simhash文本相似度比较
simhash
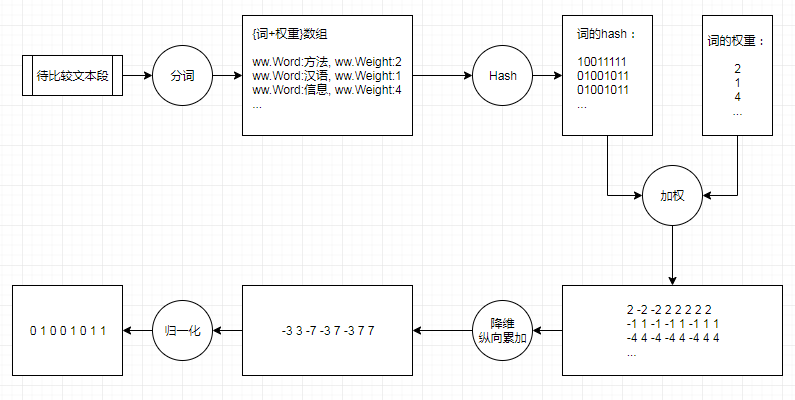
在simhash中处理一个文本的步骤如下:
第一步,分词:
对文本进行分词操作,同时需要我们同时返回当前词组在文本内容中的权重(这基本上是目前所有分词工具都支持的功能)。
第二步,计算hash:
对于每一个得到的词组做hash,将词语表示为到01表示的bit位,需要保证每个hash结果的位数相同,如图中所示,使用的是8bit。
第三步,加权
根据每个词组对应的权重,对hash值做加权计算(bit为1则取为1做乘积,bit为0则取为-1做乘积),如上图中,
10011111与权重2加权得到[2 -2 -2 2 2 2 2 2];
01001011与权重1加权得到[-1 1 -1 -1 1 -1 1 1];
01001011与权重4加权后得到[-4 4 -4 -4 4 -4 4 4];
第三步,纵向相加:
将上述得到的加权向量结果,进行纵向相加实现降维,如上述所示,得到[-3 3 -7 -3 7 -3 7 7]。
第四步,归一化:
将最终降维向量,对于每一位大于0则取为1,否则取为0,这样就能得到最终的simhash的指纹签名[0 1 0 0 1 0 1 1]
第五步,相似度比较:
通过上面的步骤,我们可以利用SimHash算法为每一个网页生成一个向量指纹,在simhash中,判断2篇文本的相似性使用的是海明距离。什么是汉明距离?前文已经介绍过了。在在经验数据上,我们多认为两个文本的汉明距离<=3的话则认定是相似的。
// 载入模块
const Segment = require('segment');
const fnv = require('fnv-plus');
// 创建实例
const segment = new Segment();
// 使用默认的识别模块及字典,载入字典文件需要1秒,仅初始化时执行一次即可
segment.useDefault();
// 开始分词
// console.log(segment.doSegment('这是一个基于Node.js的中文分词模块。'));
function createSimhash(keyword){
//1.对内容进行分词
const result = segment.doSegment(keyword, {
stripPunctuation: true,
simple: true
});
//2.用keyMap来存储分词及对应的权值
const keyMap = new Map();
//3.默认权值都是1,重复的权重在加1
result.map(function (key) {
if (keyMap.has(key)) {
keyMap.set(key, keyMap.get(key) + 1)
} else {
keyMap.set(key, 1)
}
})
const hashMap = new Map();
keyMap.forEach(function (value, key, map) {
let hash64 = fnv.hash(key, 64);
//3.对每个key计算其hash值
let currenthash = parseInt('0x' + hash64.hex()).toString(2).padStart(64,'0')
//4.遍历hash值,对hash值进行权值操作
for (let i = 0; i < currenthash.length; i++) {
let v1 = parseInt(currenthash[i]);
let v2;
//根据计算规则遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘
if (v1 > 0) {
v2 = 1 * value;
} else {
v2 = value * (-1);
}
//5.边加权边合并
if (hashMap.has(i)) {
hashMap.set(i, hashMap.get(i) + v2);
} else {
hashMap.set(i, v2);
}
}
});
let s1 = "";
//6.降维,归一化
for (let i = 0; i < 64; i++) {
