大数据笔记(二)——Apache Hadoop的体系结构
一.分布式存储
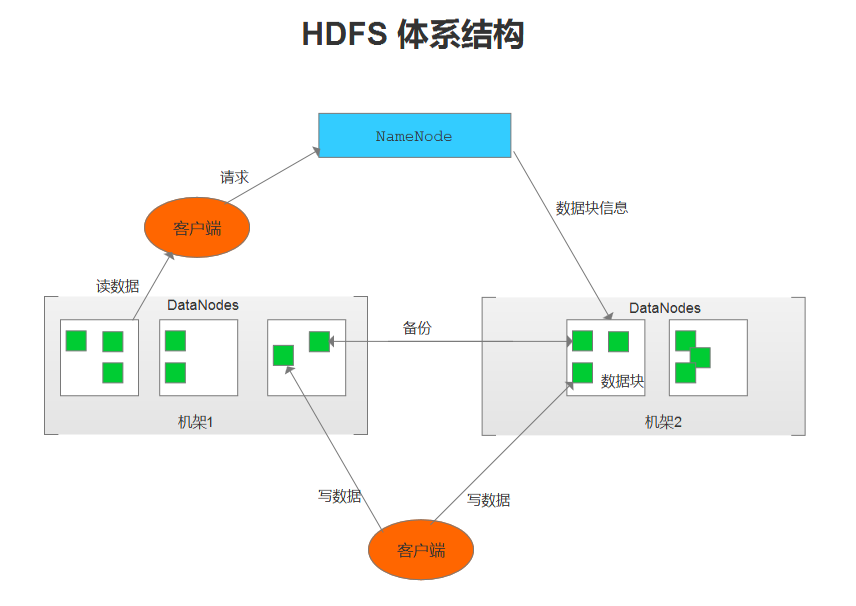
- NameNode(名称节点)
1.维护HDFS文件系统,是HDFS的主节点。
2.接收客户端的请求:上传、下载文件、创建目录等。
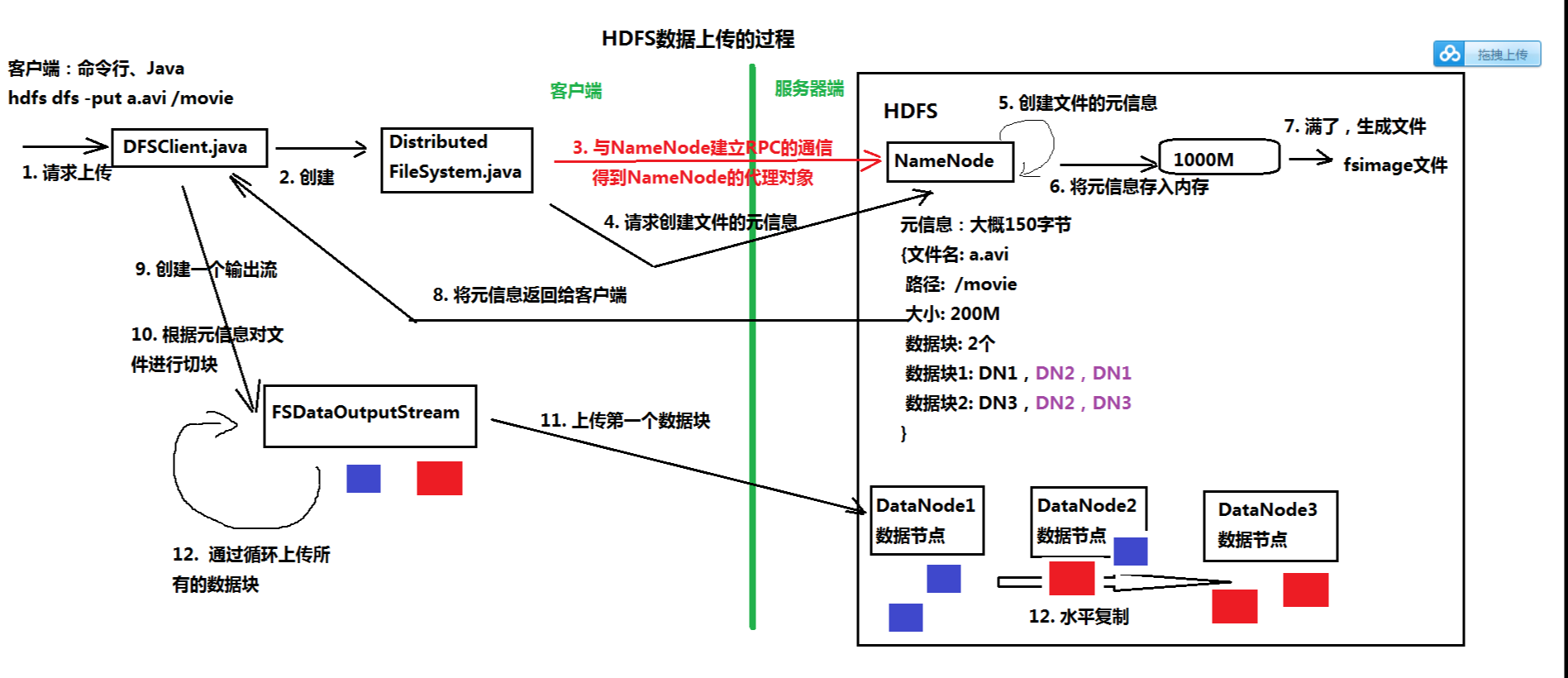
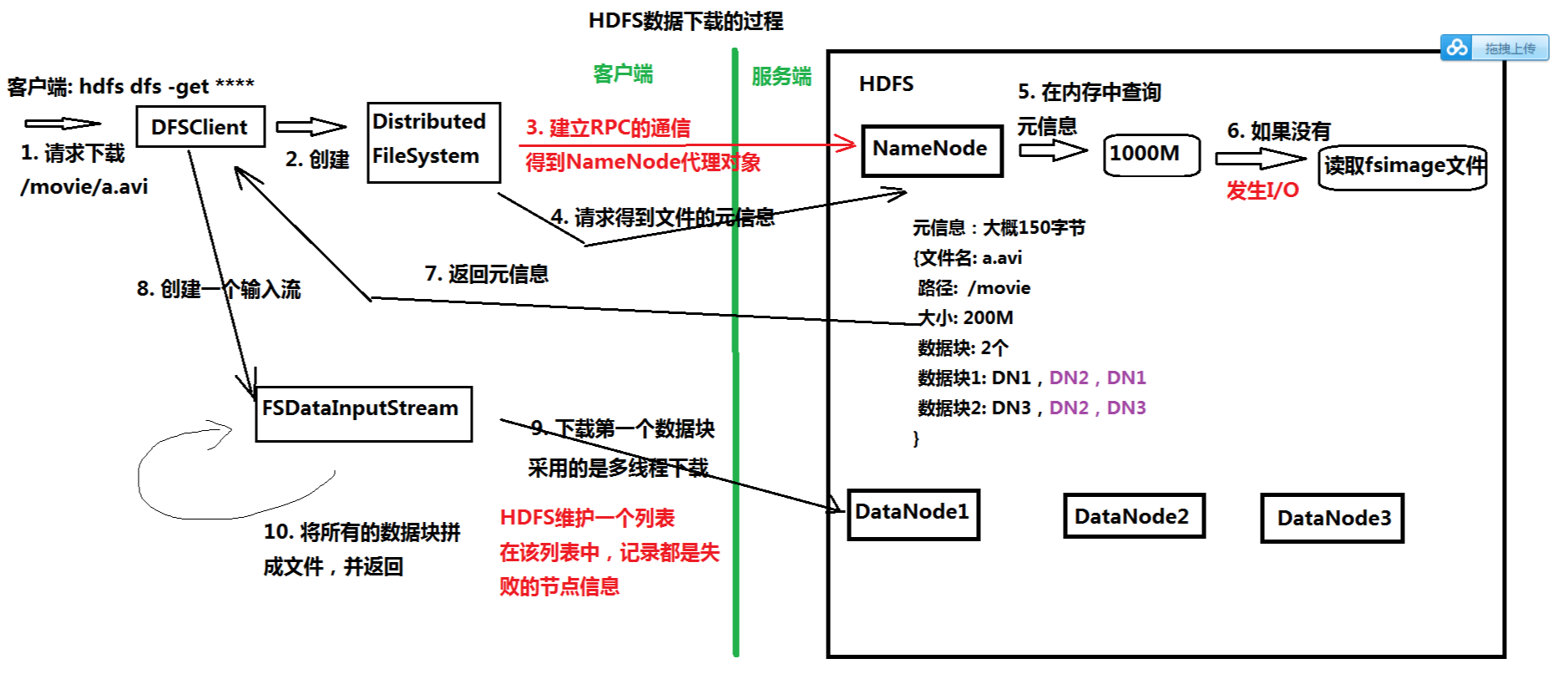
3.记录客户端操作的日志(edits文件),保存了HDFS最新的状态
1)Edits文件保存了自最后一次检查点之后所有针对HDFS文件系统的操作,比如:增加文件、重命名文件、删除目录等
2)保存目录:$HADOOP_HOME/tmp/dfs/name/current
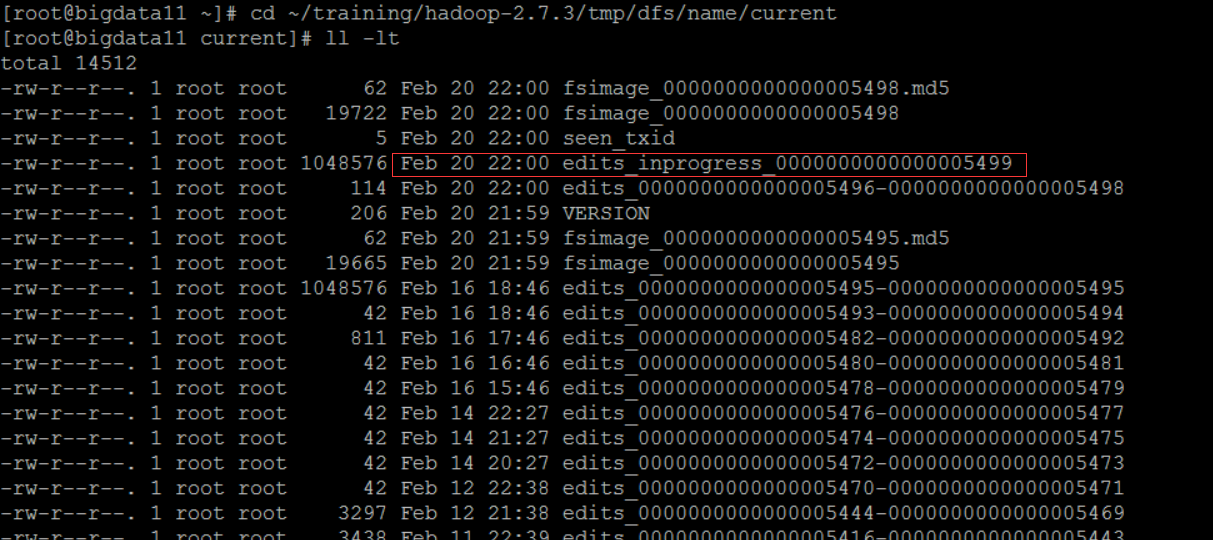
可以使用 hdfs oev -i 命令将日志(二进制)输出为 XML文件
hdfs oev -i edits_inprogress_0000000000000005499 -o ~/temp/log.xml
4.维护文件元信息,将内存中不常用的文件元信息保存在硬盘上(fsimage文件)
1)fsimage是HDFS文件系统存于硬盘中的元数据检查点,里面记录了自最后一次检查点之前HDFS文件系统中所有目录和文件的序列化信息
2)保存目录:edits
