02:django model数据库操作
Django其他篇
目录:
- 1.1 Django中使用MySQL
- 1.2 创建表
- 1.3 Django一对多表结构操作
- 1.4 Django多对多表结构操作
- 1.5 一大波Model操作
- 1.6 Model性能相关操作:select_related、prefetch_related
- 1.7 F()和Q()查询语句
- 1.8 aggregate和annotate聚合函数 : 求平均值、最大值、最小值等
- 1.9 Trunc函数处理日期格式数据
- 1.10 Django其他查询语句
1.1 Django中使用MySQL返回顶部
1、先写类:在 app01/models.py中写类
from django.db import models class Student(models.Model):
name = models.CharField(max_length=64,verbose_name='姓名')
age = models.IntegerField(verbose_name='年纪') class Meta:
db_table = 'student'
verbose_name_plural = '学生表' def __str__(self):
return self.name
app01/models.py
2、在Django项目中使用MySQL
1. 创建管理员密码,与数据库
1. mysqladmin -uroot password 123456 # 用户名:root 密码:123456
2. mysql -uroot -p # dos下登录MySQL
3. create database MyCRM charset utf8; # 创建数据库MyCRM
4. drop database MyCRM; # 如果需要也可以把数据库删除
5. show databases; # 查看现有数据库
2. 配置使用MySQL(修改settings.py配置文件)
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'MyCRM', # 指定数据库名称:MyCRM
'USER': 'root',
'PASSWORD': '',
'HOST': '127.0.0.1',
'PORT': '',
}
}
'''注释默认数据库配置'''
# DATABASES = {
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
# }
# }
配置使用MySQL
3. 主动修改为pymysql
1. Django默认使用MySQLdb模块链接MySQL,但在python3中还没有MySQLdb
2. 主动修改为pymysql,在project同名文件夹下的__init__文件中添加如下代码即可
import pymysql
pymysql.install_as_MySQLdb()
主动修改为pymysql
4. 创建表 (记得注册APP)
python manage.py makemigrations
python manage.py migrate --fake
3、使用django admin
1. 创建django admin管理员账号
python manage.py createsuperuser
2、配置django admin显示
from django.contrib import admin
from app01 import models class StudentAdmin(admin.ModelAdmin):
list_display = ('name','age',)
search_fields = ('name','age',) admin.site.register(models.Student, StudentAdmin)
app01/admin.py
1.2 创建表返回顶部
1、创建表基本语法
from django.db import models class Student(models.Model):
name = models.CharField(max_length=64,verbose_name='姓名')
age = models.IntegerField(verbose_name='年纪') class Meta:
db_table = 'student'
verbose_name_plural = '学生表' def __str__(self):
return self.name
app01/models.py
2、元信息Meta
from django.db import models class Student(models.Model):
name = models.CharField(max_length=64,verbose_name='姓名')
age = models.IntegerField(verbose_name='年纪') class Meta:
# 1 数据库中生成的表名称 默认 app名称 + 下划线 + 类名
db_table = "student" # 自己指定创建的表名 # 2 verbose_name加s
verbose_name_plural = '学生表' # 若果这个字段也是user那么4中表名才显示user # 3 联合唯一索引
unique_together = (("name", "password"),) # 4 联合索引 (缺点是最左前缀,写SQL语句基于password时不能命中索引,查找慢)
# 如:select * from tb where password = ‘xx’ 就无法命中索引
index_together = [
("name", "password"),
] def __str__(self):
return self.name
元信息Meta
3、字段
from django.db import models class UserGroup(models.Model):
uid = models.AutoField(primary_key=True) name = models.CharField(max_length=32,null=True, blank=True)
email = models.EmailField(max_length=32)
text = models.TextField() ctime = models.DateTimeField(auto_now_add=True) # 只有添加时才会更新时间
uptime = models.DateTimeField(auto_now=True) # 只要修改就会更新时间 ip1 = models.IPAddressField() # 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制
ip2 = models.GenericIPAddressField() # 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6 active = models.BooleanField(default=True) data01 = models.DateTimeField() # 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ
data02 = models.DateField() # 日期格式 YYYY-MM-DD
data03 = models.TimeField() # 时间格式 HH:MM[:ss[.uuuuuu]] age = models.PositiveIntegerField() # 正小整数 0 ~ 32767
balance = models.SmallIntegerField() # 小整数 -32768 ~ 32767
money = models.PositiveIntegerField() # 正整数 0 ~ 2147483647
bignum = models.BigIntegerField() # 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 user_type_choices = (
(1, "超级用户"),
(2, "普通用户"),
(3, "普普通用户"),
)
user_type_id = models.IntegerField(choices=user_type_choices, default=1)
常用字段
URLField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证 URL SlugField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) CommaSeparatedIntegerField(CharField)
- 字符串类型,格式必须为逗号分割的数字 UUIDField(Field)
- 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 FilePathField(Field)
- 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
- 参数:
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹 FileField(Field)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage ImageField(FileField)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串) DurationField(Field)
