Intel MKL函数之 cblas_sgemm、cblas_sgemm_batch
cblas_sgemm
int m = 40;
int k = 20;
int n = 40;
std::vector<float> a(m*k, 1.0);
std::vector<float> b(k*n, 1.0);
std::vector<float> c(m*n, 0.0);
float alpha = 1.0;
float beta = 0.0;
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha,
a.data(), k,
b.data(), n, beta,
c.data(), n);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % k == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % n == 0)
std::cout << std::endl;
}
std::cout << "c.size(): " << c.size() << std::endl;
for (int i = 0; i < c.size(); ++i) {
std::cout << c[i] << " ";
if ((i + 1) % n == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 40 * 20 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 1600 (40 * 40)
20 20 ... 20 20
...
20 20 ... 20 20
cblas_sgemm_batch

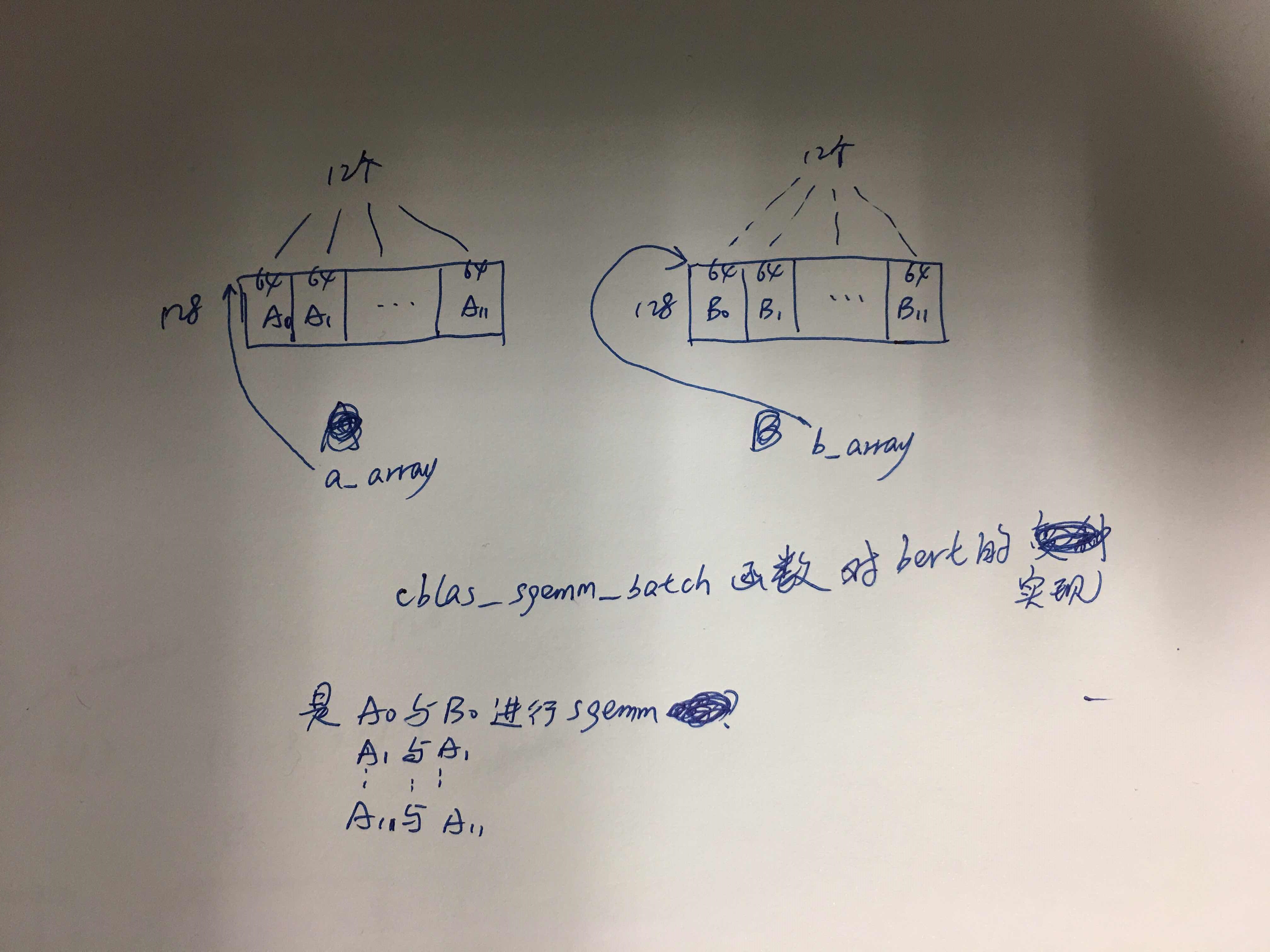
int raw_rows = 20;
int raw_cols = 40;
std::vector<float> a(raw_rows * raw_cols, 1.0);
std::vector<float> b(raw_rows * raw_cols, 1.0);
std::vector<float> c(1600, 0.0);
#define GRP_COUNT 1
MKL_INT m[GRP_COUNT] = {20};
MKL_INT k[GRP_COUNT] = {10};
MKL_INT n[GRP_COUNT] = {20};
MKL_INT lda[GRP_COUNT] = {40};
MKL_INT ldb[GRP_COUNT] = {40};
MKL_INT ldc[GRP_COUNT] = {80};
CBLAS_TRANSPOSE transA[GRP_COUNT] = { CblasNoTrans };
CBLAS_TRANSPOSE transB[GRP_COUNT] = { CblasTrans };
float alpha[GRP_COUNT] = {1.0};
float beta[GRP_COUNT] = {0.0};
const MKL_INT size_per_grp[GRP_COUNT] = {4};
const float *a_array[4], *b_array[4];
float *c_array[4];
for (int i = 0; i < 4; ++i) {
a_array[i] = a.data() + i * 10;
b_array[i] = b.data() + i * 10;
c_array[i] = c.data() + i * 20;
}
cblas_sgemm_batch (CblasRowMajor, transA, transB,
m, n, k, alpha,
a_array, lda,
b_array, ldb, beta,
c_array, ldc,
GRP_COUNT, size_per_grp);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "c_array.size(): " << 20 * 20 * 4 << std::endl;