3)可以使用 hdfs oev -i 命令将日志(二进制)输出为 XML文件
- DataNode(数据节点)
1.以数据块为单位,保存数据
1)Hadoop1.0的数据块大小:64M
2)Hadoop2.0的数据库大小:128M
2.在全分布模式下,至少两个DataNode节点
3.数据保存的目录:由 hadoop.tmp.dir 参数指定
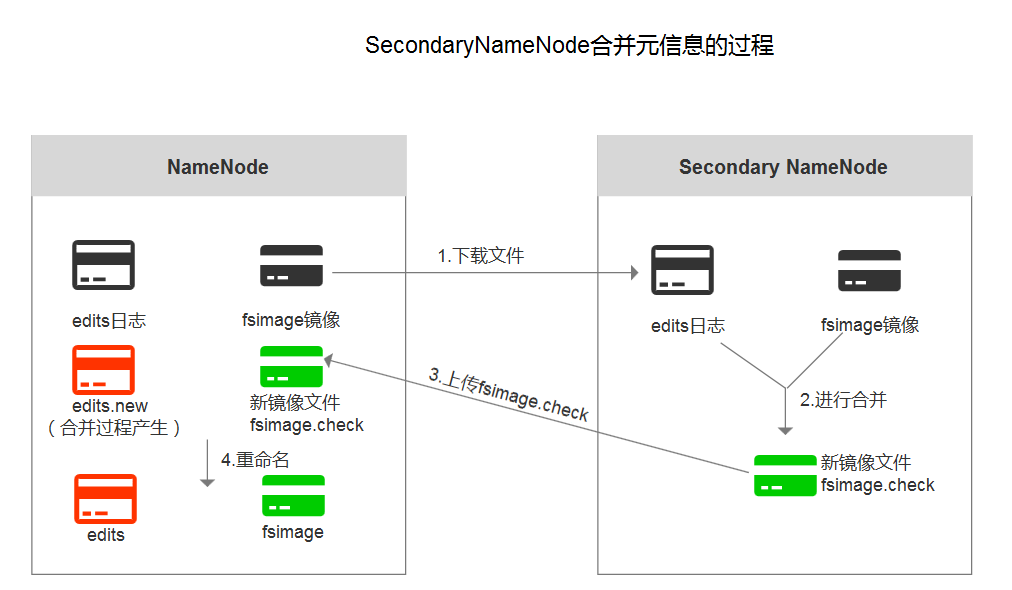
- Secondary NameNode(第二名称节点)
1.主要作用:合并日志
2.合并时机:HDFS发出检查点的时候
3.日志合并过程:
- HDFS存在的问题
1)NameNode单点故障问题
解决方案:Hadoop2.0中,使用Zookeeper实现NameNode的HA功能
2)NameNode压力过大,且内存受限,影响系统扩展性
解决方案:Hadoop2.0中,使用NameNode联盟实现水平扩展
二.YARN:分布式计算(MapReduce)
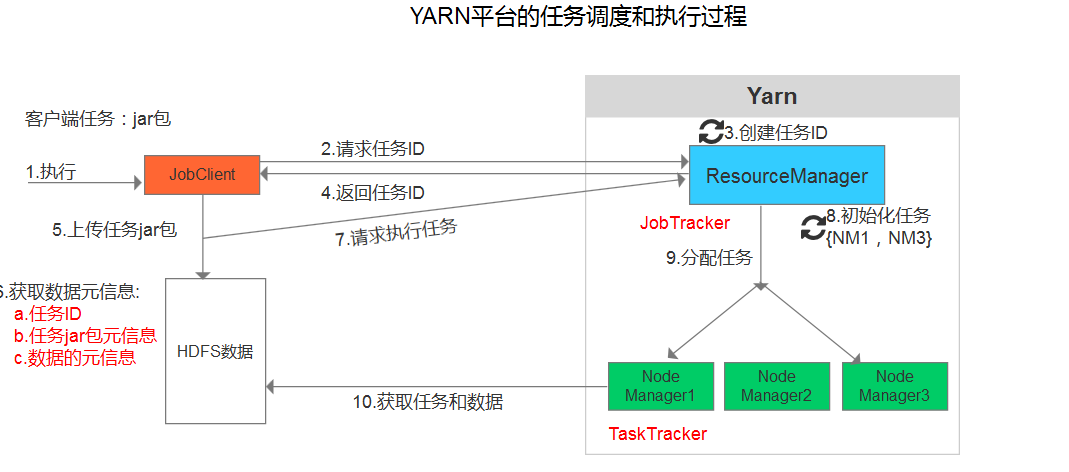
- ResourceManager(资源管理器)
1.接收客户端的请求,执行任务
2.分配资源
3.分配任务
- NodeManager(节点管理器:运行任务 MapReduce)
从 DataNode上获取数据,执行任务
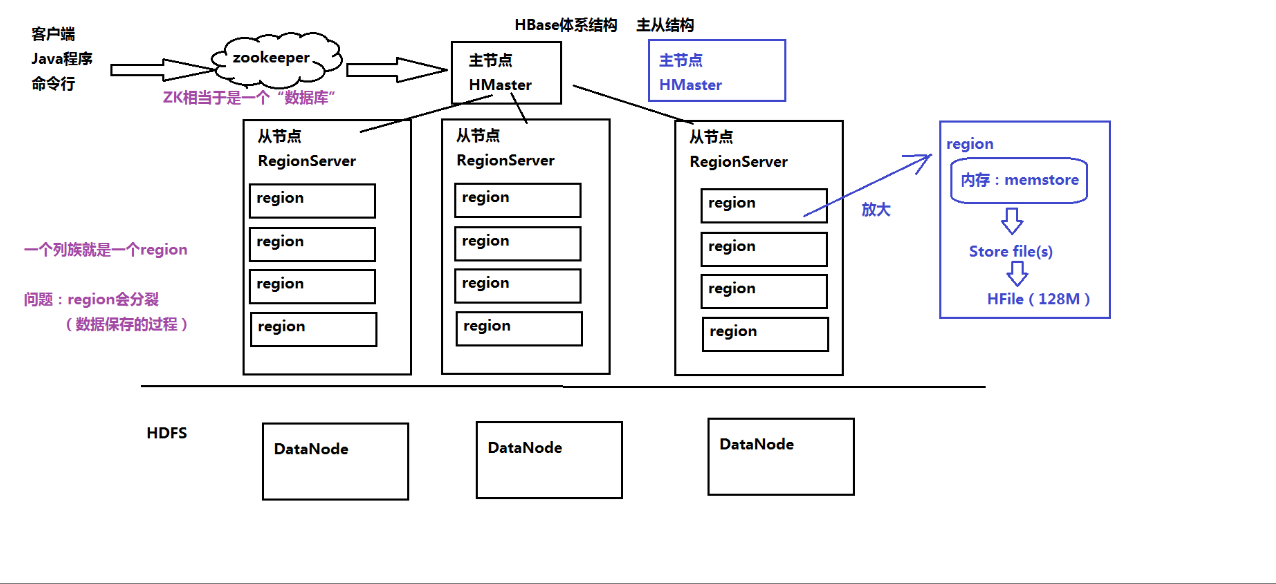
三.HBase的体系结构