- 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 FloatField(Field)
- 浮点型 DecimalField(Field)
- 10进制小数
- 参数:
max_digits,小数总长度
decimal_places,小数位长度 BinaryField(Field)
- 二进制类型
不常用字段
4、参数
null 数据库中字段是否可以为空
default 数据库中字段的默认值
primary_key 数据库中字段是否为主键
db_index 数据库中字段是否可以建立索引
unique 数据库中字段是否可以建立唯一索引
verbose_name Admin中显示的字段名称
blank Admin中是否允许用户输入为空
editable Admin中是否可以编辑
help_text Admin中该字段的提示信息
error_messages 自定义错误信息(字典类型),从而定制想要显示的错误信息;
字典健:null, blank, invalid, invalid_choice, unique, and unique_for_date
如:{'null': "不能为空.", 'invalid': '格式错误'} db_column 数据库中字段的列名
db_tablespace unique_for_date 数据库中字段【日期】部分是否可以建立唯一索引
unique_for_month 数据库中字段【月】部分是否可以建立唯一索引
unique_for_year 数据库中字段【年】部分是否可以建立唯一索引 choices Admin中显示选择框的内容,用不变动的数据放在内存中从而避免跨表操作
如:gf = models.IntegerField(choices=[(0, '何穗'),(1, '大表姐'),],default=1) validators 自定义错误验证(列表类型),从而定制想要的验证规则
from django.core.validators import RegexValidator
from django.core.validators import EmailValidator,URLValidator,DecimalValidator,\
MaxLengthValidator,MinLengthValidator,MaxValueValidator,MinValueValidator
如:
test = models.CharField(
max_length=32,
error_messages={
'c1': '优先错信息1',
'c2': '优先错信息2',
'c3': '优先错信息3',
},
validators=[
RegexValidator(regex='root_\d+', message='错误了', code='c1'),
RegexValidator(regex='root_112233\d+', message='又错误了', code='c2'),
EmailValidator(message='又错误了', code='c3'), ]
)
参数
1.3 Django一对多表结构操作返回顶部
1、一对多基本增删改查
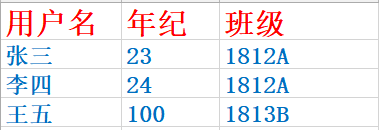
from django.db import models class Student(models.Model):
name = models.CharField(max_length=64,verbose_name='姓名')
age = models.IntegerField(verbose_name='年纪')
clsname = models.ForeignKey(to='ClassName', to_field='id',on_delete=models.CASCADE) class Meta:
db_table = 'student'
verbose_name_plural = '学生表' def __str__(self):
return self.name class ClassName(models.Model):
clsname = models.CharField(max_length=64, verbose_name='班级名称') class Meta:
db_table = 'classname'
verbose_name_plural = '班级表' def __str__(self):
return self.clsname
app01/models.py
from django.shortcuts import render,HttpResponse
from app01 import models def orm(request):
# 1 创建
# 创建数据方法一
models.Student.objects.create(name='root', age=2, clsname_id=1)
# 创建数据方法二
obj = models.Student(name='root2', age=2, clsname_id=1)
obj.save()
# 创建数据库方法三(传入字典必须在字典前加两个星号)
dic = {'name': 'root3', 'age': 2, 'clsname_id': 1}
models.Student.objects.create(**dic) # 2 删除
# models.UserInfo.objects.all().delete() # 删除所有
models.Student.objects.filter(name='root').delete() # 删除指定 # 3 更新
models.Student.objects.all().update(age=100) # 将所有用户的年纪修改成 100
models.Student.objects.filter(name='root2').update(age=99) # 将root2年纪修改为 99 # 4.1 正向查找
print( models.Student.objects.get(name='zhangsan').clsname.clsname ) # 查找学生zhangsan所在班级
print( models.Student.objects.filter(clsname__clsname='1812A') ) # 查询1812A班级所有学生 # 4.2 反向查找 ClassNameObj.userinfo_set.all() 表名_set.all()
print( models.ClassName.objects.get(clsname='1812A').student_set.all() ) # 查询1812A班级所有学生 return HttpResponse('orm')
app01/views.py
from django.contrib import admin
from django.urls import path, re_path
from app01 import views urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'orm/$', views.orm, name='orm')
]
urls.py
2、一对多更多查询操作
from django.db import models class UserType(models.Model):
user_type_name = models.CharField(max_length=32)
def __str__(self):
return self.user_type_name #只有加上这个,Django admin才会显示表名 class User(models.Model):
username = models.CharField(max_length=32)
pwd = models.CharField(max_length=64)
ut = models.ForeignKey(
to='UserType',
to_field='id', # 1、反向操作时,使用的连接前缀,用于替换【表名】
# 如: models.UserGroup.objects.filter(a__字段名=1).values('a__字段名')
related_query_name='a', #2、反向操作时,使用的字段名,用于代替 【表名_set】 如: obj.b_set.all()
# 使用时查找报错
# related_name='b',
)
/app01/models.py创建一对多表
from django.shortcuts import HttpResponse
from app01 import models def orm(request):
# 1 正向查找
#1.1 正向查找user表用户名
print(models.User.objects.get(username='zhangsan').username) # zhangsan #1.2 正向跨表查找用户类型
print(models.User.objects.get(username='zhangsan').ut.user_type_name) # student #1.3 双下划线正向跨表正向查找
print( models.User.objects.all().values('ut__user_type_name','username') ) # 2 反向查找
# 2.1:【表名_set】,反向查找user表中用户类型为student 的所有用户
print( models.UserType.objects.get(user_type_name='student').user_set.all() ) # [<User: lisi>, <User: wangwu>] # 2.2:【a__字段名】反向查找user表中张三在UserType表中的类型:([<UserType: teacher>])