for (int i = 0; i < 1600; ++i) {
std::cout << c[i] << " ";
if ((i + 1) % 80 == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 1600 (40 * 40)
10 10 ... 10 10
...
10 10 ... 10 10
int raw_rows = 20;
int raw_cols = 40;
std::vector<float> a(raw_rows * raw_cols, 1.0);
std::vector<float> b(raw_rows * raw_cols, 1.0);
std::vector<float> c(400, 0.0);
#define GRP_COUNT 1
MKL_INT m[GRP_COUNT] = {5};
MKL_INT k[GRP_COUNT] = {10};
MKL_INT n[GRP_COUNT] = {5};
MKL_INT lda[GRP_COUNT] = {40};
MKL_INT ldb[GRP_COUNT] = {40};
MKL_INT ldc[GRP_COUNT] = {20};
CBLAS_TRANSPOSE transA[GRP_COUNT] = { CblasNoTrans };
CBLAS_TRANSPOSE transB[GRP_COUNT] = { CblasTrans };
float alpha[GRP_COUNT] = {1.0};
float beta[GRP_COUNT] = {0.0};
const MKL_INT size_per_grp[GRP_COUNT] = {16};
const float *a_array[16], *b_array[16];
float *c_array[16];
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
a_array[i*4+j] = a.data() + i * 5 * 40 + j * 10;
b_array[i*4+j] = b.data() + i * 5 * 40 + j * 10;
c_array[i*4+j] = c.data() + i * 5 * 20 + j * 5;
}
}
cblas_sgemm_batch (CblasRowMajor, transA, transB,
m, n, k, alpha,
a_array, lda,
b_array, ldb, beta,
c_array, ldc,
GRP_COUNT, size_per_grp);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "c_array.size(): " << 5 *5 * 16 << std::endl;
for (int i = 0; i < 400; ++i) {
std::cout << c[i] << " ";
if ((i + 1) % 20 == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 400 (20 * 20)
10 10 ... 10 10
...
10 10 ... 10 10
Intel MKL函数之 cblas_sgemm、cblas_sgemm_batch的更多相关文章
- Intel MKL函数,如何得到相同的计算结果?【转】
在运行程序时,我们总希望多次运行的结果,是完全一致,甚至在不同的机器与不同的OS中,程序运行的结果每一位都完全相同. 事实上,程序往往很难保证做到这一点. 为什么呢? 我们先看一个简单的例子: 当程序 ...
- Intel MKL 多线程设置
对于多核程序,多线程对于程序的性能至关重要. 下面,我们将对Intel MKL 有关多线程方面的设置做一些介绍: 我们提到MKL 支持多线程,它包括的两个概念:1>MKL 是线程安全的: MKL ...