大数据笔记(二)——Apache Hadoop的体系结构的更多相关文章
- 大数据笔记13:Hadoop安装之Hadoop的配置安装
1.准备Linux环境 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip ...
- 大数据软件安装之Hadoop(Apache)(数据存储及计算)
大数据软件安装之Hadoop(Apache)(数据存储及计算) 一.生产环境准备 1.修改主机名 vim /etc/sysconfig/network 2.修改静态ip vim /etc/udev/r ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 玩转大数据系列之Apache Pig高级技能之函数编程(六)
原创不易,转载请务必注明,原创地址,谢谢配合! http://qindongliang.iteye.com/ Pig系列的学习文档,希望对大家有用,感谢关注散仙! Apache Pig的前世今生 Ap ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- 决战大数据之二:CentOS 7 最新JDK 8安装
决战大数据之二:CentOS 7 最新JDK 8安装 [TOC] 修改hostname # hostnamectl set-hostname node1 --static # reboot now 重 ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
随机推荐
- [DS+Algo] 010 二叉树的遍历
二叉树遍历 深度优先 一般用递归 一些名词 遍历方式 英文 先序 Preorder 中序 Inorder 后序 Postorder 广度优先 一般用队列 Python 代码示例 class Node( ...
- CentOS7搭建NTP服务器及客户端同步时间
一.服务器配置 1.查看服务器.客户端操作系统版本 [root@hadoop101 ~]# cat /etc/redhat-release CentOS Linux release (Core) 2. ...
- 牛客练习赛51 C 勾股定理
链接:https://ac.nowcoder.com/acm/contest/1083/C 题目描述 给出直角三角形其中一条边的长度n,你的任务是构造剩下的两条边,使这三条边能构成一个直角三角形. 输 ...
- python学习第五十二天logging模块的使用
很多程序都有记录日志的需求,并且日志包含的信息即有正常的程序访问日志,还可能有错误,警告等信息输出,python的 logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,loggin ...
- css重置的各种版本总结
个人手机端常用到的: @charset "utf-8"; body, h1, h2, h3, h4, h5, h6, hr, p, blockquote, dl, dt, dd, ...
- Consul服务发现在windows下简单使用
目录 基本介绍: 服务连接: 客户端: 系列章节: 回到顶部 基本介绍: 安装: 下载地址:https://www.consul.io/downloads.html 运行: consul agent ...
- git设置Eclipse中忽略的文件
GitHub 官网样例文件https://github.com/github/gitignorehttps://github.com/github/gitignore/blob/master/Java ...
- nmbd - 向客户端提供构造在IP之上的NetBIOS名字服务的NetBIOS名字服务器
总览 SYNOPSIS nmbd [-D] [-F] [-S] [-a] [-i] [-o] [-h] [-V][-d <debug level>] [-H <lmhosts fil ...
- C# List<Object>值拷贝
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Run ...
- 在C语言中连续使用scanf()函数出现的问题
#include<stdio.h> int main() { ],*c; printf("input string:\n"); scanf("%c" ...