let v1 = hashMap.get(i);
if (v1 > 0) {
hashMap.set(i, 1)
} else {
hashMap.set(i, 0)
}
s1 = s1 + hashMap.get(i);
}
return s1;
}
let hash1 = createSimhash(`关于区块链和数字货币的关系,很多人或多或少都存在疑惑。简单来说,区块链是比特币的底层运用,而比特币只是区块链的一个小应用而已。
数字货币即虚拟货币,最早的数字货币诞生于2009年,其发明者中本聪为了应对经济危机对于实体货币经济的冲击。比特币是最早的数字货币,后来出现了以太币、火币以及莱特币等虚拟货币,这些虚拟货币是不能用来交易的。
狭义来讲,区块链是一种按照时间顺序将数据区块以顺序相连的方式组合成的一种链式数据结构, 并以密码学方式保证的不可篡改和不可伪造的分布式账本。
广义来讲,区块链技术是利用块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新数据、利用密码学的方式保证数据传输和访问的安全、利用由自动化脚本代码组成的智能合约来编程和操作数据的一种全新的分布式基础架构与计算方式。
`);
let hash2 = createSimhash(`区块链技术为我们的信息防伪与数据追踪提供了革新手段。区块链中的数据区块顺序相连构成了一个不可篡改的数据链条,时间戳为所有的交易行为贴上了一套不讲课伪造的真是标签,这对于人们在现实生活中打击假冒伪劣产品大有裨益;
市场分析指出,整体而言,区块链技术目前在十大金融领域显示出应用前景,分别是资产证券化、保险、供应链金融、场外市场、资产托管、大宗商品交易、风险信息共享机制、贸易融资、银团贷款、股权交易交割。
这些金融场景有三大共性:参与节点多、验真成本高、交易流程长,而区块链的分布式记账、不可篡改、内置合约等特性可以为这些金融业务中的痛点提供解决方案。
传统的工业互联网模式是由一个中心化的机构收集和管理所有的数据信息,容易产生因设备生命周期和安全等方面的缺陷引起的数据丢失、篡改等问题。区块链技术可以在无需任何信任单个节点的同时构建整个网络的信任共识,从而很好的解决目前工业互联网技术领域的一些缺陷,让物与物之间能够实现更好的连接。`)
let hash3 = createSimhash(`沉默螺旋模式中呈现出民意动力的来源在于人类有害怕孤立的弱点,但光害怕孤立不至于影响民意的形成,
主要是当个人觉察到自己对某论题的意见与环境中的强势意见一致(或不一致时),害怕孤立这个变项才会产生作用。
从心理学的范畴来看,社会中的强势意见越来越强,甚至比实际情形还强,弱势意见越来越弱,甚至比实际情形还弱,这种动力运作的过程成–螺旋状`);
let hash4 = createSimhash(`从心理学的范畴来看,害怕孤立这个变项才会产生作用。社会中的强势意见越来越强,甚至比实际情形还强,弱势意见越来越弱,
主要是当个人觉察到自己对某论题的意见与环境中的强势意见一致(或不一致时),甚至比实际情形还弱,这种动力运作的过程成–螺旋状
但光害怕孤立不至于影响民意的形成,沉默螺旋模式中呈现出民意动力的来源在于人类有害怕孤立的弱点`)
function getDistance(hash1, hash2) {
let length = hash1.length > hash2.length ? hash2.length : hash1.length;
let distance = 0;
for (let i = 0; i < length; i++) {
if (hash1[i] !== hash2[i]) {
distance = distance + 1;
}
}
return distance;
}
console.log(getDistance(hash1,hash2))
console.log(getDistance(hash3,hash4))
simhash文本相似度比较的更多相关文章
- 从0到1,了解NLP中的文本相似度
本文由云+社区发表 作者:netkiddy 导语 AI在2018年应该是互联网界最火的名词,没有之一.时间来到了9102年,也是项目相关,涉及到了一些AI写作相关的功能,为客户生成一些素材文章.但是, ...