- Intel MKL(Math Kernel Library)
1.Intel MKL简介 Intel数学核心函数库(MKL)是一套高度优化.线程安全的数学例程.函数,面向高性能的工程.科学与财务应用.英特尔 MKL 的集群版本包括 ScaLAPACK 与分布式内 ...
- BLAS 与 Intel MKL 数学库
0. BLAS BLAS(Basic Linear Algebra Subprograms)描述和定义线性代数运算的规范(specification),而不是一种具体实现,对其的实现包括: AMD C ...
- 【神经网络与深度学习】【C/C++】比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能
比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能 对于机器学习的很多问题来说,计算的瓶颈往往在于大规模以及频繁的矩阵运算,主要在于以下两方面: (Dense/Sparse) Matr ...
- Intel MKL FATAL ERROR: Cannot load mkl_intel_thread.dll
Intel MKL FATAL ERROR: Cannot load mkl_intel_thread.dll 在使用Anaconda创建一个虚拟环境出来,然后安装了scikit-learn.nump ...
- 遇到Intel MKL FATAL ERROR: Cannot load libmkl_avx2.so or libmkl_def.so问题的解决方法
运行一个基于tensorflow的模型时,遇到Intel MKL FATAL ERROR: Cannot load libmkl_avx2.so or libmkl_def.so问题. 解决方法:打开 ...
- ubuntu配置机器学习环境(四) 安装intel MKL
在这一模块可以选择(ATLAS,MKL或者OpenBLAS),我这里使用MKL,首先下载并安装英特尔® 数学内核库 Linux* 版MKL,下载链接, 请下载Student版,先申请,然后会立马收到一 ...
- 在NVIDIA(CUDA,CUBLAS)和Intel MKL上快速实现BERT推理
在NVIDIA(CUDA,CUBLAS)和Intel MKL上快速实现BERT推理 直接在NVIDIA(CUDA,CUBLAS)或Intel MKL上进行高度定制和优化的BERT推理,而无需tenso ...
随机推荐
- c++复习——类(2)
1.this指针 this指针是一个指向对象的指针. this指针是一个隐含于成员函数中的对象指针. this指针是一个指向正在调用成员函数的对象的指针. 类的静态成员函数没有this指针 ...
- python list 插入元素
https://www.jb51.net/article/57923.htm List 是 Python 中常用的数据类型,它一个有序集合,即其中的元素始终保持着初始时的定义的顺序(除非你对它们进行排 ...
- CF1019E Raining season
https://www.luogu.org/problemnew/show/CF1019E 题解 \[ dis=day*a+b \] \[ b=-day*a+dis \] 然后就变成了斜率优化. 考虑 ...
- [洛谷P5106]dkw的lcm:欧拉函数+容斥原理+扩展欧拉定理
分析 考虑使用欧拉函数的计算公式化简原式,因为有: \[lcm(i_1,i_2,...,i_k)=p_1^{q_{1\ max}} \times p_2^{q_{2\ max}} \times ... ...
- Linux内核调试方法总结之dumpsys
dumpsys [用途]Android系统提供的dumpsys工具可以用来查看系统服务信息与状态. [使用说明] adb shell dumpsys <service> [<opti ...
- ORACLE内存管理之ASMM AMM
ORACLE ASMM ORACLE AMM ASMM转换至AMM AMM转换至ASMM
- MySQL主从复制之异步模式
MySQL主从复制有异步模式.半同步模式.GTID模式以及多源复制模式,MySQL默认模式是异步模式.所谓异步模式,只MySQL 主服务器上I/O thread 线程将二进制日志写入binlog文件之 ...
- flask_sqlalchemy和sqlalchemy的区别有哪些?
概要的说: SQLAlchemy是python社区使用最广泛的ORM之一,SQL-Alchmy直译过来就是SQL炼金术. Flask-SQLAlchemy集成了SQLAlchemy,它简化了连接数据库 ...
- python监控ip攻击,服务器防火墙
'''写一个程序,监控nginx的日志,如果有人攻击就加入黑名单 把ip加入黑名单的策略是,1分钟之内,如果同一个ip请求超过200次,那就加入黑名单''' '''分析:1.打开文件 2.循环读取 3 ...
- Newtonsoft.Json源码中的C#预处理指令
cs文件中包含以指令: #if !(NET35 || NET20 || PORTABLE40) 记事本打开[Newtonsoft.Json.Net20.csproj]可看到以下代码: <Defi ...