print( models.UserType.objects.filter(a__username='zhangsan') ) # student
# 这里的a是user表的ForeignKey字段的参数:related_query_name='a' # 2.3: 双下划线跨表反向查找
print( models.UserType.objects.all().values('a__username', 'user_type_name') ) # 3 自动创建User表和UserType表中的数据
'''
username = [{'username':'zhangsan','pwd':'123','ut_id':'1'},
{'username':'lisi','pwd':'123','ut_id':'1'},
{'username':'wangwu','pwd':'123','ut_id':'1'},] user_type = [{'user_type_name':'student'},{'user_type_name':'teacher'},] for type_dic in user_type:
models.UserType.objects.create(**type_dic) for user_dic in username:
models.User.objects.create(**user_dic)
'''
return HttpResponse('orm')
/app01/views.py一对多中正向反向查找
3、一对多使用values和values_list结合双下划线跨表查询
from django.shortcuts import HttpResponse
from app01 import models def orm(request):
# 第一种:values-----获取的内部是字典 拿固定列数
# 1.1 正向查找: 使用ForeignKey字段名ut结合双下划线查询
models.User.objects.filter(username='zhangsan').values('username', 'ut__user_type_name') # 1.2 向查找: 使用ForeignKey的related_query_name='a',的字段
models.UserType.objects.all().values('user_type_name', 'a__username') # 第二种:values_list-----获取的是元组 拿固定列数
# 1.1 正向查找: 使用ForeignKey字段名ut结合双下划线查询
stus = models.User.objects.filter(username='zhangsan').values_list('username', 'ut__user_type_name') # 1.2 反向查找: 使用ForeignKey的related_query_name='a',的字段
utype = models.UserType.objects.all().values_list('user_type_name', 'a__username') # 3 自动创建User表和UserType表中的数据
'''
username = [{'username':'zhangsan','pwd':'123','ut_id':'1'},
{'username':'lisi','pwd':'123','ut_id':'1'},
{'username':'wangwu','pwd':'123','ut_id':'1'},] user_type = [{'user_type_name':'student'},{'user_type_name':'teacher'},] for type_dic in user_type:
models.UserType.objects.create(**type_dic) for user_dic in username:
models.User.objects.create(**user_dic)
''' return HttpResponse('orm')
一对多使用values和values_list结合双下划线跨表查询
4、一对多ForeignKey可选参数
1、to, # 要进行关联的表名
2、to_field=None, # 要关联的表中的字段名称
3、on_delete=None, # 当删除关联表中的数据时,当前表与其关联的行的行为
- models.CASCADE # ,删除关联数据,与之关联也删除
- models.DO_NOTHING # ,删除关联数据,引发错误IntegrityError
- models.PROTECT # ,删除关联数据,引发错误ProtectedError
- models.SET_NULL # ,删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)
- models.SET_DEFAULT # ,删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)
- models.SET # ,删除关联数据,
4、related_name=None, # 反向操作时,使用的字段名,用于代替 【表名_set】 如: obj.表名_set.all()
# 在做自关联时必须指定此字段,防止查找冲突
5、delated_query_name=None, # 反向操作时,使用的连接前缀,用于替换【表名】
# 如:models.UserGroup.objects.filter(表名__字段名=1).values('表名__字段名')
6、limit_choices_to=None, # 在Admin或ModelForm中显示关联数据时,提供的条件:
- limit_choices_to={'nid__gt': 5}
- limit_choices_to=lambda : {'nid__gt': 5}
7、db_constraint=True # 是否在数据库中创建外键约束
8、parent_link=False # 在Admin中是否显示关联数据
一对多ForeignKey可选参数
1.4 Django多对多表结构操作返回顶部
1、创建并操作多对多表
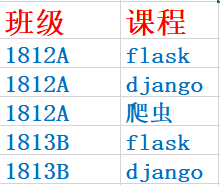
1. 第一种: 自己不创建第三张关系表,有m2m字段: 根据queryset对象增删改查(推荐)
from django.db import models class Student(models.Model):
name = models.CharField(max_length=64,verbose_name='姓名')
age = models.IntegerField(verbose_name='年纪')
clsname = models.ForeignKey(to='ClassName', to_field='id',on_delete=models.CASCADE) class Meta:
db_table = 'student'
verbose_name_plural = '学生表' def __str__(self):
return self.name class ClassName(models.Model):
clsname = models.CharField(max_length=64, verbose_name='班级名称')
lsname = models.ManyToManyField(to='Lesson', related_query_name='cls') class Meta:
db_table = 'classname'
verbose_name_plural = '班级表' def __str__(self):
return self.clsname class Lesson(models.Model):
name = models.CharField(max_length=64, verbose_name='课程名称') class Meta:
db_table = 'lesson'
verbose_name_plural = '课程表' def __str__(self):
return self.name
第一种:models.py 创建多对多表
from django.shortcuts import render,HttpResponse
from app01 import models def orm(request):
class_obj = models.ClassName.objects.get(clsname='1812A')
class_objs = models.ClassName.objects.all() lesson_obj = models.Lesson.objects.get(name='django')
lesson_objs = models.Lesson.objects.all() # 1.1 添加: 正向
class_obj.lsname.add(lesson_obj)
class_obj.lsname.add(*lesson_objs)
# 1.2 删除:正向
class_obj.lsname.remove(lesson_obj)
class_obj.lsname.remove(*lesson_objs) # 2.1 添加: 反向
lesson_obj.classname_set.add(class_obj)
lesson_obj.classname_set.add(*class_objs)
# 2.2 删除:反向
lesson_obj.classname_set.remove(class_obj)
lesson_obj.classname_set.remove(*class_objs) # 3.1 查找:正向
