContextHolder获取request和response 2019年03月16日 15:18:15 whp404 阅读数:21更多 个人分类: Spring 首先需要在web. ...
- 【BASIS系列】SAP Basis系统管理中重置用户缓冲哪些需要注意
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[BASIS系列]SAP Basis系统管理中重 ...
- express中app.use()使用方法
app.use([path,] function [, function…]) 在path上安装中间件,如果path没有被设定,那么默认为”/”. 当为路由设置一个匹配路径后,路由会匹配该路径及该路径 ...
- vue-devtools安装以后,勾选了“允许访问文件网址”之后还是无法使用
勾选了“允许访问文件网址”,还是无法使用: Vue.js is detected on this page. Devtools inspection is not available because ...
- Linux-Maven部署
一.Maven是什么 二.Maven部署 1.环境信息: (1)centos7.3 (2)jdk1.8 (3)maven3.5.3 2.安装jdk (1)下载地址[http://www.oracle. ...
- Maven 中 resources 作用
默认情况下,如果没有指定resources,目前认为自动会将src/main/resources下的.xml文件放到target里头的classes文件夹下的package下的文件夹里.如果设定了re ...