- NLP点滴——文本相似度
[TOC] 前言 在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性.而有了文本之间相似性的度 ...
- 【NLP】Python实例:基于文本相似度对申报项目进行查重设计
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- TF-IDF 文本相似度分析
前阵子做了一些IT opreation analysis的research,从产线上取了一些J2EE server运行状态的数据(CPU,Menory...),打算通过训练JVM的数据来建立分类模型, ...
- 文本相似度算法——空间向量模型的余弦算法和TF-IDF
1.信息检索中的重要发明TF-IDF TF-IDF是一种统计方法,TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分 ...
- 【机器学习】使用gensim 的 doc2vec 实现文本相似度检测
环境 Python3, gensim,jieba,numpy ,pandas 原理:文章转成向量,然后在计算两个向量的余弦值. Gensim gensim是一个python的自然语言处理库,能够将文档 ...
- 文本离散表示(三):TF-IDF结合n-gram进行关键词提取和文本相似度分析
这是文本离散表示的第二篇实战文章,要做的是运用TF-IDF算法结合n-gram,求几篇文档的TF-IDF矩阵,然后提取出各篇文档的关键词,并计算各篇文档之间的余弦距离,分析其相似度. TF-IDF与n ...
- C# 比较两文本相似度
这个比较文本用到的主要是余弦定理比较文本相似度,具体原理右转某度,主要适用场景是在考试系统中的简答题概述,可根据权重自动打分,感觉实用性蛮广的. 先说下思路: 文本分词,中文于英文不同,规范的英文每个 ...
- NLP文本相似度
NLP文本相似度 相似度 相似度度量:计算个体间相似程度 相似度值越小,距离越大,相似度值越大,距离越小 最常用--余弦相似度: 一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小 余 ...
随机推荐
- 扩展欧几里得算法详解(exgcd)
一.前言 本博客适合已经学会欧几里得算法的人食用~~~ 二.扩展欧几里得算法 为了更好的理解扩展欧几里得算法,首先你要知道一个叫做贝祖定理的玄学定理: 即如果a.b是整数,那么一定存在整数x.y使得$ ...
- TimeUnit类 java.util.concurrent.TimeUnit
TimeUnit是什么? TimeUnit是java.util.concurrent包下面的一个类,表示给定单元粒度的时间段 主要作用 时间颗粒度转换 延时 常用的颗粒度 TimeUnit.DAYS ...
- C# DataTable 去重复数据方法
//获取dt中Id,Value 2个字段不重复的数据 newDt = dt.DefaultView.ToTable(true, "Id","Value" );
- spark复习笔记(4):spark脚本分析
1.[start-all.sh] #!/usr/bin/env bash # # Licensed to the Apache Software Foundation (ASF) under one ...
- .NetCore模拟Postman的BasicAuth生成Authrization
一.思路 BasicAuth 是一种简单权限,传输UserName=<userName>,Password=<password> 1.用:连接Username,Password ...
- 【转】SIP协议 会话发起协议
转自:https://www.cnblogs.com/gardenofhu/p/7299963.html 会话发起协议(SIP)是VoIP技术中最常用的协议之一.它是一种应用层协议,与其他应用层协议协 ...
- opencv windows源码编译
WITH_QT//H:\software\programming\qt\5.12.3\mingw73_32\lib\cmake 5.6的路径要改这样 WITH_OPENGL 编译器mingw32-m ...
- RabbitMQ拓展学习 自定义配置RabbitMQ连接属性
最近研究RabbitMQ从本地获取配置,主要场景是RabbitMQ的连接配置如:ip地址这些需要从外部的配置服务器获取.面对这个问题,有两个解决方案,一个是用RabbitMQ原生的连接方式,但是如果使 ...
- CSS3 nth-of-type(n)选择器 last-of-type选择器 nth-last-of-type(n)选择器 CSS3 only-child选择器 only-of-type选择器
CSS3 nth-of-type(n)选择器 “:nth-of-type(n)”选择器和“:nth-child(n)”选择器非常类似,不同的是它只计算父元素中指定的某种类型的子元素.当某个元素中的子元 ...
- W3C 事件切换 颜色变化
颜色变化代码: HTML: <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...