print(class_obj.lsname.all()) # 查找1812A 班级中所有课程
# 3.2 查找:反向
print(lesson_obj.classname_set.all()) # 查找那些班级有django课程
return HttpResponse('orm')
第一种:views.py 根据queryset对象增删改查
from django.contrib import admin
from app01 import models class StudentAdmin(admin.ModelAdmin):
list_display = ('id','name','age',)
search_fields = ('name','age',) class ClassNameAdmin(admin.ModelAdmin):
list_display = ('clsname',)
search_fields = ('clsname',) class LessonAdmin(admin.ModelAdmin):
list_display = ('name',)
search_fields = ('name',) admin.site.register(models.Student, StudentAdmin)
admin.site.register(models.ClassName, ClassNameAdmin)
admin.site.register(models.Lesson, LessonAdmin)
app01/admin.py
2. 第二种: 自己创建第三张关系表,无 m2m 字段,自己链表查询
from django.db import models #表1:主机表
class Host(models.Model):
nid = models.AutoField(primary_key=True)
hostname = models.CharField(max_length=32,db_index=True) #表2:应用表
class Application(models.Model):
name = models.CharField(max_length=32) #表3:自定义第三张关联表
class HostToApp(models.Model):
hobj = models.ForeignKey(to="Host",to_field="nid")
aobj = models.ForeignKey(to='Application',to_field='id') # 向第三张表插入数据,建立多对多外键关联
HostToApp.objects.create(hobj_id=1,aobj_id=2)
第二种: 有第三张表,无m2m字段 models.py
3. 第三种: 自己不创建第三张关系表,有m2m字段: 根据数字id增删改查
from django.db import models class Host(models.Model):
hostname = models.CharField(max_length=32,db_index=True) class Group(models.Model):
group_name = models.CharField(max_length=32)
m2m = models.ManyToManyField("Host")
第三种: models.py创建多对多表
from django.shortcuts import HttpResponse
from app01 import models def orm(request):
# 使用间接方法对第三张表操作
obj = models.Group.objects.get(id=1) # 1、添加
obj.m2m.add(1) # 在第三张表中增加一个条目(1,1)
obj.m2m.add(2, 3) # 在第三张表中增加条目(1,2)(1,3)两条关系
obj.m2m.add(*[1,3]) # 在第三张表中增加条目(1,2)(1,3)两条关系 # 2、删除
obj.m2m.remove(1) # 删除第三张表中的(1,1)条目
obj.m2m.remove(2, 3) # 删除第三张表中的(1,2)(1,3)条目
obj.m2m.remove(*[1, 2, 3]) # 删除第三张表中的(1,1)(1,2)(1,3)条目 # 3、清空
obj.m2m.clear() # 删除第三张表中application条目等于1的所有条目 # 4 更新
obj.m2m.set([1, 2,]) # 第三张表中会删除所有条目,然后创建(1,1)(1,2)条目 # 5 查找
print( obj.m2m.all() ) # 等价于 models.UserInfo.objects.all() # 6 反向查找: 双下划线
hosts = models.Group.objects.filter(m2m__id=1) # 在Host表中id=1的主机同时属于那些组 # 自动创建Host表和Group表中的数据
'''
hostname = [{'hostname':'zhangsan'},
{'hostname':'lisi'},
{'hostname':'wangwu'},]
group_name = [{'group_name':'DBA'},{'group_name':'public'},] for h in hostname:
models.Host.objects.create(**h)
for u in group_name:
models.Group.objects.create(**u)
''' return HttpResponse('orm')
第三种:views.py 根据id增删改查
2、多对多使用values和values_list结合双下划线跨表查询
from django.shortcuts import HttpResponse
from app01 import models def orm(request):
# 第一种:values-----获取的内部是字典,拿固定列数
# 1.1 正向查找: 使用ManyToManyField字段名user_info结合双下划线查询
models.UserGroup.objects.filter(group_name='group_python').values('group_name', 'user_info__username') # 1.2 反向查找: 使用ManyToManyField的related_query_name='m2m',的字段
models.UserInfo.objects.filter(username='zhangsan').values('username', 'm2m__group_name') # 第二种:values_list-----获取的是元组 拿固定列数
# 2.1 正向查找: 使用ManyToManyField字段名user_info结合双下划线查询
models.UserGroup.objects.filter(group_name='group_python').values_list('group_name', 'user_info__username') # 2.2 反向查找: 使用ManyToManyField的related_query_name='m2m',的字段
lesson = models.UserInfo.objects.filter(username='zhangsan').values_list('username', 'm2m__group_name') # 自动创建UserInfo表和UserGroup表中的数据
'''
# user_info_obj = models.UserInfo.objects.get(username='lisi')
# user_info_objs = models.UserInfo.objects.all()
#
# group_obj = models.UserGroup.objects.get(group_name='group_python')
# group_objs = models.UserGroup.objects.all()
#
# group_obj.user_info.add(*user_info_objs)
# user_info_obj.usergroup_set.add(*group_objs) user_list = [{'username':'zhangsan'},
{'username':'lisi'},
{'username':'wangwu'},]
group_list = [{'group_name':'group_python'},
{'group_name':'group_linux'},
{'group_name':'group_mysql'},] for c in user_list:
models.UserInfo.objects.create(**c) for l in group_list:
models.UserGroup.objects.create(**l)
''' return HttpResponse('orm')
多对多使用values和values_list结合双下划线跨表查询
3、创建m2m多对多时ManyToManyField可以添加的参数
1、to, # 要进行关联的表名
2、related_name=None, # 反向操作时,使用的字段名,用于代替 【表名_set】如: obj.表名_set.all()
3、related_query_name=None, # 反向操作时,使用的连接前缀,用于替换【表名】
# 如: models.UserGroup.objects.filter(表名__字段名=1).values('表名__字段名')
4、limit_choices_to=None, # 在Admin或ModelForm中显示关联数据时,提供的条件:
# - limit_choices_to={'nid__gt': 5}
5、symmetrical=None, # 用于多对多自关联,symmetrical用于指定内部是否创建反向操作字段
6、through=None, # 自定义第三张表时,使用字段用于指定关系表
7、through_fields=None, # 自定义第三张表时,使用字段用于指定关系表中那些字段做多对多关系表
8、db_constraint=True, # 是否在数据库中创建外键约束
db_table=None, # 默认创建第三张表时,数据库中表的名称
创建m2m多对多时ManyToManyField可以添加的参数
1.5 一大波Model操作返回顶部
from django.shortcuts import HttpResponse
from app01 import models def orm(request):
# 1 创建
# 创建数据方法一
models.UserInfo.objects.create(username='root', password='')
# 创建数据方法二
obj = models.UserInfo(username='alex', password='')
obj.save()
# 创建数据库方法三(传入字典必须在字典前加两个星号)
dic = {'username': 'eric', 'password': ''}
models.UserInfo.objects.create(**dic) # 2 查
result = models.UserInfo.objects.all() # 查找所有条目
result = models.UserInfo.objects.filter(username='alex', password='')
for row in result:
print(row.id, row.username, row.password) # 3 删除
models.UserInfo.objects.all().delete() # 删除所有
models.UserInfo.objects.filter(username='alex').delete() # 删除指定 # 4 更新
models.UserInfo.objects.all().update(password='')
models.UserInfo.objects.filter(id=4).update(password='') # 5 获取个数
models.UserInfo.objects.filter(name='seven').count() # 6 执行原生SQL
# 6.1 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo') # 6.2 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid from 其他表') # 6.3 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default") return HttpResponse('orm')
基本操作
1、大于,小于
# models.Tb1.objects.filter(id__gt=1) # 获取id大于1的值
# models.Tb1.objects.filter(id__gte=1) # 获取id大于等于1的值
# models.Tb1.objects.filter(id__lt=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lte=10) # 获取id小于10的值
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
2、in
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
3、isnull
# Entry.objects.filter(pub_date__isnull=True) #双下划线isnull,查找pub_date是null的数据
4、contains #就是原生sql的like操作:模糊匹配
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
# models.Tb1.objects.exclude(name__icontains="ven")
5、range
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
6、order by
# models.Tb1.objects.filter(name='seven').order_by('id') # asc 没有减号升续排列
# models.Tb1.objects.filter(name='seven').order_by('-id') # desc 有减号升续排列
7、group by
# from django.db.models import Count, Min, Max, Sum
# models.Tb1.objects.filter(c1=1).values('id').annotate(c=Count('num')) #根据id列进行分组
# SELECT "app01_tb1"."id", COUNT("app01_tb1"."num") AS "c" FROM "app01_tb1"
# WHERE "app01_tb1"."c1" = 1 GROUP BY "app01_tb1"."id"
8、limit 、offset #分页
# models.Tb1.objects.all()[10:20]
9、regex正则匹配,iregex 不区分大小写
# Entry.objects.get(title__regex=r'^(An?|The) +')
# Entry.objects.get(title__iregex=r'^(an?|the) +') 10、date
# Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1)) #__data表示日期查找,2005-01-01
# Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1))
11、year
# Entry.objects.filter(pub_date__year=2005) #__year根据年查找
# Entry.objects.filter(pub_date__year__gte=2005)
12、month
# Entry.objects.filter(pub_date__month=12)
# Entry.objects.filter(pub_date__month__gte=6)
13、day
# Entry.objects.filter(pub_date__day=3)
# Entry.objects.filter(pub_date__day__gte=3)
14、week_day
# Entry.objects.filter(pub_date__week_day=2)
# Entry.objects.filter(pub_date__week_day__gte=2)
15、hour
# Event.objects.filter(timestamp__hour=23)
# Event.objects.filter(time__hour=5)
# Event.objects.filter(timestamp__hour__gte=12)
16、minute
# Event.objects.filter(timestamp__minute=29)
# Event.objects.filter(time__minute=46)
# Event.objects.filter(timestamp__minute__gte=29)
17、second
# Event.objects.filter(timestamp__second=31)
# Event.objects.filter(time__second=2)
# Event.objects.filter(timestamp__second__gte=31)
进阶操作:牛掰掰的双下划线
from django.utils import timezone
from report.models import * now = timezone.now()
# start_time = now - timezone.timedelta(days=7)
start_time = now - timezone.timedelta(hours=240) # 查询10天前的数据
end_time = now qs = AllClarm.objects.filter(start_tm__range=(start_time, end_time))
根据天/小时进行过滤
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from django.db import models
from django.shortcuts import render, get_object_or_404 class SLAGroup(models.Model):
name = models.CharField(max_length=100, verbose_name='组名')
weight = models.FloatField(verbose_name='权重')
description = models.CharField(max_length=255, verbose_name='描述', null=True, blank=True) group = get_object_or_404(SLAGroup, id=1) # 查询id=1的数据,否则就显示404页面
SLAGroup.objects.get_or_create(name='hadoop',weight='') # 获取或创建
get_object_or_404获取或返回404页面
1.6 Model性能相关操作:select_related、prefetch_related返回顶部
1、普通查询的缺点
1. 例:现在有两张表user,和group两张表,在user表中使用m作为ForeignKey与group表进行一对多关联
2. 如果通过user表中的实例查找对应的group表中的数据,就必须重复发sql请求
3. prefetch_related()和select_related()的设计目,都是为了减少SQL查询的数量,但是实现的方式不一样
2、select_related作用
1. select_related主要针一对一和多对一关系进行优化。
2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
3、prefetch_related()作用
1. prefetch_related()主要对于多对多字段和一对多字段进行优化
2. 进行两次sql查询,将查询结果拼接成一张表放到内存中,再查询就不用发sql请求
4、select_related与prefetch_related 使用原则
1. prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样
2. 因为select_related()总是在单次SQL查询中解决问题,而prefetch_related()会对每个相关表进行SQL查询,因此select_related()的效率高
3. 所以尽可能的用select_related()解决问题。只有在select_related()不能解决问题的时候再去想prefetch_related()。
5、select_related举例说明
作用:使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化
def index(request):
#1 这种方法低效
users = models.User.objects.all() #拿到的仅仅是user表中内容
for row in users:
print(row.user,row.ut_id) #这里打印user表中的内容不必再次sql请求
print(row.ut.name) #第一次查表,没有拿到关联表ut字段中的内容
#所以每次循环都会再次发sql请求,拿到ut.name的值,低效 #2 使用这种方法也仅需要一次数据库查询(拿到的是字典),但是如果查找的不在那些字段中直接报错
users = models.User.objects.all().values('user','pwd','ut__name') #3 select_related()可以一次sql查询拿到所有关联表信息
users = models.User.objects.all().select_related() # 这里还支持指定只拿到那个关联表的所有信息,比如:有多个外键关联,只拿到与ut外键关联的表
users = models.User.objects.all().select_related('ut') # select_related() 接受depth参数,depth参数可以确定select_related的深度。
# Django会递归遍历指定深度内的所有的OneToOneField和ForeignKey。以本例说明:
# zhangs = Person.objects.select_related(depth = d)
# d=1 相当于 select_related(‘hometown’,'living’)
# d=2 相当于 select_related(‘hometown__province’,'living__province’)
select_related举例说明
6、prefetch_related举例说明
作用:进行两次sql查询,将查询结果拼接成一张表
def index(request):
users = models.User.objects.filter(id__gt=30).prefetch_related('ut')
#ut和tu是user表的两个foreign key,分别关联不同的表 users = models.User.objects.filter(id__gt=30).prefetch_related('ut','tu')
#1 先执行第一次sql查询:select * from users where id > 30;
#2 比如:第一次查询结果,获取上一步骤中所有ut_id=[1,2]
#3 然后执行第二次sql查询:select * from user_type where id in [1,2]
#4 这样就仅执行了两次sql查询将两个表的数据拼到一起,放到内存中,再查询就不用发sql请求
for row in users:
print(row.user,row.ut_id) #这里打印user表中的内容不必再次sql请求
prefetch_related举例说明
1.7 F()和Q()查询语句返回顶部
from django.db import models
class Student(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
def __str__(self):
return self.name
models.py创建表
1、F() ---- 专门取对象中某列值的操作
作用:F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用
from django.shortcuts import HttpResponse
from app01 import models
from django.db.models import F,Q def orm(request):
# 每访问一次数据库中zhangsan的年纪就会自动增加1 models.Student.objects.filter(name='zhangsan').update(age=F("age") + 1) # 自动生成Student表中数据
'''
stu_list = [{'name':'zhangsan','age':11},
{'name': 'lisi', 'age': 22},
{'name': 'wangwu', 'age': 33},]
for u in stu_list:
models.Student.objects.create(**u)
'''
return HttpResponse('orm')
F()将指定字段自动加1
2.1、Q() ---- 复杂查询(用法1)
1、Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询
2、可以组合使用 &(and),|(or),~(not)操作符,当一个操作符用于两个Q的对象,它产生一个新的Q对象
3、如: Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption='root')
from django.shortcuts import HttpResponse
from app01 import models
from django.db.models import F,Q def orm(request):
# 查找学生表中年级大于1小于30姓zhang的所有学生
stus = models.Student.objects.filter(
Q(age__gt=1) & Q(age__lt=30),
Q(name__startswith='zhang')
)
print('stu',stus) #运行结果:[<Student: zhangsan>] # 自动生成Student表中数据
'''
stu_list = [{'name':'zhangsan','age':11},
{'name': 'lisi', 'age': 22},
{'name': 'wangwu', 'age': 33},]
for u in stu_list:
models.Student.objects.create(**u)
'''
return HttpResponse('orm')
复杂查询
2.2、Q() ---- 动态添加多个and和or查询条件(用法2)
def table_search(request,admin_class,object_list):
search_key = request.GET.get('_q','')
q_obj = Q()
q_obj.connector = 'OR'
for column in admin_class.search_fields:
q_obj.children.append(('%s__contains'%column,search_key))
res = object_list.filter(q_obj)
return res
crm项目中动态添加or查询条件
# or动态添加多个查询条件
>>> from crm import models
>>> from django.db.models import Q
>>> con = Q() #1. 实例化一个Q()查询类
>>> con.connector = "OR" #2. 指定使用‘OR’条件
>>> con.children.append(('qq__contains','')) #3. qq字段中包含‘123’
>>> con.children.append(('name__contains','name0')) #4. name字段中包含‘naem0’
>>> con
<Q: (OR: ('qq__contains', ''), ('name__contains', 'name0'))>
#5. 查找name字段中包含‘naem0’或qq字段包含‘123’的所有条目
>>> models.Customer.objects.values('qq','name').filter(con)
or动态添加多个查询条件
# and和or结合查询
#1. 导入模块
>>> from crm import models
>>> from django.db.models import Q #2. q1:查询id=1或者id=2的所有条目 (or条件)
>>> q1 = Q()
>>> q1.connector = 'OR'
>>> q1.children.append(('id',1))
>>> q1.children.append(('id',2)) #3. q2:查询id=1的所有条目 (or条件)
>>> q2 = Q()
>>> q2.connector = 'OR'
>>> q2.children.append(('id',1)) #4. con:结合q1和q2条件结果是查询id=1的所有条目 (结合q1,q2的and条件)
>>> con = Q()
>>> con.add(q1,'AND')
<Q: (OR: ('id', 1), ('id', 2))>
>>> con.add(q2,'AND')
<Q: (AND: (OR: ('id', 1), ('id', 2)), ('id', 1))>
>>> models.Customer.objects.values('qq','name').filter(con)
<QuerySet [{'qq': '', 'name': 'haha'}]>
and和or结合查询
1.8 aggregate和annotate聚合函数 : 求平均值、最大值、最小值等返回顶部
1、aggregate聚合函数
作用:从数据库中取出一个汇总的集合
from django.db.models import Count,Avg,Max,Sum
def orm(request): stus = models.Student.objects.aggregate(
stu_num=Count('age'), #计算学生表中有多少条age条目
stu_avg=Avg('age'), #计算学生的平均年纪
stu_max=Max('age'), #找到年纪最大的学生
stu_sum=Sum('age')) #将表中的所有年纪相加 print('stu',stus)
return HttpResponse('ok')
#运行结果:{'stu_sum': 69, 'stu_max': 24, 'stu_avg': 23.0, 'stu_num': 3}
aggregate求最大值、最小值、平局值等
2、annotate实现聚合group by查询
作用:对查询结果进行分组,比如分组求出各年龄段的人数
注: annotate后面加filter过滤相当于原生sql语句中的having
from django.db.models import Count, Avg, Max, Min, Sum
def orm(request):
#1 按年纪分组查找学生表中各个年龄段学生人数:(22岁两人,24岁一人)
# 查询结果:[{'stu_num': 2, 'age': 22}, {'stu_num': 1, 'age': 24}] stus1 = models.Student.objects.values('age').annotate(stu_num=Count('age')) #2 按年纪分组查找学生表中各个年龄段学生人数,并过滤出年纪大于22的:
# 查询结果:[{'stu_num': 1, 'age': 24}] (年级大于22岁的仅一人,年级为24岁) stus2 = models.Student.objects.values('age').annotate(stu_num=Count('age')).filter(age__gt=22) #3 先按年纪分组,然后查询出各个年龄段学生的平均成绩
# 查询结果:[{'stu_Avg': 86.5, 'age': 22}, {'stu_Avg': 99.0, 'age': 24}]
# 22岁平均成绩:86.5 24岁平均成绩:99 stus3 = models.Student.objects.values('age').annotate(stu_Avg=Avg('grade')) return HttpResponse('ok')
annotate实现聚合group by查询
3、aggregate和annotate区别
1. Aggregate作用是从数据库取出一个汇总的数据(比如,数量,最大,最小,平均等)
2. 而annotate是先按照设定的条件对数据进行分组,然后根据不同组分别对数据进行汇总
1.9 Trunc函数处理日期格式数据返回顶部
1、Trunc函数作用 及 参数说明
1、作用:Trunk可以将时间处理成,只有年,或月或日等格式,那些不关心的部分都会变成0
2、Trunk函数可以传入下面四个参数:
a、expression :传入数据库表中对应要处理的时间那个字段名字
b、kind :是时间格式的一部分,可以是 year,month,day,hour,minute,second
,kind指定最后处理后的时间精确到哪一个部分
c、output_field :只能是这三个格式:DateTimeField(), TimeField(), or DateField()
最后返回的是datetime,date,或则time 就取决于 output_field 字段是如何指定的
d、tzinfosubclass:通常由pytz提供,可以传递给截断值指定一个特定的时区。
3、如果给出的时间是 datetime 2015-06-15 14:30:50.000321+00:00, 使用下面六种 kinds 最后返回结果如下
“year”: 2015-01-01 00:00:00+00:00
“month”: 2015-06-01 00:00:00+00:00
“day”: 2015-06-15 00:00:00+00:00
“hour”: 2015-06-15 14:00:00+00:00
“minute”: 2015-06-15 14:30:00+00:00
“second”: 2015-06-15 14:30:50+00:00
2、解决时差配置问题的报错
1. 错误:Are time zone definitions for your database and pytz installed?
2. 解决方法:安装pytz模块,在Django settings中配置数据库的时区: pip3 install pytz
# 注释的是数据库默认的配置
# LANGUAGE_CODE = 'en-us'
# TIME_ZONE = 'UTC'
# USE_TZ = True USE_TZ = False
LANGUAGE_CODE = 'zh-Hans'
TIME_ZONE = 'Asia/Chongqing'
在settings中配置数据库时区
3、Trunk函数基本使用
from django.db import models class Experiment(models.Model):
start_datetime = models.DateTimeField()
models.py中创建数据库表
from django.shortcuts import HttpResponse
from .models import * from datetime import datetime
from django.db.models import Count, DateTimeField
from django.db.models.functions import Trunc def orm(request):
#1 首先向Experiment表中插入三条数据
Experiment.objects.create(start_datetime=datetime(2015, 6, 15, 14, 30, 50, 321))
Experiment.objects.create(start_datetime=datetime(2015, 6, 15, 14, 40, 2, 123))
Experiment.objects.create(start_datetime=datetime(2015, 12, 25, 10, 5, 27, 999)) #2 使用Trunk过滤出start_datetime字段,仅保存到日,后面的时分秒全部变成0
#3 annotate(experiments=Count('id'))可以根据天进行分组 experiments_per_day = Experiment.objects.annotate(
start_day=Trunc('start_datetime', 'day', output_field=DateTimeField())
).values('start_day').annotate(experiments=Count('id')) for exp in experiments_per_day:
print(exp['start_day'], exp['experiments'])
return HttpResponse('orm')
# 运行结果:
# 2015-06-15 00:00:00+00:00 2
# 2015-12-25 00:00:00+00:00 1
# 从运行结果中可以看出,2015-06-15日有两条记录,2015-12-25日有1条记录
views.py使用
4、Trunk函数应用:查询当天签到同学的id
def attendance(request):
"""签到页面"""
current_datetime = datetime.now()
year = current_datetime.year
month = current_datetime.month
day = current_datetime.day
if request.method == 'GET':
if course_id:
# 获取当天已签到的记录
attended_students = models.Attendance.objects.annotate(
attend_day=functions.Trunc('attend_time','day',output_field=DateTimeField(), )
).filter(attend_day=datetime(year, month, day), course_id=course_id).values_list('student_id', flat=True) #Trunc函数的作用是将'attend_time'中的时间过滤成“day”: 2015-06-15 00:00:00+00:00 这种格式 tt = datetime(2016, 3, 12) #运行结果:2016-03-12 00:00:00 # 运行结果: <QuerySet [1, 2]> #这里的1,2 是数字表示当天只有id=1,和2的学生签到 # 注:使用这个查询语法和上面的查询结果完全一样
attended_students = models.Attendance.objects\
.filter(attend_time__date=datetime(year, month, day),course_id=course_id)\
.values_list('student_id', flat=True)
trunk函数应用
1.10 Django其他查询语句返回顶部
1、extra构造额外的查询条件或者映射,如:子查询
1. extra作用
1、extra 中可实现别名,条件,排序等
2、后面两个用 filter, exclude 一般都能实现,排序用 order_by 也能实现
2. extra条件查询
def extra(self, select=None, where=None, params=None,tables=None, order_by=None, select_params=None):
#1 select参数操作
Entry.objects.extra(select=
{'new_id': "select col from sometable where othercol = %s"},
select_params=(1,))
Entry.objects.extra(select={'new_id': "func(id)"}) #也可以定义函数处理
# %s就会替换成1了 Entry.objects.extra(select={'new_id': "select id from tb where id > %s"},
select_params=(1,), order_by=['-nid'])
#2 where参数操作
Entry.objects.extra(where=['headline=%s'], params=['Lennon']) # 类似filter过滤
Entry.objects.extra(where=['headline=%s','nid>1'], params=['Lennon']) # and操作
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) #or操作
Entry.objects.extra(where=['func(ctime)=1 or nid=1']) #在这里也可以传入MySQL的函数
extra条件查询
3. extra实现别名
from django.db.models import Count, Avg, Max, Min, Sum
def orm(request):
#1、extra 中可实现别名
tags = models.Student.objects.filter(name='zhangsan')\
.extra(select={'tag_name': 'name'}).first()
print('name:',tags.name) # name: zhangsan
print('tag_name:',tags.tag_name) # tag_name: zhangsan
return HttpResponse('ok')
extra实现别名
02:django model数据库操作的更多相关文章
- 03: Django Model数据库操作
目录:Django其他篇 01:Django基础篇 02:Django进阶篇 03:Django数据库操作--->Model 04: Form 验证用户数据 & 生成html 05:Mo ...
- Django 2.0 学习(16):Django ORM 数据库操作(下)
Django ORM数据库操作(下) 一.增加表记录 对于表单有两种方式: # 方式一:实例化对象就是一条表记录france_obj = models.Student(name="海地&qu ...
- Django 2.0 学习(14):Django ORM 数据库操作(上)
Django ORM 数据库操作(上) ORM介绍 映射关系: 数据库表名 ---------->类名:数据库字段 ---------->类属性:数据库表一行数据 ----------&g ...
- django models 数据库操作
django models 数据库操作 创建模型 实例代码如下 from django.db import models class School(models.Model): pass class ...
- Django与数据库操作
Django与数据库操作 数据库连接的方法 web 框架 django --- 自己内部实现 (ORM) + pymysql(连接) Flask,tornado --- pymysql SQLArch ...
- Django模型-数据库操作
前言 前边记录的URLconf和Django模板全都是介绍页面展示的东西,也就是表现层的内容.由于Python先天具备简单而强大的数据库查询执行方法,Django 非常适合开发数据库驱动网站. 这篇开 ...
- django models数据库操作
一.数据库操作 1.创建model表 基本结构 1 2 3 4 5 6 from django.db import models class userinfo(models.M ...
- Django Model基础操作
关于设计django model django为我们集成了ORM对数据库进行操作,我们只需要进行定义model,django就会自动为我们创建表,以及表之间的关联关系 创建好一个django项目-首先 ...
- django 快速数据库操作,不用SQL语句
配置models文件 # -*- coding: utf-8 -*- from __future__ import unicode_literals from django.db import mod ...
随机推荐
- 对promise.all底层的实现的研究
1.Promise.all(iterable)返回一个新的Promise实例,此实例在iterable参数内素有的Promise都fulfilled或者参数中不包含Promise时,状态变成fulfi ...
- linux常用的命令一:系统工作命令
系统工作命令: 帮助命令:man -h \ man --help(tips:‘--’长格式后用完整的选项名称,‘-’短格式后用单个字母缩写) echo命令:格式:echo [字符串|$变量] date ...
- SQL 以逗号分隔查询;调用自定义函数
select col from [dbo].[GetInPara]('101,102,103',',') USE [xxx] GO /****** Object: UserDefinedFunctio ...
- ps -aux显示信息COMMAND不全
ps -aux结果: ps -auxwww结果:
- navicat安装与激活
原文网址:https://www.jianshu.com/p/5f693b4c9468?mType=Group 一.Navicat Premium 12下载 Navicat Premium 12是一套 ...
- [CF1093G]Multidimensional Queries:线段树
分析 非常有趣的一道题. 式子中的绝对值很难处理,但是我们发现: \[\sum_{i=1}^{k}|a_{x,i}-a_{y,i}|=\sum_{i=1}^{k}max(a_{x,i}-a_{y,i} ...
- OI常用的常数优化小技巧
注意:本文所介绍的优化并不是算法上的优化,那个就非常复杂了,不同题目有不同的优化.笔者要说的只是一些实用的常数优化小技巧,很简单,虽然效果可能不那么明显,但在对时间复杂度要求十分苛刻的时候,这些小的优 ...
- [BZOJ2729]:[HNOI2012]排队(组合数学)
题目传送门 题目描述 某中学有n名男同学,m名女同学和两名老师要排队参加体检.他们排成一条直线,并且任意两名女同学不能相邻,两名老师也不能相邻,那么一共有多少种排法呢?(注意:任意两个人都是不同的) ...
- 一款基于CSS3漂亮的按钮
特别提示:本人博客部分有参考网络其他博客,但均是本人亲手编写过并验证通过.如发现博客有错误,请及时提出以免误导其他人,谢谢!欢迎转载,但记得标明文章出处:http://www.cnblogs.com/ ...
- modern php笔记---php (性状)
modern php笔记---php (性状) 一.总结 一句话总结: trait是和继承一个层次的东西 一个类use MyTrait;后,trait中的方法覆盖父类方法,当前类中的方法覆盖trait ...